MLLMs for cleaner subject-driven image generation
This paper uses MLLMs plus VAE identity conditioning to improve subject-driven image generation and reduce copy-paste artifacts.
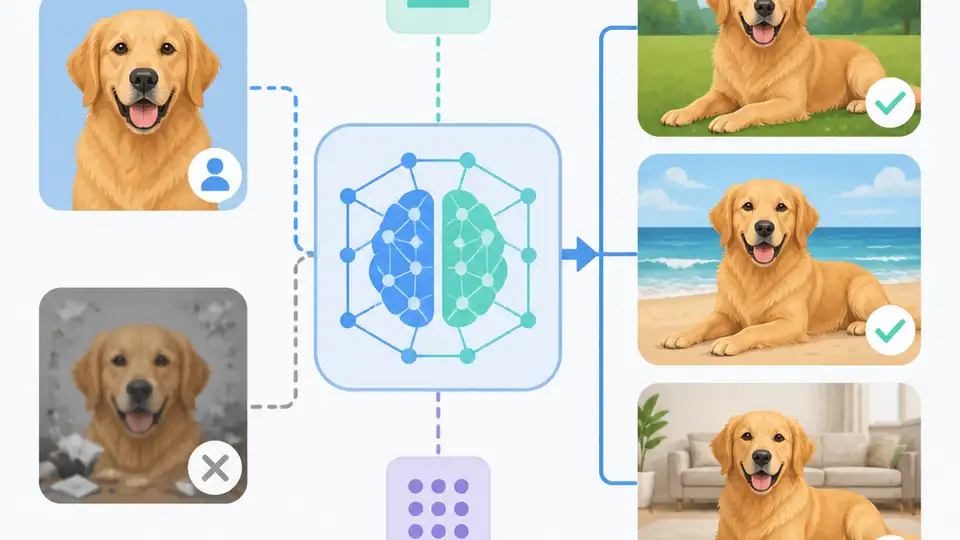
This paper uses MLLMs plus VAE identity conditioning to improve subject-driven image generation and reduce copy-paste artifacts.
- Research org: Unspecified in arXiv abstract
- Core data: No benchmark numbers in abstract
- Breakthrough: Dual Layer Aggregation plus multi-stage denoising
Subject-driven image generation is one of those problems that looks simple on paper and gets messy fast in practice: keep the subject recognizable, but still obey the prompt. The authors of Squeezing Capacity from Multimodal Large Language Models for Subject-driven Generation argue that the usual split-encoding setup is part of the problem, because text and reference images are processed separately and the model loses cross-modal reasoning.
Their answer is to move conditioning closer to how people actually describe and identify things: with a multimodal model that sees both the instruction and the reference image together. Then they add a VAE-based identity signal to keep the subject’s fine details from drifting away during generation.
What problem this paper is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
Subject-driven generation sits at the intersection of personalization and prompt following. You want a model to generate a new image of a specific person, object, or subject while changing the scene, style, or action according to text instructions. In practice, that means balancing two competing goals: preserve identity and obey the prompt.
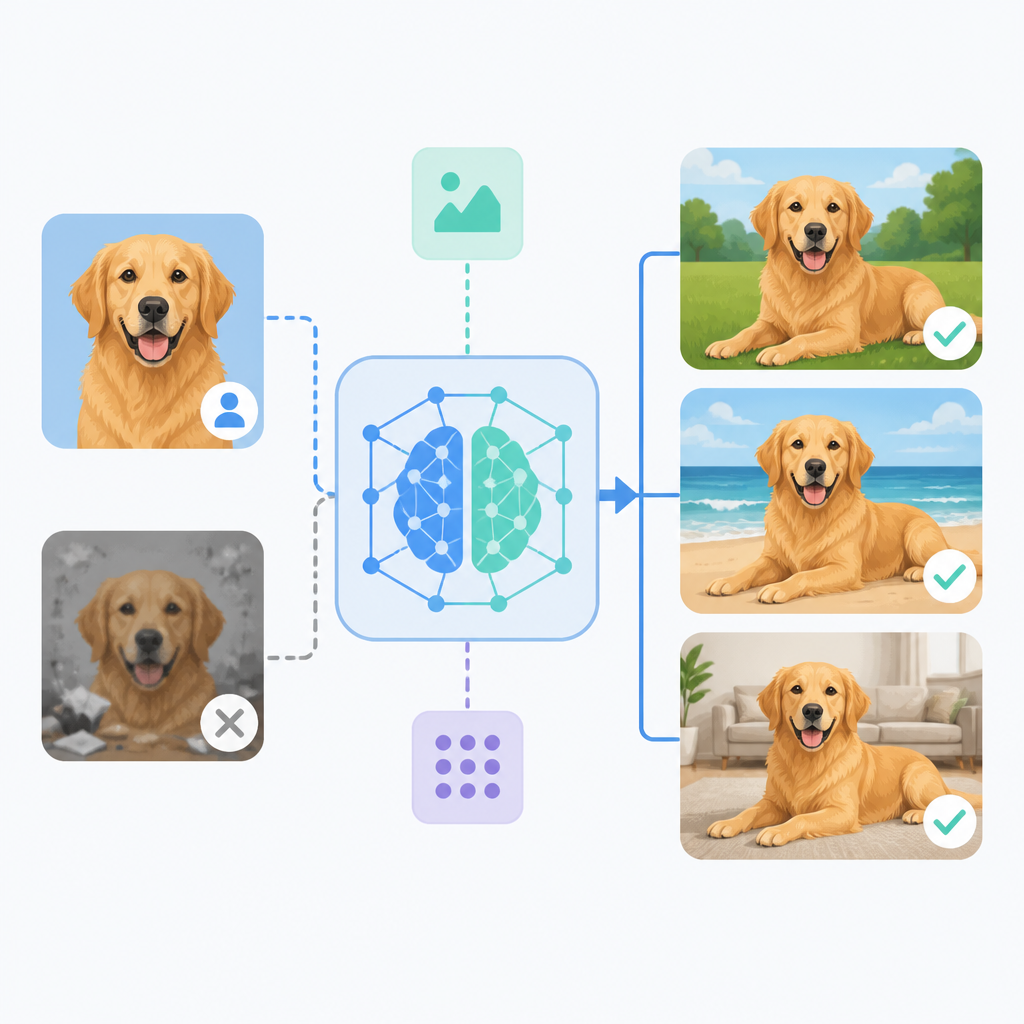
The abstract says existing approaches often encode text and reference images separately. That design choice limits cross-modal reasoning, which is exactly what you need when the model has to decide which details belong to the subject and which details come from the instruction. The result, according to the paper, is a tendency toward copy-paste artifacts.
This is the core engineering pain point: the model can either be faithful to the reference or responsive to the prompt, but not both. For developers building personalization tools, that tradeoff shows up as awkward composites, identity drift, or images that look too much like the source reference pasted into a new background.
How the method works in plain English
The main shift here is to condition diffusion models on a multimodal large language model, or MLLM, that jointly encodes the text and the reference image. Instead of treating the two inputs as separate streams, the model gets a shared representation that can support cross-modal understanding.
