2026 系統設計面試一頁模板
一頁版 2026 系統設計面試速查表,整理核心概念、取捨、常見模式,外加可直接套用的回答模板。
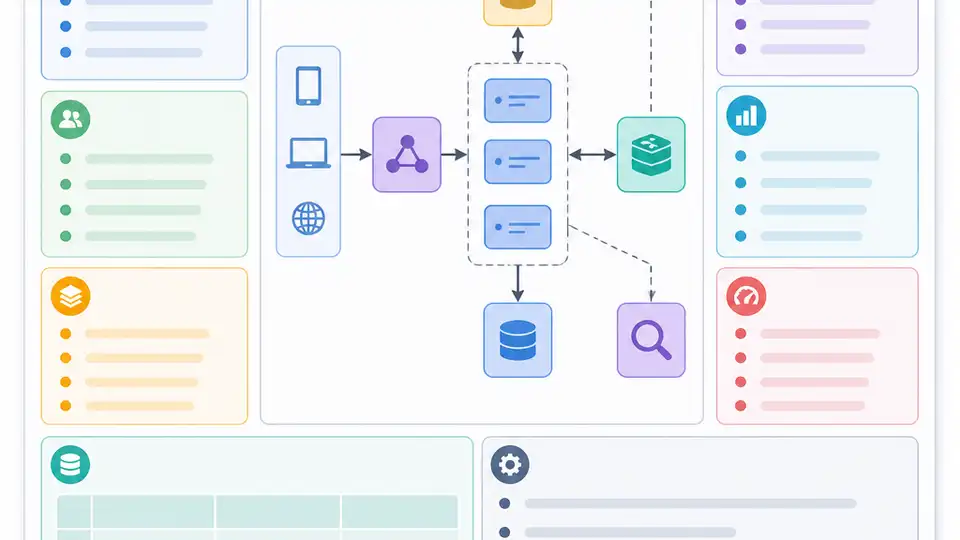
這篇整理一頁版 2026 系統設計面試模板,讓你直接抄回答框架、核心概念和取捨句型。
我拿系統設計 cheat sheet 已經看過一輪又一輪了,老實說,大多數都很像把教科書掃進去就交差。名詞一堆、圖一堆,真到面試時腦袋一空,還是只能硬撐。更煩的是,很多內容還停在舊年代,好像世界只剩 monolith、SQL,外加一個 CDN 就算很潮。這種東西以前就不夠用,到了 2026 更是直接失焦。
我真正想要的其實很簡單:一頁就能幫我把思路排好,不是背答案,是把腦袋分門別類。面試官一開始追需求、接著問 scale、再來挑 consistency、retries、data modeling,你至少要有一套不會散掉的講法。我後來去看 Arslan Ahmad 的 2026 system design interview cheat sheet,把我真的會留在桌上的部分拆出來。它不是聖經,我把它當成可剪裁、可複製的實戰筆記。
不要背答案,先把腦袋排成流程
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
“System design interviews are not about reciting the perfect answer. They are about showing structured thinking under pressure.”
