Agent Memory: How AI Agents Keep State
Agent memory lets AI agents retain state across tasks. Here’s how short-, long-, and external memory shape real agent systems.
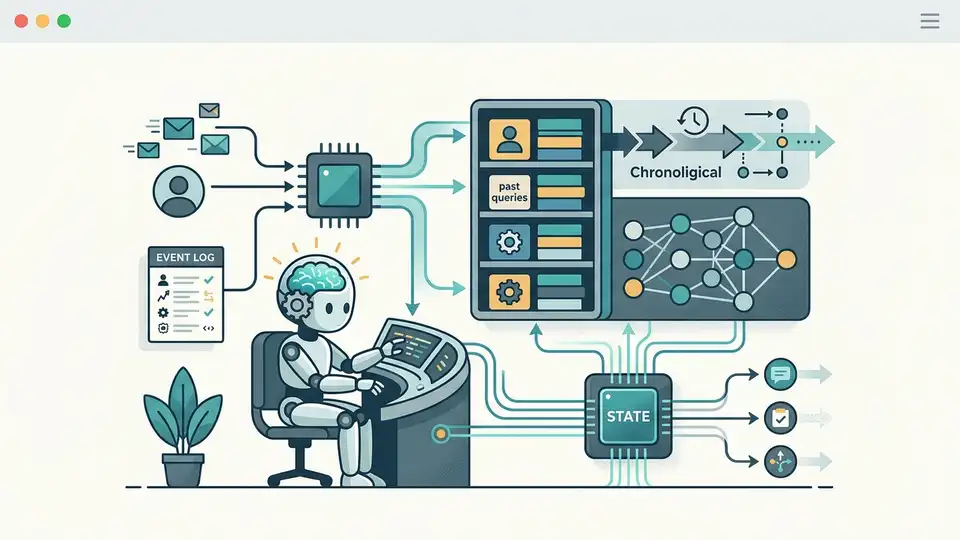
As OpenAI, Anthropic, and Google push chatbots toward agentic workflows, one issue keeps showing up: memory. A model that can answer a question once is useful; a system that can remember a task across hours, tools, and follow-up messages is far more capable.
That difference matters because agents do more than generate text. They retrieve information, call APIs, write files, track goals, and coordinate with other systems. Memory is what lets those behaviors persist instead of resetting after every prompt.
Why agent memory matters now
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The shift from single-turn chat to multi-step agents changed the technical requirements. A plain large language model can produce a response from the current prompt, but an agent often needs to recall what happened earlier, what it already tried, and what the user still wants done.
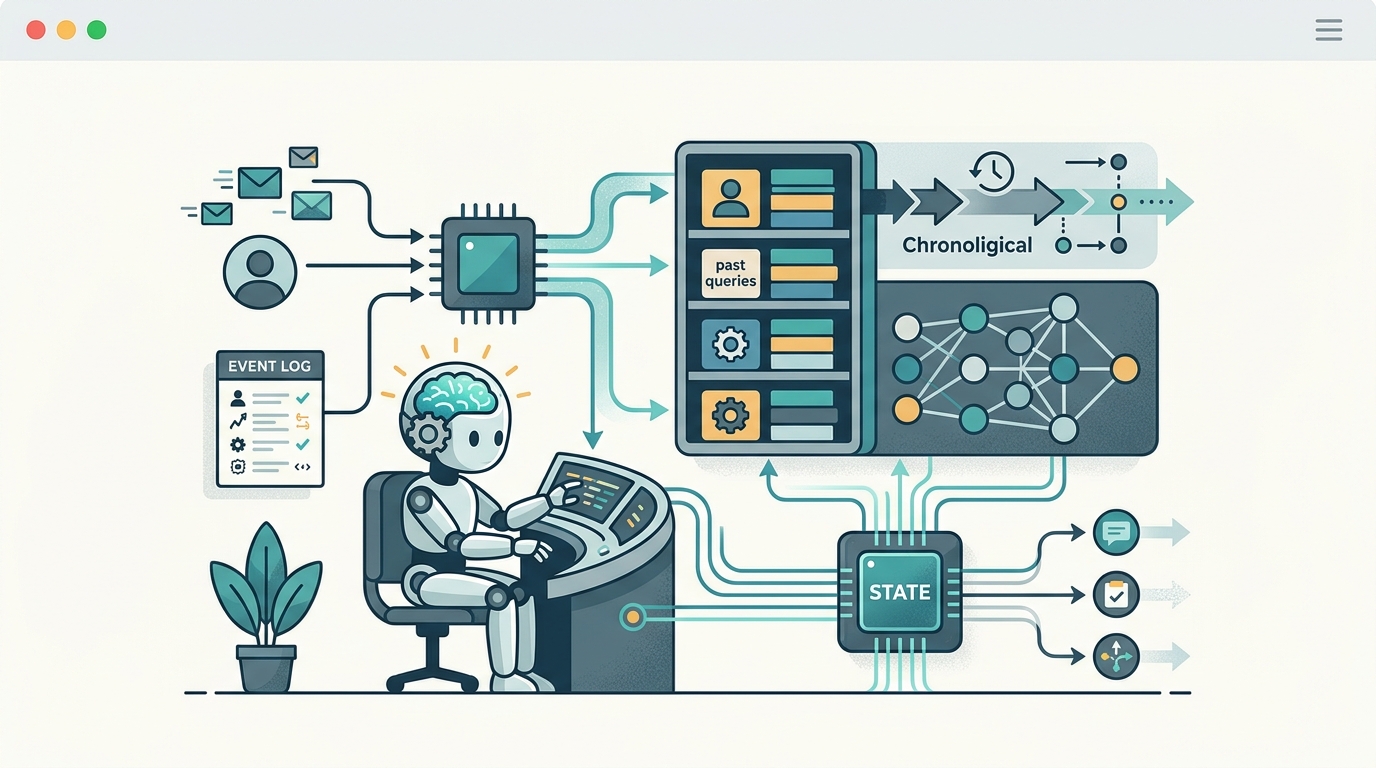
In practice, memory gives an agent continuity. Without it, every task starts from zero. With it, the system can remember preferences, preserve intermediate results, and avoid repeating failed actions. That is why memory is now a core design topic in agent frameworks, not an optional feature.