That MLLM pathway is then augmented with VAE-based identity conditioning. The abstract frames this as a way to preserve fine-detail identity information, which suggests the VAE branch is there to protect the subject-specific visual cues that might otherwise get washed out by higher-level semantic conditioning.
The paper also introduces a Dual Layer Aggregation, or DLA, module. In plain terms, DLA aggregates multi-level MLLM features so the diffusion model can use the right mix of information when it is being conditioned. The abstract does not spell out the exact layer-by-layer mechanics, but the goal is clear: make the multimodal features more useful for generation than a single flat embedding would be.
Finally, the authors use a multi-stage denoising strategy during inference. This progressively balances semantic information from the MLLM against fine-detail identity from the VAE. That staged approach matters because subject-driven generation is not just about one decision at the start; it is an iterative process where the model can drift, overfit, or over-smooth as denoising proceeds.
What the paper actually shows
The abstract claims extensive experiments, but it does not provide benchmark names, exact scores, or numeric gains. So if you are looking for a table of results, the abstract does not give one. What it does say is that the method harmonizes multimodal understanding with identity preservation, mitigates copy-paste issues, and achieves superior performance regarding human preference on subject-driven image generation.
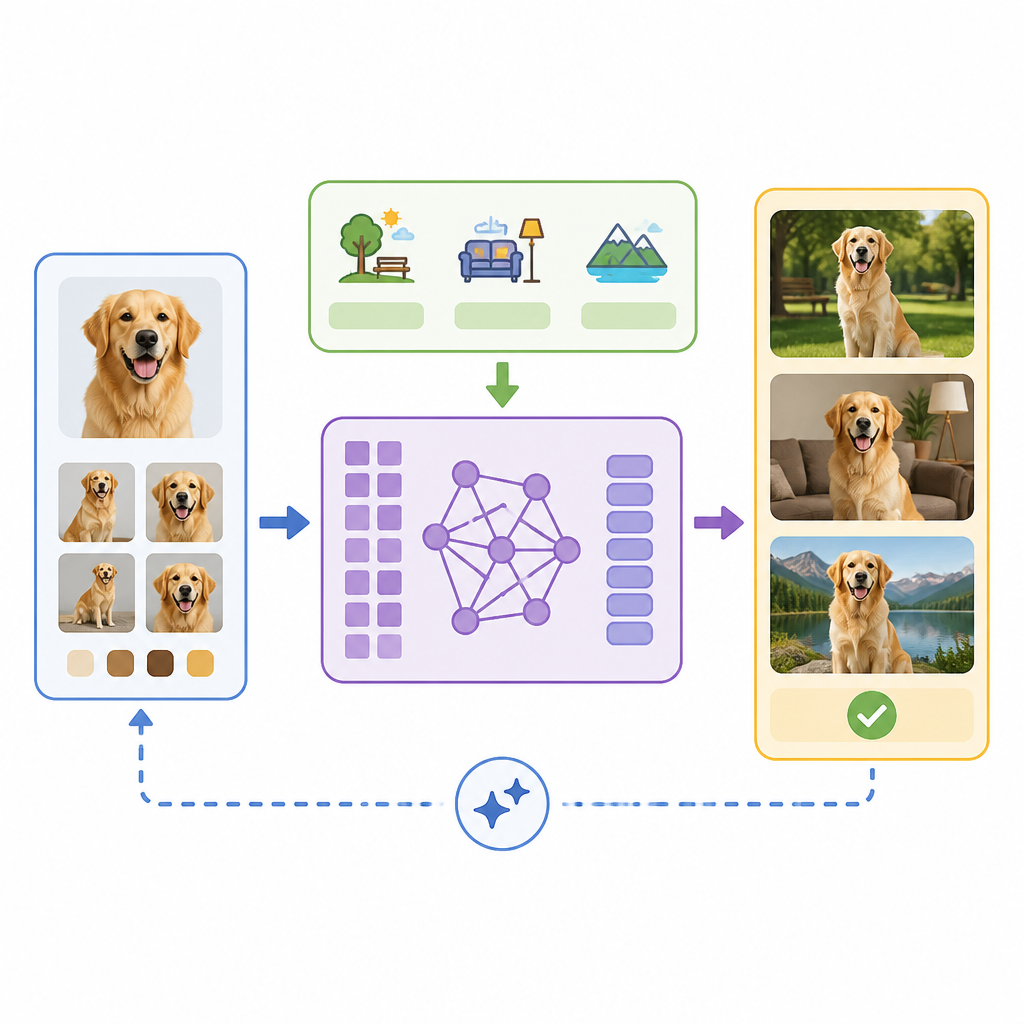
That last point is important, but also worth reading carefully. “Human preference” tells you the evaluation included subjective judgment, not just automated similarity metrics. The abstract does not say how many raters there were, what the comparison baselines were, or whether the gains were large or marginal.
Still, the direction of improvement is useful. The paper is not claiming a new general image generator; it is targeting a very specific failure mode in personalized generation. If the method really reduces copy-paste artifacts while keeping identity intact, that is a meaningful step for workflows where visual consistency matters more than raw diversity.
Why developers should care
If you are building a product around personalized image generation, the architecture choice here maps directly to product quality. Separate encoders for text and reference images are simpler, but the paper argues they leave performance on the table because they cannot reason across modalities as well as a joint MLLM representation can.
The practical takeaway is that multimodal conditioning is not just about adding more inputs. It is about how those inputs are fused, how identity is preserved, and how generation is steered over time. The combination of DLA, VAE identity conditioning, and multi-stage denoising is the paper’s attempt to solve all three at once.
