How a Solana dapp outgrew free RPC
A developer story that turns a hobby Solana bot into production with dedicated RPC, plus a copy-ready rollout template.

This breaks down how a Solana hobby bot moved to production with dedicated RPC.
I've been around enough blockchain side projects to know the exact moment things go sideways. Everything feels fine in the tutorial phase. Your script hits a free RPC endpoint, transactions confirm, and you start feeling clever because the whole stack looks simple. Then real users show up and the whole thing starts coughing. I’ve watched that movie more than once, and it’s always the same annoyance: the code isn’t the problem, the infrastructure is. That’s what made this Insider Monkey piece worth reading. It’s not really about Solana in the abstract. It’s about the boring, expensive, unsexy moment when a hobby dapp stops being a toy and starts acting like a product. That shift is where a lot of developers get blindsided. They think they’re scaling features. What they’re actually scaling is traffic into a free tier that was never meant to carry it.
The source that triggered this breakdown is Insider Monkey’s “From Hobby Project to Production: How One Developer Scaled Their Dapp on Solana”. It’s a contributor post, not a technical benchmark or a vendor doc, so I’m treating it as a story with a useful lesson: free RPC is fine until users arrive. The article doesn’t give star counts or bookmarks, and I’m not inventing any. What it does give is a very familiar failure mode, plus a simple answer: move to dedicated infrastructure before your users teach you the lesson the hard way.
Free RPC is a training wheel, not a launch plan
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
“For a hobby project making a few test transactions per day, it was perfect. No cost, no complexity, no friction.”
What this actually means is that free RPC endpoints are optimized for learning, not for being the backbone of a product people depend on. Sarah’s setup worked because the traffic pattern was tiny and forgiving. A few test transactions per day is not a load test. It’s a warm-up lap.

I ran into this exact trap when I first wired up a bot against a public endpoint. It felt absurdly good. No billing setup, no credentials drama, no ops work. But that convenience hides the real contract: you’re sharing capacity with a crowd of other people who had the same tutorial open in another tab. The endpoint is not yours. The queue is not yours. The latency spikes are not a bug, they’re the business model.
How to apply it: keep free RPC for local development, demos, and throwaway experiments. If you’re still changing core behavior every hour, stay cheap. But the second you need reliable confirmation times, predictable throughput, or user-facing actions that matter, stop pretending the free tier is part of your architecture. It isn’t. It’s a sandbox.
- Use free RPC for prototyping and internal testing only.
- Track request volume early, even if you think it’s “small.”
- Write down the point where failures become user-visible, then move before that point.
Launch day is where the endpoint tells the truth
“Within the first hour, transactions started timing out.”
That line is the whole story. Not because the code suddenly became bad, but because launch day changes the shape of the workload. Fifty friends is not huge by consumer app standards, but for a dapp that depends on request/response timing, it’s plenty. The article makes the useful distinction: in the lab, the bot looked fine. In production, the same bot became unreliable because the infrastructure was the bottleneck.
That’s the part developers hate admitting. We like to debug ourselves first. I do it too. I’ll check the contract, the wallet flow, the serialization, the retry logic, all of it. And half the time the issue is upstream. The endpoint is rate-limiting, dropping, or slowing down under shared load. Your app looks broken because the plumbing is lying to you.
How to apply it: build a launch checklist that assumes the RPC layer will fail under real traffic. Test with concurrent users, not just sequential requests. Watch for timeouts, dropped submissions, and confirmation lag. If you’re building a trading bot, swap flow, or anything time-sensitive, simulate a burst before you invite real users. You want the failure to happen in staging, not in front of your first fifty customers.
- Run concurrent transaction tests before launch.
- Measure timeout rate, not just success rate.
- Separate app bugs from RPC symptoms in your debugging notes.
Dedicated nodes are boring, and that’s the point
“The setup took 20 minutes. She updated her endpoint URL, redeployed her bot, and invited her users back.”
What this actually means is that the fix was not magical. It was operational. She swapped an endpoint, redeployed, and got back to work. That’s a good sign. Infrastructure should feel boring once you’ve chosen the right tier. If moving from free to dedicated is a giant migration project, you probably waited too long or picked the wrong provider.