這句話翻成白話就是:面試官在看你怎麼想,不是在看你能不能背出 distributed systems 百科全書。我看過很多人一遇到題目就卡住,因為腦中只記得「rate limiting 要怎麼做」「chat database 要選什麼」,卻忘了先問基本問題。這就是死法。你如果只會背,題目一變形,腦子就只能當機。
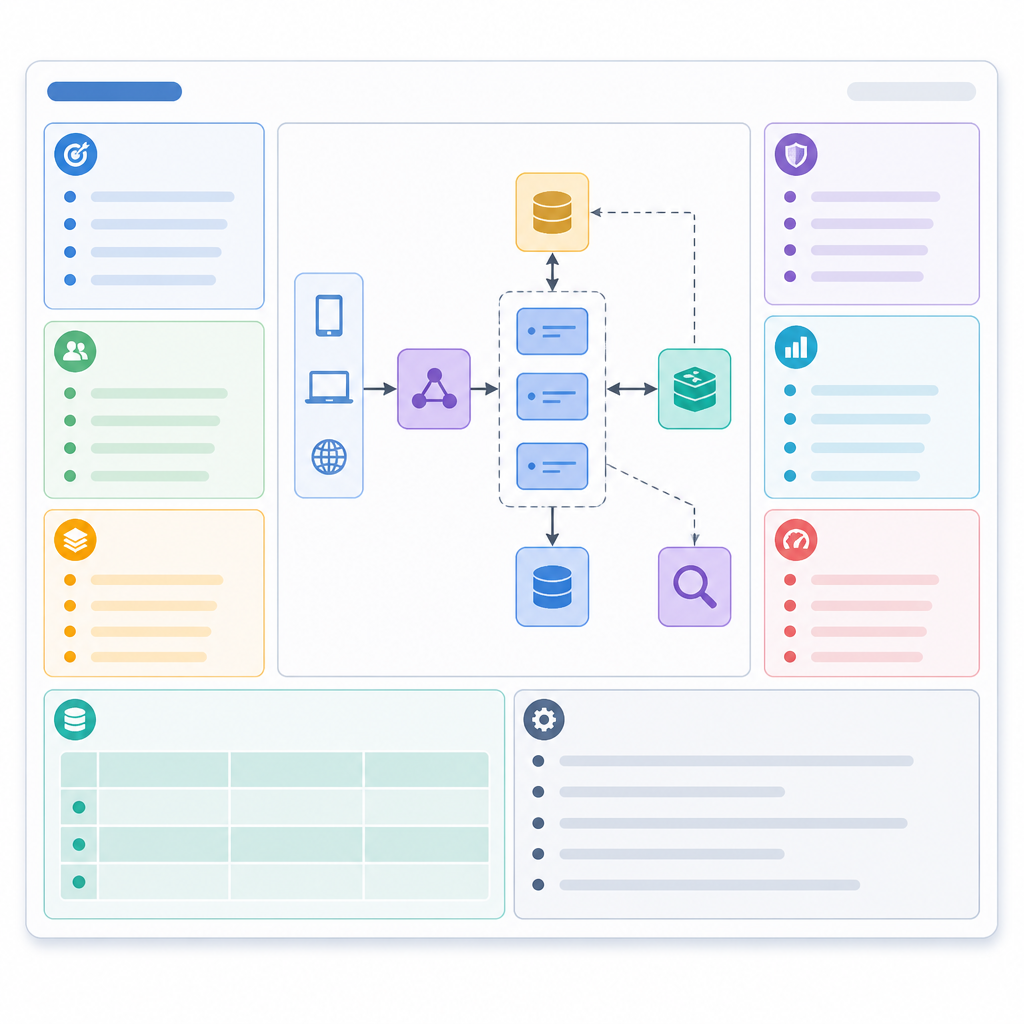
原文一直強調,這份 cheat sheet 是拿來支撐思考流程,不是拿來取代思考。我完全同意。真正答得好的候選人,通常不是架構畫得最花俏的那個,而是能先講需求、再講 scale、接著畫出夠用的高層設計,最後才談 trade-offs。這順序看起來很無聊,但它能防止你在架構表演裡迷路。
我自己的做法很土,但很有效:每題都固定同一個順序。先重述問題,再問 traffic、latency、durability、failure tolerance。接著先畫最簡單可行的設計,最後才開始優化。只要我一開始就想衝 shard 或 Kafka,通常就是我在拿複雜度蓋掉不確定感。面試官一聽就知道。
- 先問需求,不要先丟元件。
- 把 trade-off 當成答案的一部分,不要放到最後才補。
- 第一版先 boring,再慢慢加料。
這個心法重要,是因為它會改變你怎麼準備。你不會再死背 50 個零散知識點,而是開始理解各個零件怎麼串起來。這才是可用的能力。cheat sheet 只有在它讓你的思考更清楚時才有價值。
那些每題都會冒出來的核心概念
“Scalability… Availability… Reliability… Latency… Throughput… Consistency… CAP Theorem… PACELC… Idempotency… Fault Tolerance.”