Agent memory usually shows up in four places: user preferences, task state, tool outputs, and long-running plans. These are different kinds of information, and they should not all be stored the same way.
- Short-term context: the current conversation window and recent tool calls
- Working state: active goals, sub-tasks, and temporary variables
- Long-term memory: preferences, prior decisions, and durable facts
- External memory: databases, vector stores, files, and logs
The main memory layers in agent systems
Most agent architectures separate memory into layers because no single storage method fits every need. The prompt window is fast and simple, but it is limited. Vector databases are good for retrieval, but they do not naturally preserve sequence or exact state. Structured stores handle state well, but they need explicit schemas.
This is why many systems combine multiple memory types. A short context window keeps the immediate exchange coherent. A state store tracks the current objective. A retrieval layer pulls in older facts when needed. Together, these layers make the agent feel persistent without forcing everything into the prompt.
“The future of AI does not belong to those who build the biggest models, but to those who learn how to make them useful.” — Fei-Fei Li
That quote captures the memory problem well. Utility depends on continuity. If an agent forgets user intent halfway through a workflow, it may still sound fluent, but it will fail at the task.
One useful way to think about agent memory is by time horizon. Some information matters for seconds, some for minutes, and some for months. A calendar assistant, for example, may need to remember a meeting location for a single session, while a support agent may need to remember account-level preferences for repeated interactions.
What frameworks are doing today
Agent frameworks are starting to expose memory as a first-class component. LangChain offers memory-related abstractions, Microsoft AutoGen focuses on multi-agent coordination, and LlamaIndex emphasizes retrieval over external knowledge sources.
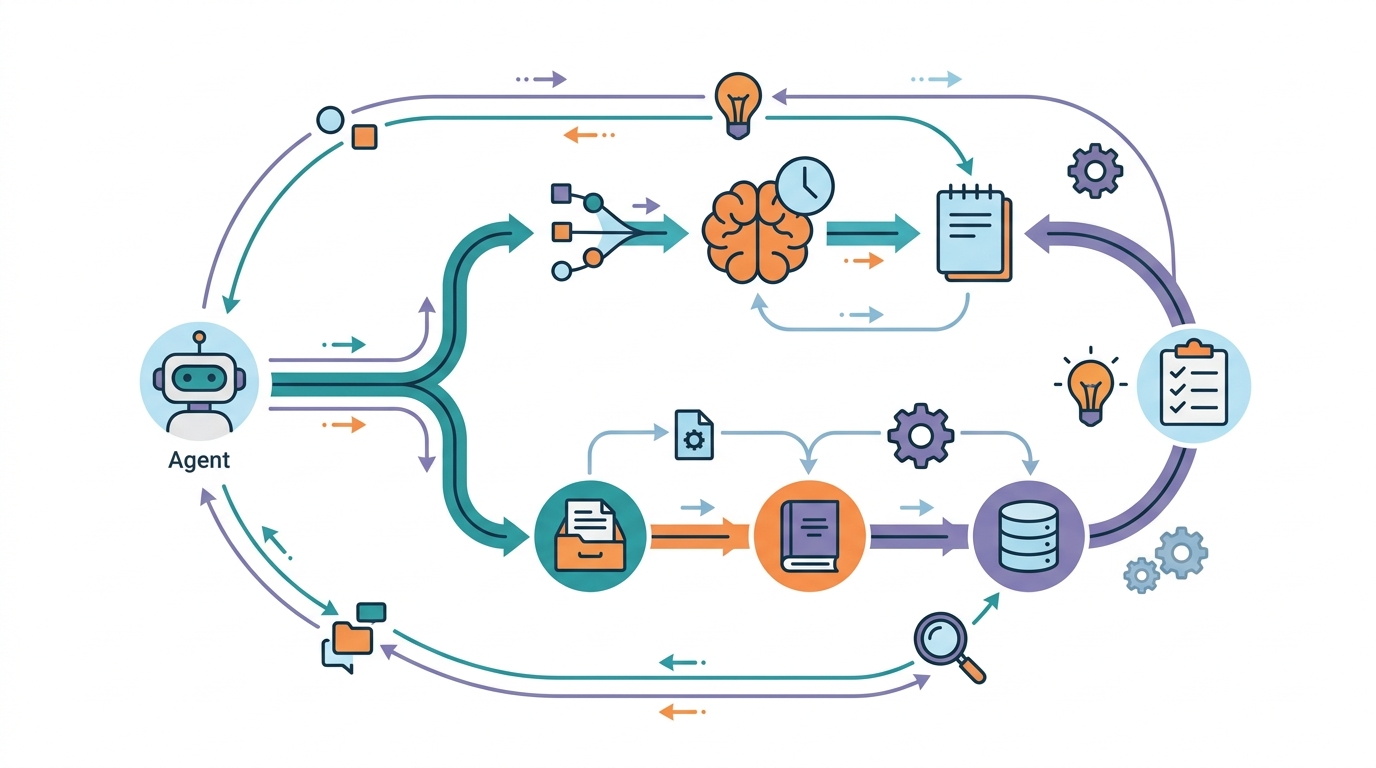
These projects do not all solve memory in the same way. Some keep a chat history and summarize it. Others write structured records to a store. Some retrieve past items only when the current task matches a query. The common goal is the same: preserve useful state without stuffing every detail into the model prompt.
- Prompt memory: cheap, immediate, but bounded by context length
- Summary memory: compact, but can lose details and chronology
- Vector memory: good for semantic recall, weaker for exact replay
- Structured memory: precise and queryable, but requires schema design
That tradeoff shows up in engineering decisions. If a product needs fast recall of user preferences, a structured profile may beat a semantic search index. If the system needs to remember past documents or conversations, vector retrieval often works better. If the task is highly procedural, state machines can be more reliable than free-form text memory.
