5 個生產級 Graph RAG 模式
5 種 Graph RAG 模式,幫你判斷何時用 SQL、向量與圖譜一起回答風險與依賴問題。
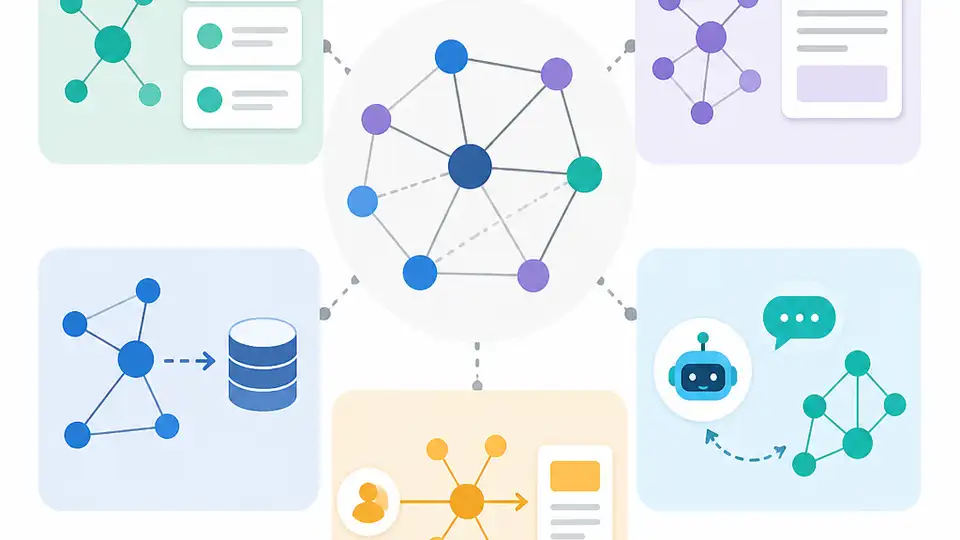
這篇整理 5 種生產級 Graph RAG 模式,幫你判斷何時用 SQL、向量與圖譜一起回答風險與依賴問題。
當資料同時有表格、文件與依賴關係時,單靠向量搜尋常會漏掉關鍵連結。看完這 5 項,你可以更快決定系統該先用圖譜、先用向量,還是兩者一起上。
| 項目 | 最適合 | 核心優勢 |
|---|---|---|
| 1. 實體圖譜優先 | 已知的人、供應商、資產 | 跨來源連結命名實體 |
| 2. 純向量檢索 | 模糊語意搜尋 | 快速找出相關文字 |
| 3. 圖譜+向量混合 | 結構化與非結構化混合資料 | 兼顧語意與關係 |
| 4. 多跳擴展 | 依賴與風險追蹤 | 沿著連結往外追查 |
| 5. 查詢時推理層 | 複雜商業問題 | 先排序證據再回答 |
1. 實體圖譜優先
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
先把人、物、地點與事件整理成圖譜,是最穩定的起點。像 Supplier A、Component X、Factory Y、Thailand 這些節點,搭配「提供」「位於」「受洪水影響」這類邊,系統就能先建立清楚骨架。
這種做法特別適合你已經有主資料、識別碼或知識圖譜團隊的情境。它讓後續檢索不只是在找相似文字,而是在找真正有連結的實體。
- 適合供應商、產品、工廠、客戶與事故。
- 跨 SQL、文件、事件流時,維持同一組 ID。
- 記錄 edge type、來源與時間戳,方便追溯。
2. 純向量檢索
向量搜尋仍然有用,尤其適合廣泛召回。若有人查「production risks」,系統很可能先撈到洪水新聞,因為語意上相近,速度也快。
問題在於,向量不會自動知道 Supplier A 供應 Component X 給 Factory Y,除非這層關係已寫進文字。當答案依賴一串事實時,單靠語意相似度常會找到對的段落,卻漏掉真正的商業含義。
- 適合模糊問題與文件探索。
- 不擅長需要精確關係的答案。
- 通常會搭配 chunking、embeddings 與 reranking。