這一段我建議直接狠一點看。這些詞幾乎每場系統設計都會被丟出來,而且常常被講得亂七八糟。我聽過有人把 latency 說成「系統有多快」,然後下一秒又把 throughput 講成差不多的東西。不是。我要是面試官,我不要求你背教科書定義,但我很在意你能不能把這些概念分清楚,不要混成一鍋粥。
白話翻譯一下:Scalability 是系統長大時會不會垮。Availability 是需要的時候有沒有活著。Reliability 是活著的時候會不會答對。Latency 是單次請求花多久。Throughput 是單位時間能處理多少請求。Consistency 是不同副本的資料有沒有對齊。Idempotency 是同一個請求重送會不會造成額外傷害。Fault tolerance 是零件壞掉時能不能撐住。
原文也提到 CAP 和 PACELC。我很贊成把 PACELC 一起看,因為 CAP 常常被講成萬用咒語,但實務上更常遇到的是「沒有 partition 時,你還是在 latency 跟 consistency 之間選」。這種說法比較像現在的系統,沒有那麼像十年前的部落格轉貼。
我以前做過一場 mock interview,題目是 payment flow。面試官一直追 retry。我才突然意識到,如果 payment API 沒有 idempotency,重試一次就可能重複扣款。這一個細節,整個設計就變了。Availability 跟 consistency 也是一樣,你如果講不出自己為什麼選其中一邊,那你其實還沒真的理解你畫的系統。
- 用 CAP 來講 distributed trade-off。
- 用 PACELC 補上沒有 partition 時的選擇。
- 只要有 retry 或 payment,就先想到 idempotency。
我自己的實操方式很簡單:每個詞都做一張 flashcard,只寫一句話加一個例子,不要寫作文。你如果連 consistency 都沒辦法用白話講清楚,那你現在還不適合聊 multi-region writes。
先懂 building blocks,再來談設計
“Clients… Servers… Load Balancers… Databases… Caches… Content Delivery Networks… Message Queues… Event Streams… APIs… Object Storage… Search Indexes… Vector Databases.”