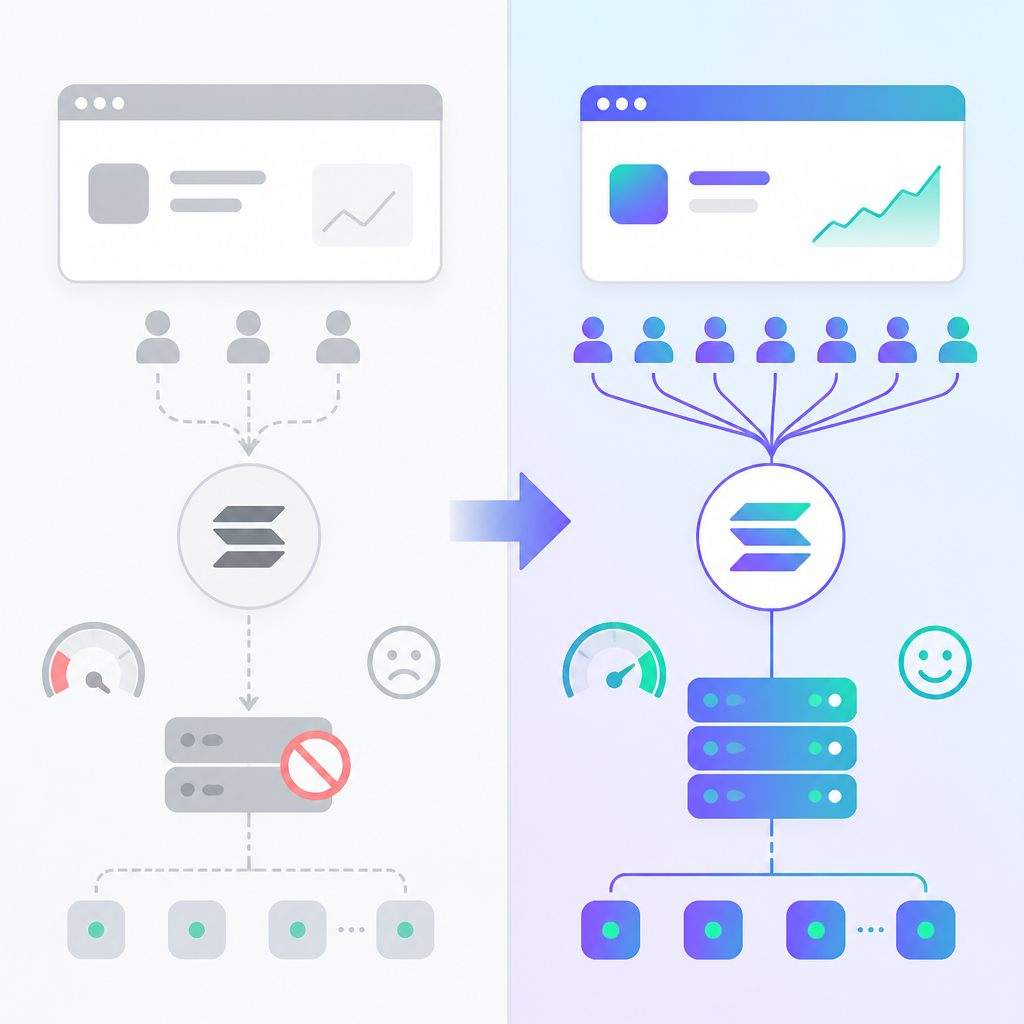
The article frames dedicated Solana infrastructure as the thing that turns a hobby script into a production system. That’s fair. The moment your users expect orders to land, you’re no longer just writing code. You’re running a service. The dedicated node gives you prioritized requests, better uptime expectations, and a buffer against other people’s traffic. In other words, it buys you predictability.
I’ve had projects where the monthly RPC bill looked annoying until I compared it with the cost of user churn, support tickets, and lost trust. The bill is visible. The damage from failed transactions is slower and nastier. Users don’t file a neat report saying “RPC contention caused my frustration.” They just leave.
How to apply it: pick a dedicated RPC provider before launch, not after the first incident. Keep the cutover simple. Use environment variables for the endpoint so you can switch without editing code in five places. If your provider offers a staging endpoint, test the production config against it first. Then do one clean redeploy and verify transaction flow end to end.
For Solana-specific infrastructure, I’d start by comparing documentation from Solana, node providers such as Helius, and the network docs around RPC behavior. I’m not endorsing one vendor here. I’m saying you should stop treating RPC like a free utility and start treating it like a purchased dependency.
Infrastructure is part of the product, not the background noise
“Infrastructure is part of your product.”
This is the sentence I wish more builders would tattoo on the inside of their eyelids. The article is blunt about it, and it should be. Users do not experience your elegant architecture diagram. They experience whether a transaction lands, whether a swap completes, and whether the app feels trustworthy.
What this actually means is that reliability is a feature. If your app is fast on paper but flaky in practice, the user experience is bad. If your bot makes money only when the endpoint is calm, then calm weather is now a hidden dependency in your business model. That’s not a product. That’s a coincidence.
I’ve seen teams spend weeks polishing UI details while their backend requests were getting throttled in the background. That mismatch is painful because it creates false confidence. The app looks ready. The logs say “mostly okay.” Then the first spike hits and everything falls apart. The article’s lesson is simple: do not separate product quality from delivery quality.
