5 patterns for graph-enhanced RAG in production
5 graph-RAG patterns show when SQL, vectors, and graphs work together to answer risk and dependency questions.
Graph-enhanced RAG adds relationship-aware retrieval to production AI systems.
When your data mixes tables, documents, and dependencies, plain vector search can miss the connection that matters. This list shows five production-ready patterns for graph-enhanced RAG, using one concrete example: a SQL record says Supplier A provides Component X to Factory Y, while a news report says flooding in Thailand halted Supplier A’s facility.
| Item | Best for | Core strength |
|---|---|---|
| 1. Entity graph first | Known people, suppliers, assets | Connects named things across sources |
| 2. Vector-only retrieval | Loose semantic search | Finds relevant text fast |
| 3. Graph + vector hybrid | Mixed structured and unstructured data | Balances meaning with relationships |
| 4. Hop-based expansion | Dependency and risk tracing | Follows links beyond the first match |
| 5. Query-time reasoning layer | Complex business questions | Ranks evidence before answering |
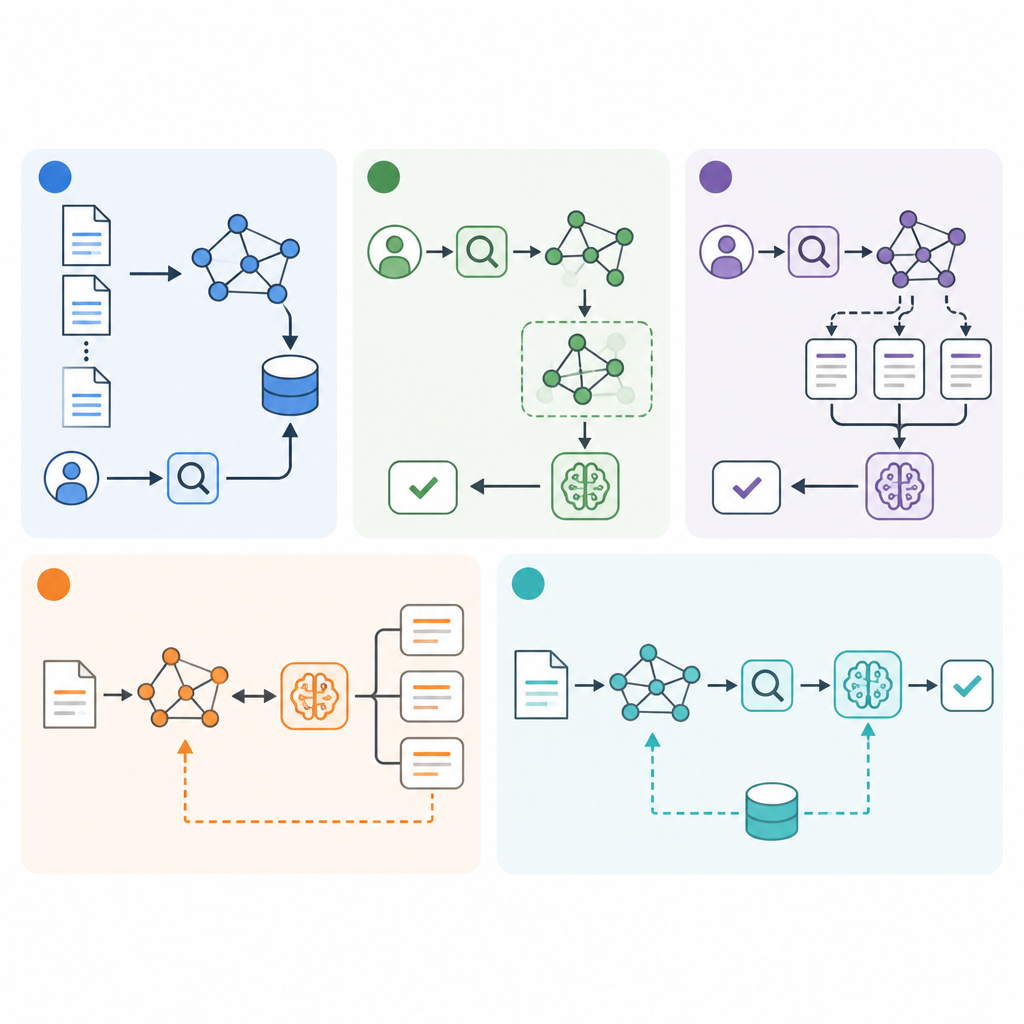
1. Entity graph first
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
An entity-first graph is the cleanest way to represent who, what, and where before you add retrieval logic. In the example, Supplier A, Component X, Factory Y, and Thailand become nodes, while “provides,” “located in,” and “halted by” become edges.