3. 圖譜+向量混合
混合模式會先用向量找候選文本,再用圖譜驗證或擴展結果。這是很多生產環境最安全的中間解,因為它保留語意召回,也補上結構精度。
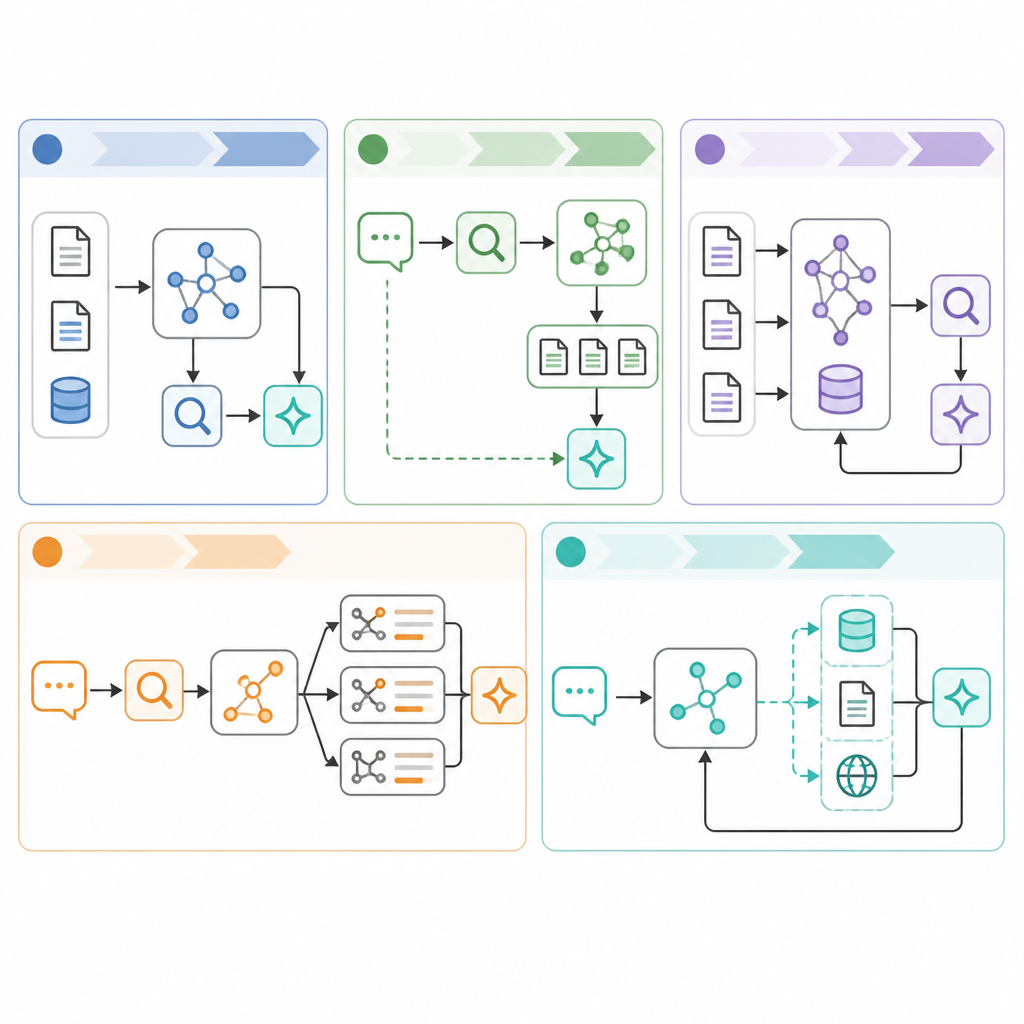
以洪水案例來說,向量層先找到新聞,圖譜再把 Supplier A 連到 Component X 與 Factory Y。系統因此能回答更有用的問題:如果 Supplier A 停止出貨,哪些工廠可能受影響?
- 先對文件與事件報告做 embeddings。
- 把抽出的實體映射到圖譜節點。
- 用圖譜邊做過濾、排序或擴展證據。
4. 多跳擴展
多跳擴展會從種子節點或文件開始,沿著關係往外走。一跳可能是 Supplier A 到 Component X;兩跳就可能到 Factory Y、庫存水位或下游客戶。
當使用者問的是依賴關係、影響範圍或根因時,這種模式特別有價值。系統不會停在第一個命中的文件,而是透過圖譜把相連事實串成更完整的答案。
Supplier A -> provides -> Component X -> used by -> Factory Y
Supplier A -> located in -> Thailand
Thailand -> affected by -> flooding5. 查詢時推理層
最後一種模式是在查詢時加入推理層,決定要做多少圖譜遍歷、向量搜尋與證據評分。這會讓生產系統更可靠,因為檢索策略會跟著問題變動。
像「發生了什麼?」這種簡單問題,也許只要一份文件加一個實體連結;但「如果 Supplier A 停供,哪些工廠有風險?」就可能需要圖譜遍歷、文件檢索與排序後的證據集合,再交給模型生成答案。
- 簡單問題走直接檢索。
- 依賴問題走圖譜遍歷加證據評分。
- 最後答案要能對應到節點與文件引用。
怎麼挑
如果你的資料大多是文字,問題也偏廣泛,先從純向量檢索開始最省力。若使用者在意供應商、資產、事故這些命名實體,就該加上實體圖譜,再用混合檢索把跨來源的事實串起來。
如果目標是風險分析、影響追蹤,或任何會問「什麼依賴什麼」的場景,多跳擴展和查詢時推理層通常最值得先做。實務上,最好的配置往往不是圖譜或向量二選一,而是圖譜加向量,再配一個清楚的路由規則。