How to apply it: write down your infrastructure assumptions in the same doc as your feature requirements. If your dapp needs sub-second confirmation, say it. If your service can tolerate retries, say that too. Then map each assumption to an actual provider capability. If the provider cannot meet the requirement, the feature is not done. It is just demo-ready.
Paying for reliability is cheaper than paying for failure
“The $100/month she was spending on a dedicated node was nothing compared to the cost of losing users due to failed transactions.”
This is the economics section, and it’s the one people resist until they’ve been burned. Free feels elegant. Paid feels premature. Then a launch goes sideways and suddenly the “expensive” option looks like a bargain. The article doesn’t try to romanticize this. It just points out that user trust is more expensive to rebuild than a node subscription is to maintain.
What this actually means is that infrastructure spend should be judged against business damage, not against the memory of “free.” If a failed transaction causes a user to abandon your app, the real cost isn’t the RPC bill. It’s the lost user, the support time, and the reputational hit. For anything involving money, delays and failures have a way of compounding into real pain very quickly.
How to apply it: put a dollar estimate on the cost of one failed user action. If you can’t estimate it precisely, use a rough range. Then compare that to the monthly cost of a dedicated RPC provider. In most production cases, the math is embarrassingly one-sided. If your app handles payments, swaps, or trading, reliability spend should be one of the first line items, not an afterthought.
- Estimate the cost of one failed transaction in support time and churn.
- Compare that cost to monthly infrastructure fees.
- Promote reliability spend from “ops” to “product budget.”
Use the free tier until it starts lying to you
“Free RPC endpoints are great for learning and testing. But the moment you have real users, real transactions, and real expectations, you need infrastructure that can scale with you.”
This is the cleanest summary in the whole piece, and I agree with it. The free tier is not the enemy. It’s useful. I still use free or shared endpoints when I’m exploring a chain, checking an API shape, or building a proof of concept. The mistake is assuming that because it worked once, it can keep carrying the load.
What this actually means is that the boundary between “learning” and “production” is not philosophical. It’s behavioral. When you can no longer tolerate timing variance, dropped requests, or shared-rate surprises, you’ve crossed it. And once you cross it, every shortcut starts costing you more than it saves.
How to apply it: define a migration trigger now. For example: “If we hit X daily active users, Y transactions per hour, or Z% timeout rate, we move to dedicated RPC.” That gives you a rule instead of a mood. Teams get into trouble when infrastructure decisions are made by vibes. Vibes are how you end up debugging at midnight while users wait.
The template you can copy
# Solana dapp RPC scaling checklist
## Phase 1: Learning
- Use a free public RPC endpoint.
- Keep traffic low and internal.
- Focus on wallet flow, transaction building, and basic confirmations.
- Do not promise reliability to users yet.
## Phase 2: Pre-launch
- Measure request volume per minute.
- Test with concurrent users, not just one-by-one requests.
- Record timeout rate, dropped requests, and confirmation latency.
- Identify the exact point where free RPC starts failing.
## Phase 3: Production
- Move RPC URL to an environment variable.
- Switch to a dedicated Solana RPC provider.
- Verify uptime expectations, rate limits, and support response.
- Redeploy and run an end-to-end transaction test.
## Decision rule
Move off free RPC when any of these are true:
- real users are submitting transactions
- failed requests create support issues
- latency affects trading, swaps, or payments
- traffic spikes are no longer rare
## Rollout plan
1. Pick a dedicated provider.
2. Update the endpoint in staging.
3. Run load tests with concurrent requests.
4. Cut over production traffic.
5. Watch confirmations, timeouts, and error rates for 24 hours.
6. Keep the free endpoint only as a fallback for experiments.
## What to tell the team
"Free RPC is for learning. Dedicated RPC is for users. If the app depends on reliability, infrastructure is part of the product."
## Copy-paste launch note
We are moving the dapp from free public RPC to dedicated RPC because production traffic needs predictable confirmations, lower timeout risk, and support we can actually rely on. The cutover will happen behind an environment variable so the change is reversible if needed.If I were turning this into an internal playbook, I’d keep the language this plain. No fancy architecture theater. Just a clear rule for when to move, what to test, and what success looks like after the cutover. That’s what the article gets right. It turns a vague “scale later” idea into a concrete operational decision.
Source attribution: the original story is on Insider Monkey. My breakdown is original commentary built from that source, plus my own developer experience with RPC-backed apps and production cutovers.
// Related Articles
- [TOOLS]
Magenta RealTime 2 lets you score in the DAW
- [TOOLS]
Open-source AI tools beat Claude’s paid tiers on value
- [TOOLS]
500 AI agent projects show where agents work now
- [TOOLS]
Chocolatey’s Go package turns installs into policy
- [TOOLS]
Go support policy turns releases into a checklist
- [TOOLS]
RustDesk self-hosting setup for secure remote access