Why Amazon S3 Vectors matters more as storage than search
Amazon S3 Vectors is a storage-layer win, not a search-layer replacement, and AWS is right to position it that way.

Amazon S3 Vectors is a storage-layer win, not a search-layer replacement.
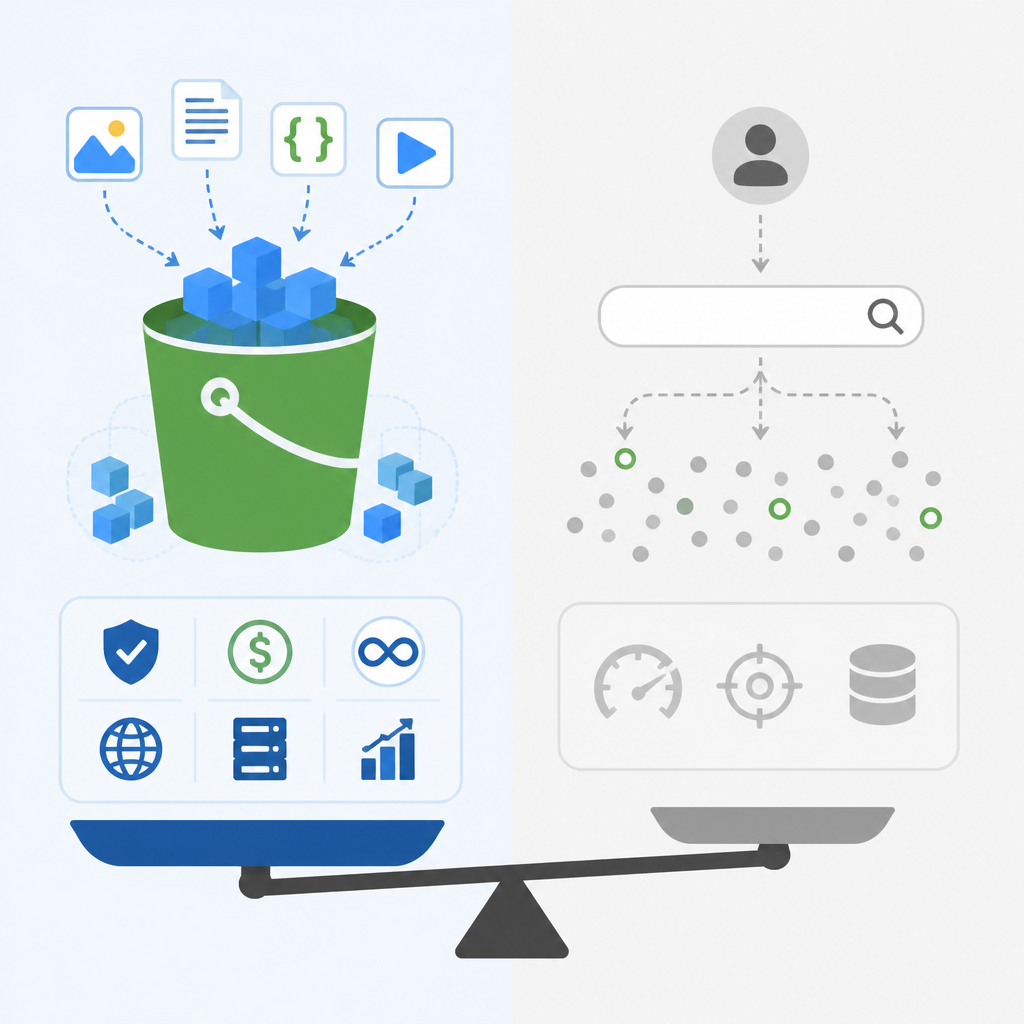
Amazon is right to frame S3 Vectors as a cost-optimized vector storage layer, not a replacement for a serious vector database. The pitch is simple: store billions of embeddings in S3, query them cheaply, and move only the hottest data into OpenSearch when latency and throughput matter. That is the correct architecture for most teams, because the real bottleneck in AI systems is not just retrieval speed but the cost of keeping every embedding in premium memory-backed infrastructure. AWS says S3 Vectors can cut vector storage, upload, and query costs by up to 90%, support up to 2 billion vectors per index, and keep warm query latency at around 100 ms. Those numbers matter because they turn vector search from a specialized database problem into a storage economics problem.