This pattern works well when your organization already has master data, identifiers, or a knowledge graph team. It gives downstream systems a stable backbone, so the model can ask not just “what text looks similar,” but “what is actually connected.”
- Use it for suppliers, products, facilities, customers, and incidents.
- Keep IDs stable across SQL, documents, and event streams.
- Store edge type, source, and timestamp for traceability.
2. Vector-only retrieval
Vector search is still useful, and the article’s example shows why: a query for “production risks” will likely pull the flooding report because the language is semantically related. That makes vectors a fast first pass for broad recall.
The limit is that vectors do not know Supplier A supplies Component X to Factory Y unless that relationship is written into the text. If the answer depends on a chain of facts, semantic similarity alone can return the right paragraph but miss the business implication.
- Best for fuzzy questions and document discovery.
- Weak when the answer depends on exact relationships.
- Often paired with chunking, embeddings, and reranking.
3. Graph + vector hybrid
The hybrid pattern uses vectors to find candidate text and a graph to verify or expand the result. In production, this is often the safest middle ground because it keeps semantic recall while adding structure-aware precision.
For the flooding example, the vector layer finds the news story, then the graph links Supplier A to Component X and Factory Y. The system can answer a stronger question: which factories may be affected if Supplier A stops shipping?
- Start with embeddings over documents and incident reports.
- Map extracted entities to graph nodes.
- Use graph edges to filter, rank, or expand retrieved evidence.
4. Hop-based expansion
Hop-based expansion follows relationships outward from a seed node or document. One hop might connect Supplier A to Component X; two hops may connect Component X to Factory Y, inventory levels, or downstream customers.
This pattern is useful when the user asks about dependencies, blast radius, or root cause. Instead of stopping at the first matching document, the system walks the graph to build a fuller answer from connected facts.
Supplier A -> provides -> Component X -> used by -> Factory Y
Supplier A -> located in -> Thailand
Thailand -> affected by -> flooding5. Query-time reasoning layer
The final pattern adds a reasoning layer at query time that decides how much graph traversal, vector search, and evidence scoring the system should use. This is where production systems become more reliable, because the retrieval plan changes with the question.
A simple “what happened?” query may need one document and one entity link. A “which plants are at risk if Supplier A is offline?” query may need graph traversal, document retrieval, and a ranked evidence set before the model drafts an answer.
- Route simple questions to direct retrieval.
- Route dependency questions to graph traversal plus evidence scoring.
- Keep the final answer grounded in cited nodes and documents.
How to decide
If your data is mostly text and the questions are broad, start with vector-only retrieval. If your users care about suppliers, assets, incidents, or other named entities, add an entity graph and use hybrid retrieval so the system can connect facts across sources.
If the goal is risk analysis, impact tracing, or anything that asks “what depends on what,” hop-based expansion and a query-time reasoning layer will usually pay off fastest. In practice, the best production setup is often not graph or vector, but graph plus vector with a clear routing rule.
// Related Articles
- [IND]
OpenAI is right to keep ads out of sensitive chats
- [IND]
AI bootlegs are already draining streaming royalties
- [IND]
AMD and Microsoft push Windows ML on GPU and NPU
- [IND]
OpenAI’s IPO filing turns hype into scrutiny
- [IND]
Skatteetaten proves public sector AI should be judged by outcomes
- [IND]
OpenAI’s IPO filing puts AI’s biggest test on Wall Street