Causal methods for measuring task learnability
This paper shows correlational learnability tests can mislead, and proposes causal tools for formal-language tasks.
This paper shows correlational learnability tests can mislead, and proposes causal tools for formal-language tasks.
- Research org: Unspecified in arXiv abstract
- Core data: No benchmark numbers in abstract
- Breakthrough: Binning semiring for controlling target-property frequency
Language models are often judged by whether they can pick up a task from data, but the hard part is figuring out how much data really caused that learning. This paper argues that the usual correlational way of answering that question can be wrong, especially when tasks overlap and confound each other.
To make the problem easier to study, the authors move into a controlled setting built from formal languages induced by probabilistic finite automata. That gives them a testbed where they can isolate task frequency, model the sampling process more carefully, and ask what learnability means when you can actually intervene on the data.
What problem this paper is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The core question is simple: how much task-specific data does a model need before it learns a task? In natural language, that question is messy because tasks are not cleanly separated. A model might seem to learn one behavior, but the signal could actually come from another correlated behavior in the training mix.

The paper treats that as a measurement problem, not just a modeling problem. If you only look at correlations between data frequency and performance, you can end up attributing learning to the wrong sub-task. The authors say this is not a minor annoyance; it is a structural flaw in standard evaluation practice.
That matters for anyone trying to understand why a model acquires one capability before another. If your measurement method cannot distinguish causation from co-occurrence, then your conclusions about data efficiency, curriculum design, or task difficulty may be off.
Why formal languages are the testbed
Instead of starting with messy natural-language tasks, the authors use formal languages induced from probabilistic finite automata. That gives them a controlled environment where the task structure is explicit and the data-generating process is easier to reason about.
This move is important because it lets the paper focus on methodology. The point is not to claim that formal languages are the final application domain. The point is to demonstrate, in a setting with clean definitions, that standard correlational evaluation can still go wrong.
For engineers, that is a useful warning sign. If a method fails even in a controlled sandbox, then the same method is even less trustworthy when applied to real corpora full of overlapping linguistic phenomena.
How the method works in plain English
The main technical idea is the Causally Evaluating the Learnability of Formal Language Tasks paper’s introduction of the binning semiring. In plain terms, this is an algebraic tool that lets the researchers control how often a targeted property appears in a sampled corpus.
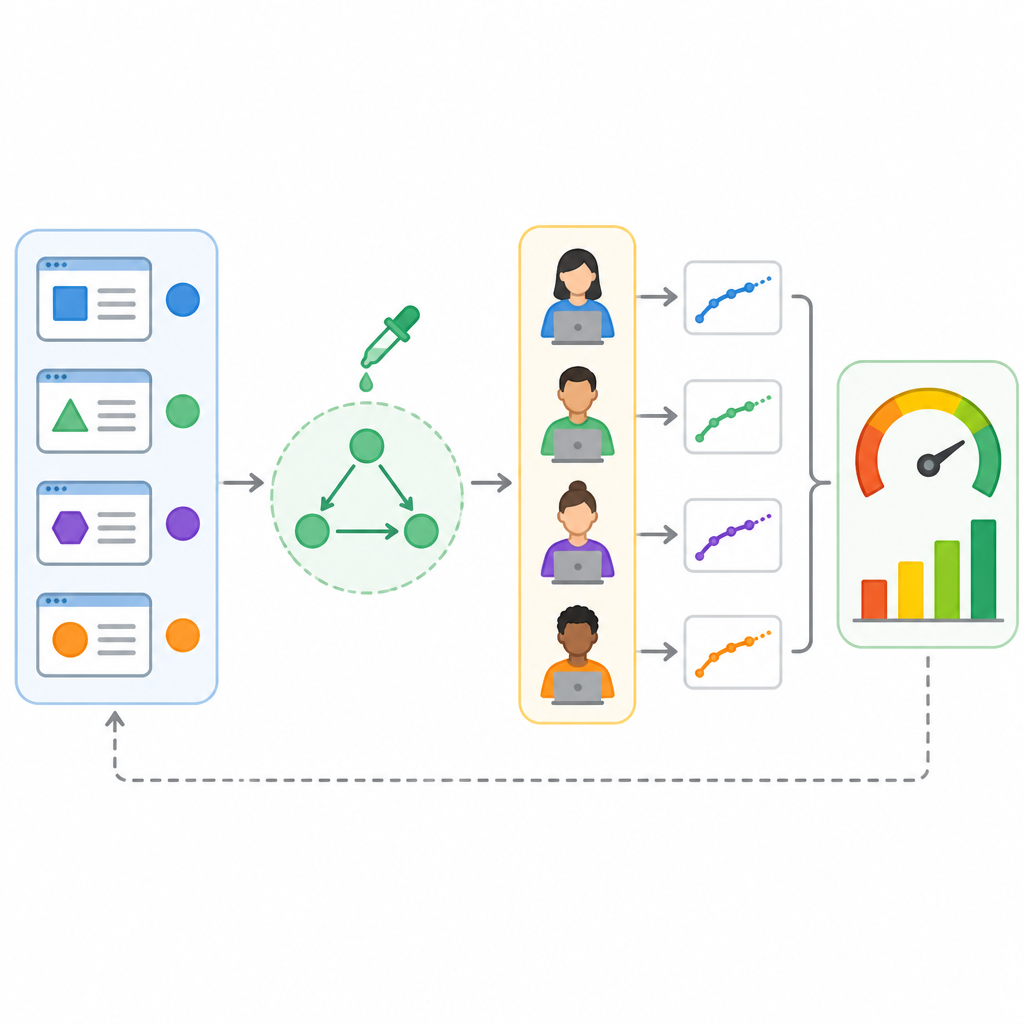
That control matters because it turns frequency from a passive observation into an experimental variable. Once you can tune how often a property shows up, you can ask whether the model’s apparent learning is really due to that property, or whether another correlated factor is driving the result.
The authors also formulate the whole pipeline as a causal graphical model. That is a strong signal that they are not treating the data as a flat table of examples and scores. They are explicitly modeling dependencies, confounders, and the path from corpus construction to observed learnability.
