Tag
1 articles
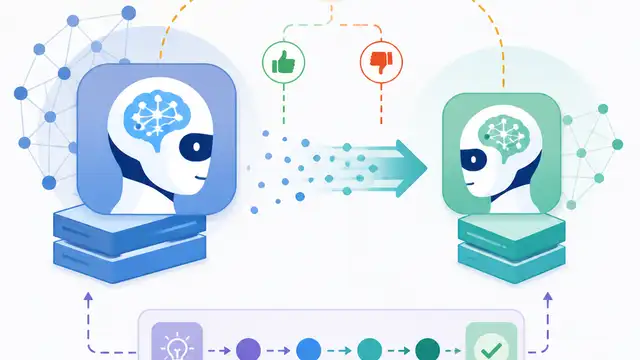
This paper proposes reinforcement-aware knowledge distillation to improve LLM reasoning, but the abstract provides no benchmark numbers.