For implementers, that also means the system is likely more complex than a basic reference-image pipeline. More conditioning paths and staged inference usually imply more tuning surface area, more opportunities for mismatch, and potentially higher inference cost. The abstract does not quantify those tradeoffs, so we cannot say how expensive the method is or how easy it would be to drop into an existing stack.
Limitations and open questions
The biggest limitation here is simple: the abstract is light on concrete evaluation detail. There are no benchmark numbers, no dataset names, and no ablation results in the provided text. That makes it hard to judge how much each component contributes on its own.
It is also not clear from the abstract how broadly the method generalizes beyond the subject-driven setting. The paper is focused on improving identity preservation while obeying text instructions, so any broader claims about general multimodal reasoning would go beyond what the source actually says.
There is also an implementation question hiding in the design. A multi-stage denoising strategy can improve quality, but it can also complicate deployment and tuning. The abstract does not tell us whether the gains justify that added complexity in real systems.
Even with those gaps, the paper’s direction is easy to understand: if you want better personalized image generation, you probably need a model that reasons over text and reference images together, not separately. That is the central engineering lesson here.
Bottom line
This paper argues that subject-driven generation improves when a diffusion model is conditioned on a joint multimodal representation, then reinforced with explicit identity conditioning. The result, at least according to the abstract, is better prompt adherence, fewer copy-paste artifacts, and stronger human preference.
For developers, the value is not just in the specific module names. It is in the design pattern: fuse modalities earlier, preserve identity explicitly, and manage the denoising process so semantics and detail stay in balance.
- Joint text-image conditioning is the key architectural change.
- Identity preservation is handled separately with VAE-based conditioning.
- The abstract promises better human preference, but gives no numeric benchmarks.
// Related Articles
- [RSCH]
CRDTs keep replicas in sync without locks
- [RSCH]
Post-Deterministic Systems for Autonomous Infra
- [RSCH]
Causal methods for measuring task learnability
- [RSCH]
RL Training That Hands Off Control Gradually
- [RSCH]
OmniGameArena benchmarks VLM game agents better
- [RSCH]
TurboQuant cuts KV cache memory 6x in Google tests