On top of that, they derive decomposed Kullback-Leibler divergence metrics. The abstract does not spell out the full derivation, but the goal is clear: measure the learnability of specific sub-tasks rather than collapsing everything into one blended score.
What the paper actually shows
The abstract does not provide benchmark numbers, so there are no accuracy figures, learning curves, or throughput claims to report here. What it does say is that the experiments demonstrate a methodological failure: if you evaluate learnability without causal intervention, you can draw incorrect conclusions because of confounders in correlational analysis.
That is the main result. The paper is not claiming a new state-of-the-art task score. It is showing that the measurement procedure itself can be misleading, even before you get to model architecture or optimization details.
In other words, the contribution is about inference discipline. The authors are telling researchers to stop treating frequency-performance correlations as proof of learnability, because the relationship may be contaminated by hidden structure in the dataset.
- Correlational analysis can misattribute learning when tasks confound one another.
- Causal intervention is needed to isolate the effect of targeted property frequency.
- The binning semiring provides a way to sample corpora with controlled property occurrence.
Why developers should care
If you build or evaluate language models, this paper is a reminder that your metrics may be answering the wrong question. A model that seems to learn a skill from more examples may actually be benefiting from a correlated pattern that happens to rise with those examples.
That has practical consequences for dataset design, ablation studies, and curriculum experiments. If you are trying to decide which data to collect next, or which sub-task is truly hard, a correlational readout can send you in the wrong direction.
The paper also offers a mindset shift: treat learnability as something to be causally identified, not just observed. Even if you never work with formal languages, the warning generalizes to natural-language settings where task boundaries are blurrier and confounding is more likely.
Limitations and open questions
The biggest limitation is scope. The abstract describes a controlled formal-language setting, not a direct evaluation on large-scale natural-language benchmarks. That means the paper is best read as a methodological proof of concept rather than a complete recipe for production evaluation.
Another open question is how easily the binning semiring and the causal pipeline transfer to real training corpora. The abstract says the formal-language setup is a methodological testbed, which suggests the practical challenge is extending the approach to messier data without losing the clean causal interpretation.
There is also no benchmark table in the abstract, so the paper’s value here is conceptual and methodological rather than numeric. For practitioners, that still matters: better measurement can prevent bad conclusions, even when it does not immediately improve model scores.
Bottom line: this paper argues that if you want to know what data really teaches a model, you need causal tools, not just correlations. For anyone studying data efficiency, task decomposition, or training curricula, that is a message worth taking seriously.
// Related Articles
- [RSCH]
CRDTs keep replicas in sync without locks
- [RSCH]
Post-Deterministic Systems for Autonomous Infra
- [RSCH]
RL Training That Hands Off Control Gradually
- [RSCH]
OmniGameArena benchmarks VLM game agents better
- [RSCH]
TurboQuant cuts KV cache memory 6x in Google tests
- [RSCH]
MemDreamer tackles long-video overload