這段我覺得應該貼在每個面試桌前面。這些就是每次都會出現的積木,你不懂它們各自幹嘛,設計圖一問到「為什麼放這裡」就會開始搖。
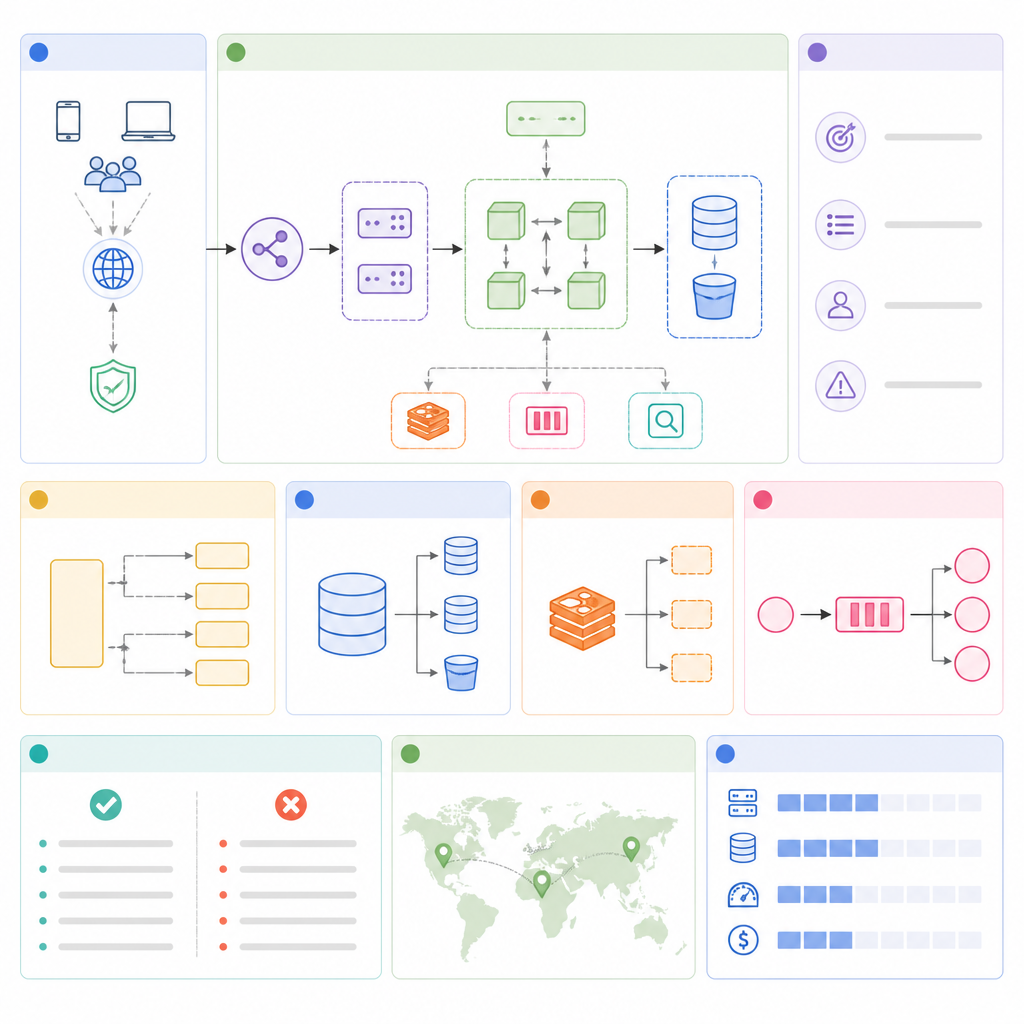
我喜歡原文的地方,是它沒有只列工具名,而是先把角色拆開。Client 負責發起請求,Server 負責處理,Load balancer 負責分流,Database 負責持久化,Cache 負責把熱資料加速,CDN 負責把靜態內容拉近使用者,Queue 負責吸收工作量,Event stream 負責持續流動的事件,API 負責定義契約,Object storage 放 blob,Search index 讓查找變快,Vector database 則是 AI 系統裡越來越常見的那塊。
原文把 vector database 拉進來,我覺得很對。只要產品有 semantic search、recommendation、RAG,或任何 AI-assisted discovery,設計裡很可能就會碰到 vector store。你可以看 Pinecone、Weaviate、Milvus。不是要你背 vendor 文件,我只是想說,現在還把 vector search 當邊角料,真的有點跟不上。
我的做法是每個元件都問三件事:它解什麼問題?拿掉會怎樣?加進來的成本是什麼?這第三題很重要,因為面試官很愛問你為什麼沒加 cache,或為什麼用 queue 不直接打服務。你如果知道每個積木的角色,這些問題就不會像陷阱,比較像正常追問。
還有一條我自己很常用的原則:如果我沒辦法用一句話講清楚一個元件,我大多不會在第一版設計就硬塞它。先把形狀畫出來,再依需求加特殊零件。這樣比較不會把自己講死。
模式不是裝飾品,是系統怎麼動的答案
“Read-heavy vs Write-heavy… Sharding and Partitioning… Replication… Pub/Sub and Event-Driven Architecture… Microservices vs Monoliths… Asynchronous Communication… Multi-Region Architecture… Real-Time Systems.”