S3 Vectors fixes the wrong place where teams overspend
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
Most organizations do not need every vector to live in an expensive, always-hot search engine. They need a durable place to keep enormous embedding corpora, then a way to activate only the most relevant subset when traffic justifies it. S3 Vectors does that by making the storage tier cheap enough to hold long-tail data that would otherwise get deleted, compressed, or never indexed at all. In practice, that means better recall for semantic search and better memory for agents without forcing the entire corpus into a high-cost serving layer.

The example AWS gives is the right one: OpenSearch handles high-QPS, low-latency search, while S3 Vectors holds the colder data that still needs to be queryable. That split is not a compromise, it is the architecture. Teams routinely overbuild vector systems by assuming every embedding deserves the same serving path. They do not. A video archive, a document lake, or a historical interaction store needs cheap persistence first, and fast activation second. S3 Vectors makes that separation explicit instead of hiding it behind one oversized search cluster.
Tiered vector infrastructure is the sane default for AI
AI workloads are not uniform, and vector infrastructure should stop pretending they are. Retrieval for an active chat session, semantic search over a current product catalog, and historical recall for an agent memory layer all have different latency and freshness needs. AWS is smart to pair S3 Vectors with Amazon OpenSearch Service and Bedrock Knowledge Bases, because that combination maps directly to workload tiers: cheap cold storage, moderate-access retrieval, and high-performance serving. The result is a system that lets teams pay for intensity only where intensity exists.
The strongest evidence is the integration story itself. AWS says S3 Vectors plugs into Bedrock Knowledge Bases, SageMaker Unified Studio, and OpenSearch Service, which means the product is not trying to win by isolation. It is trying to become the default backing store for vector data that later graduates into a hotter index. That is a better bet than forcing every AI team to choose between a full vector database bill and a brittle homegrown pipeline. The tiered model also matches how production systems evolve: prototypes begin in cheap storage, then the highest-value slices get promoted as usage patterns harden.
Cost compression matters more than raw novelty
The headline claim here is not that S3 Vectors invents a new retrieval algorithm. It is that it changes the economics of keeping vector data around. AWS’s up to 90% cost reduction is the kind of claim that should make operators pay attention, because vector sprawl is already a quiet budget killer. Once teams start embedding everything from product docs to video frames to support tickets, the dataset grows faster than the appetite for specialized infrastructure. A cheaper default means more of the corpus stays searchable instead of being trimmed to fit a budget.
That matters especially for long-lived AI agents. Agents need memory, and memory is expensive if every interaction must sit in premium search infrastructure forever. S3 Vectors makes the case that “lasting memory” should be a storage feature, not a database luxury. For teams building RAG systems, customer support copilots, or media search tools, the ability to retain more context without paying a permanent high-performance tax is the difference between a useful system and a toy. The product is not just reducing cost, it is expanding what teams can afford to remember.
The counter-argument
The best objection is that S3 Vectors is still not the right tool for the hottest path. If an application needs sub-10 ms retrieval, high QPS, or aggressive filtering and ranking, a purpose-built vector database or OpenSearch remains the better choice. That is true. S3 Vectors is not designed to erase the need for specialized search engines, and AWS does not claim that it does. The product’s own positioning admits the limit: it is for long-term, infrequently accessed vector data, with OpenSearch reserved for the high-performance tier.
But that limitation is exactly why the product is important. Most teams should not be optimizing the coldest 80% of their embeddings for the hottest 20% of their traffic. The rebuttal is not that S3 Vectors beats every vector database on raw speed. It is that it removes the expensive mistake of treating all vectors as equally hot. If the architecture is tiered correctly, the hottest data still moves to the fastest system. S3 Vectors wins because it makes that move cheaper, simpler, and more durable.
What to do with this
If you are an engineer or PM, treat S3 Vectors as the default cold tier for vector-heavy products and design your stack around promotion, not permanence. Keep the full embedding corpus in S3, measure access frequency, and move only the active slice into OpenSearch or another low-latency engine. If you are a founder, use this to lower your unit economics early: build for retention, not just retrieval, and you will ship richer RAG, better semantic search, and stronger agent memory without committing to an oversized infra bill on day one.
// Related Articles
- [TOOLS]
Magenta RealTime 2 lets you score in the DAW
- [TOOLS]
Open-source AI tools beat Claude’s paid tiers on value
- [TOOLS]
500 AI agent projects show where agents work now
- [TOOLS]
Chocolatey’s Go package turns installs into policy
- [TOOLS]
Go support policy turns releases into a checklist
- [TOOLS]
RustDesk self-hosting setup for secure remote access