There is also a cost angle. Memory is not free. Every extra retrieval step adds latency, and every stored item adds maintenance overhead. Teams need to decide what is worth remembering and what should be dropped.
Comparing memory approaches with real numbers
The practical limits are easy to see in current model and infra specs. OpenAI’s GPT-4.1 documentation lists a 1 million token context window for some variants, which sounds enormous until you start chaining multiple tasks, tool outputs, and reference documents.
Anthropic’s Claude documentation also highlights large context windows, but even large windows do not solve persistence across sessions. Once the conversation ends, the state is gone unless the application stores it elsewhere.
That is why external memory systems matter. A database can hold durable facts indefinitely. A vector store can retrieve similar items across sessions. A log can preserve exact sequences of actions. Each one solves a different part of the problem.
- Context window: best for immediate reasoning, limited by token budget
- Summary store: compact across sessions, but can flatten nuance
- Vector database: useful for fuzzy recall, depends on embedding quality
- SQL or document store: best for exact state and auditability
In real deployments, the strongest systems mix these methods. A customer support agent may keep the last few messages in the prompt, store account facts in a database, and retrieve related past tickets from a vector index. That combination is practical, measurable, and easier to debug than a single monolithic memory layer.
There is a reason many teams are moving in this direction. When memory is explicit, it is easier to test. You can inspect what the agent stored, why it recalled it, and whether the retrieval was correct. That matters more than clever wording in the prompt.
What to watch next
Agent memory is still early, but the direction is clear: systems will need better ways to decide what to store, when to retrieve it, and how to forget safely. The hardest part is not writing memory, it is managing relevance over time.
For builders, the practical takeaway is simple. Start with explicit state, add retrieval only where it helps, and keep a clear boundary between temporary context and durable memory. That design will age better than trying to make the prompt do everything.
If you are building an agent today, the next question is not whether it needs memory. It is which memory layer should own each kind of fact, and how will you prove that the agent remembered the right thing? That answer will decide whether your agent feels helpful or merely chatty.
// Related Articles
- [AGENT]
Claude Code 动态工作流:AI 自写 Harness
- [AGENT]
Agent orchestration is the missing layer for enterprise AI
- [AGENT]
AI agents use blockchain as a trust layer
- [AGENT]
8 RAG patterns that turn demos into prod
- [AGENT]
Fine-tuning beats RAG when the goal is style, not facts
- [AGENT]
OpenClaw shows how small businesses use AI staff