這一段通常是候選人開始分水嶺的地方。模式不是拿來背名詞的,是拿來描述系統行為的。原文把常見的幾個大類都點出來了:讀多寫少、寫多讀少、sharding、replication、pub/sub、microservices、async、多區域、real-time。這些不是清單而已,它們是在告訴你「工作負載不同,系統長相就不同」。
白話講,如果讀多,就先想到 cache 跟 replica;如果寫多,就先想到 partition、async processing、寫入友善的 storage;如果資料太大塞不進一台機器,就 shard;如果 uptime 很重要,就 replicate;如果服務之間不要互等,就 queue 或 event;如果使用者期待即時更新,就用 persistent connection 或 push-based delivery。
我看過不少人把 microservices 講得像勳章,這真的不用。microservices 的確能換來獨立部署和獨立擴縮,但你也會同時拿到 distributed debugging、network failure、schema drift,還有一堆營運成本。原文把 monolith vs microservices 放在 trade-off 裡,這點很對。面試裡我寧可聽到「先 monolith,邊界清楚再拆」也不要聽到「因為 scale 所以 microservices」。後者通常是還沒想清楚。
實操上,我會在聽題目時先快速分類:這是 read-heavy 還是 write-heavy?需不需要 real-time updates?是不是 global?有沒有 background processing?這個分類動作很小,但它能讓你的設計不會亂飄。
- 讀多:cache、replica、precompute。
- 寫多:partition、batch、queue、簡化寫路徑。
- 即時:push updates、persistent connections、event stream。
而且 2026 的面試,multi-region 幾乎已經不是加分題,是基本題。你的使用者如果是全球分布,你的答案也要跟著全球化,不然很容易顯得像只看過單區部署的範例。
取捨才是答案,不是附註
“Consistency vs Availability… Latency vs Throughput… Speed vs Cost… Flexibility vs Complexity… Read Speed vs Write Speed… Strong Consistency vs Eventual Consistency… SQL vs NoSQL.”
這段是我最想拿紅筆劃起來的地方。trade-off 不是補充說明,trade-off 就是面試本體。誰都能列元件,強一點的人才會說清楚每個選擇換來什麼、又犧牲什麼。
原文列的幾組取捨很實用。更強的 consistency 通常意味著更多 coordination,有時候 availability 會掉。追求更低 latency,可能會犧牲 throughput,特別是你如果只盯單筆請求而不是整體批次效率。cache 和 replica 能讓系統變快,但也會帶來成本、invalidation 麻煩,以及更多維運負擔。index 會讓讀取快,但寫入會痛。SQL 給你結構與查詢能力,NoSQL 給你彈性和水平擴展。沒有哪個是白吃午餐。
我面試時真的遇過整場對話都卡在一個 trade-off。比如 feed 系統到底要不要強排序,還是先求更快送達?messaging 系統到底要不要在區域故障時維持可用性,還是要堅持即時一致?沒有完美答案。真正好的答案,是你先把取捨講出來,再說哪一邊比較符合產品需求,最後誠實承認你放棄了什麼。
我自己的實作方式是做一個超小的對照表。左邊寫決策,右邊寫代價。像是 cache 會降低 latency,但可能有 stale data;replication 會提高 availability,但寫入會複雜;sharding 會幫你擴 scale,但 cross-shard query 會變難。這種小習慣很有用,因為它會讓你的回答聽起來很落地,不像在背漂亮話。
還有一點我很在意:不要只說「it depends」就收工。這句話只有在你馬上接著說「它取決於什麼」時才有用,不然只是換一個比較體面的逃避方式。
照著固定流程走,不要臨場 freestyle
“Clarify the Requirements… Estimate the Scale… Define the API… Draw the High-Level Design… Go Deeper on the Important Parts.”
