為什麼盲測人類投票比示範片更適合排名 AI 影片模型
盲測人類比較才是 AI 影片模型排名的正解,因為它衡量的是實際觀感,不是廠商精心挑選的示範片。

盲測人類比較才是 AI 影片模型排名的正解,因為它衡量的是實際觀感,不是廠商精心挑選的示範片。
我站在盲測人類投票這一邊,因為 AI 影片的成敗不在簡報,而在觀眾是否相信畫面。LLM Stats 的影片榜單在 2026 年 5 月顯示,Kling v3 以 2127 分領先 WAN 2.7 的 1998 分與 Seedance 2.0 Fast 的 1993 分,背後是 729 票、14 個模型的盲比對。這種做法直接對準 temporal consistency、object permanence 和 motion physics 這些最常出錯的地方,也正是華麗 demo 最會遮掩的地方。
第一個論點:盲測才對應產品現實
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
影片是感知型產品,不是規格表產品。模型可以靠一支完美示範片拿下發表聲量,卻在使用者要求它固定臉部、維持鏡頭路徑或保住身體比例時全面失手。LLM Stats 的做法是把四支隨機抽樣的影片放在一起比,隱藏模型名稱,再用 TrueSkill 計分。這樣做把品牌光環和挑選過的 prompt 都拿掉,留下的是最接近真實採購決策的問題:現在到底哪個模型產出的片子更好看。
更重要的是樣本量不是裝飾品,而是判斷穩定性的基礎。729 票的盲測,不是一次性的觀感投票,而是足以拉開「偶爾驚艷」與「持續更好」差距的重複判斷。Kling v3 能守住領先,不是因為廠商說它先進,而是因為它在直接比較中贏了對手。對工程師或 PM 來說,這代表你選到的是能贏工作流程的工具,不只是能贏發表會的工具。
第二個論點:影片品質的核心是連貫性,盲測正好抓住這個失敗模式
多數人談 AI 影片時,還停留在「單幀夠不夠漂亮」的層次,但真正困難的是 temporal coherence。畫面要在幀與幀之間維持光線、主體和運動邏輯一致,不能突然切換、漂移或崩壞。LLM Stats 的說明明確點出常見失敗,包括 artifacts、突然斷裂與主體漂移,這些正是讓生成影片失去可信度、最後逼人回到後製修補的原因。榜單若不抓這些問題,就只是把美術圖連播而已。