這個 framework 才是 cheat sheet 真正有用的地方。沒有流程,cheat sheet 只是漂亮名詞堆;有流程,它才會變成你穿過題目的路徑。
我自己現在都照這個順序來。先重述需求,順便問澄清問題:我們到底在做什麼?誰會用?最重要的是 latency、durability、cost 還是 consistency?接著估 scale,不用精準到像財報,但至少要有大概的 request volume、data growth、peak load。然後定 API,讓系統有明確契約。接著畫 high-level architecture。等骨架先站穩,再往 storage、cache、partitioning、delivery path 這些高風險點下鑽。
順序重要,是因為它能避免你提早優化。我看過很多人一開始就衝 database 選型,結果後面才發現自己根本沒釐清這個系統要不要強 ordering、global writes 或 full-text search。這種順序是反的。需求和 API 應該先決定 storage,不是相反。
實操上,你可以把每題都練成同一條路徑。先澄清、再估算、再定義、再畫圖、最後才深入。這樣會很像在照流程表演,沒錯,但這種表演很有用,因為它可重複。可重複,才是壓力下最值錢的東西。
如果你要一個簡短的面試口條,就用這個順序:clarify、estimate、define、sketch、deepen。很土,但真的能救命。
2026 版和舊資料最大的差別
“Concepts that mattered in 2020 are not the same ones that matter in 2026.”
我很喜歡原文把這句話講開,因為很多準備材料真的太舊。它還在用以前的直覺當預設值,卻低估了現在已經很常見的東西:multi-region 變基本盤、event-driven pipeline 到處都是、使用者期待即時更新、AI 功能把 vector search 直接塞進架構裡。
白話點說,你的回答要像 2026 的 stack,不要像博物館展品。你如果整場都沒提 event stream、async processing、vector database,答案很可能聽起來就會偏舊,就算技術上沒有錯。我不是說每個系統都要塞這些東西,我是說你要知道什麼時候該提,什麼時候該收。
我自己的做法是整理一個「2026 signals」清單。題目有 AI,我就先想到 embeddings 和 retrieval;題目有 live updates,我就想到 push delivery 和 event flow;題目有全球使用者,我就想到 region strategy 和 failure mode。這個小動作很有效,至少不會讓你用 2019 的腦袋回答 2026 的題目。
如果你現在手上還在看舊版系統設計筆記,我會建議你至少把這幾個地方更新一下。不是因為舊內容沒用,而是因為預設值已經變了。
可抄的模板
## 系統設計面試回答模板(2026 版)
### 1) 先釐清問題
- 核心使用流程是什麼?
- 使用者是誰?
- 最重要的是 latency、availability、consistency、cost,還是 durability?
- 哪些範圍是包含,哪些是排除?
### 2) 估算規模
- DAU / MAU:
- Peak RPS:
- Read / write ratio:
- 每日資料成長量:
- 儲存與頻寬限制:
### 3) 定義 API
- 主要 endpoints 或 events:
- request / response 格式:
- 是否需要 idempotency:
- 同步還是非同步:
### 4) 先選主要 building blocks
- Client
- Load balancer
- App servers
- Database
- Cache
- Queue 或 event stream
- Object storage
- Search index
- 如果有 AI / semantic retrieval,再加 vector database
- 如果有全球流量,再加 CDN
### 5) 講清楚主要 trade-offs
- Consistency vs availability
- Latency vs throughput
- Speed vs cost
- Read speed vs write speed
- SQL vs NoSQL
- Monolith vs microservices
### 6) 補 failure handling
- Retries with backoff
- Idempotency keys
- Circuit breakers
- Replication and failover
- Graceful degradation
- Monitoring and alerts
### 7) 只在題目需要時深入
- Sharding strategy
- Cache strategy
- Partition key choice
- Multi-region strategy
- Ordering guarantees
- Reconciliation / backfill
- Real-time delivery path
- Search / vector retrieval path
### 8) 最後收在 trade-off statement
-「在這個需求下,我會選 X,因為它最符合 Y。」
-「代價是 Z,但我願意接受,因為產品更在意 Y。」
### 一分鐘口條
1. 重述問題。
2. 估算規模。
3. 畫高層架構。
4. 講主要 trade-offs。
5. 深挖最風險的元件。
6. 用需求對齊你的選擇。
這段我會直接貼進自己的 prep doc。它不花俏,但它能把對話拉回正軌。面試時你要的就是這個。
原始來源:DesignGurus Substack 的 Arslan Ahmad 文章。上面這篇拆解是我根據原文整理出來的,框架、例子和可複製模板則是我自己的面試筆記化版本。