目前的排名順序也支持這個判斷。Kling v3 排在 WAN 2.7 與 Seedance 2.0 Fast 前面,說明市場獎勵的是更能處理物理與運動的模型,而不是只會產出漂亮靜態帧序列的模型。網站的簡述也指出,Kling 在 motion physics 和 object permanence 上表現強,且成本還低於部分西方前沿替代品。這種組合才是真正可用的產品條件,因為你需要的是既能拍得像樣,又不會把預算燒穿的模型。
反方可能怎麼說
最強的反對意見是,盲測人類投票主觀、耗時,而且可能不穩定。Benchmark 可以測 prompt following、解析度或片長,指標可重複;人類 arena 則可能受口味、 novelty,或比較用 prompt 的選擇影響。如果你在做受監管流程,或需要可重現的技術系統,單靠感知投票並不完整。它也不會告訴你編輯控制、API 穩定性、吞吐量這些部署層面的問題。
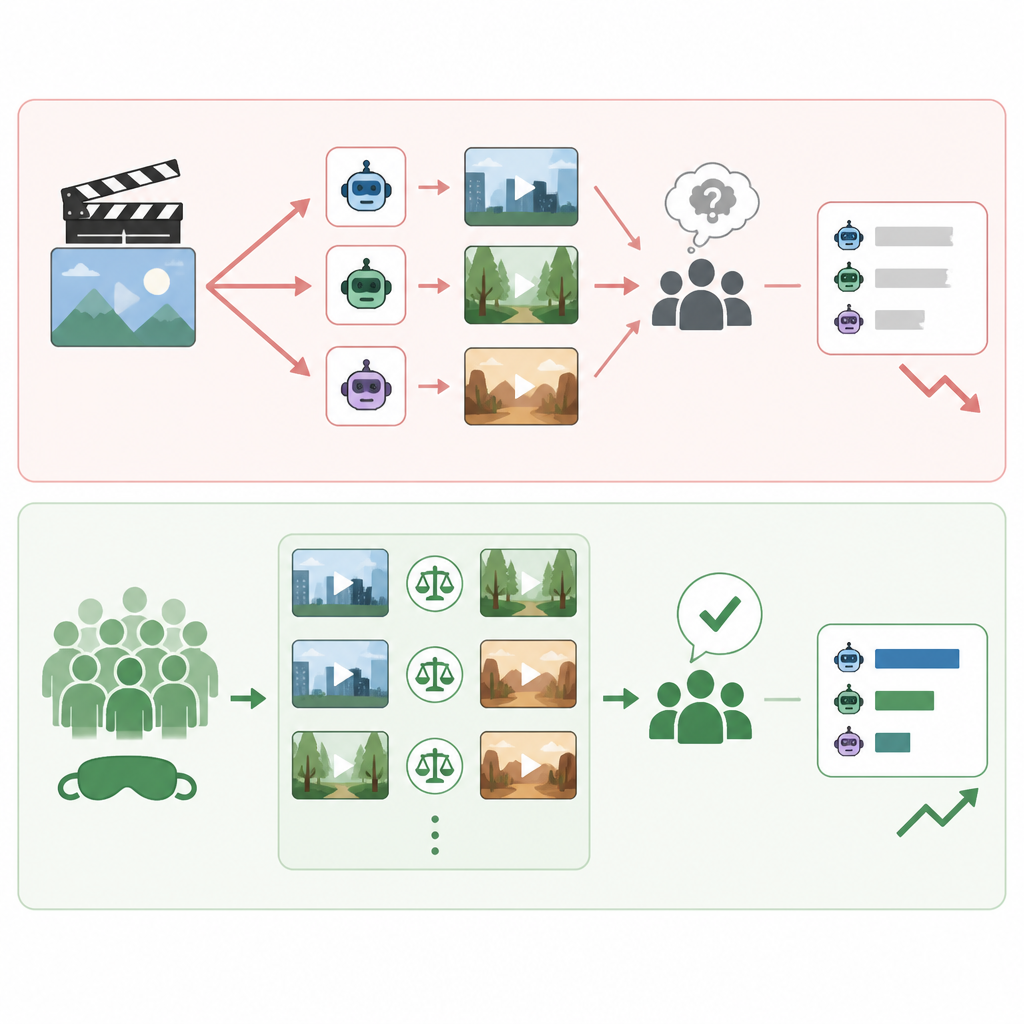
這個批評是成立的,但它只是在界定盲測的職責,不是推翻它。AI 影片本來就是感知媒介,所以主評估也必須是感知評估。Benchmark 可以補充,但不能取代對實際輸出影片的直接比較,因為使用者買的不是數字,而是能不能讓人信服的畫面。LLM Stats 透過盲比對與保守計分,已經盡量降低 cherry-picking 和單次爆表的干擾。對於選影片模型來說,這就是最合理的中心。
你能做什麼
如果你是工程師、PM 或創辦人,把榜單當第一道篩選,再用你自己的 prompt 做第二道驗證。先選你實際工作流需要的高排名模型,再拿最難的案例測它:多主體運動、鏡頭移動、object permanence、品牌資產,以及你真正要交付的片長。如果預算是限制,就先看 quality-vs-price 的視圖,再決定要不要上更貴的模型。不要先追最便宜的生成成本,除非你已經證明它能通過審核。AI 影片裡,最好的排名方式就是最能預測你會不會重做那一鏡的方式。