用因果法量化任務可學性
這篇論文證明,單看相關性會誤判任務可學性,必須用因果方法才能分辨真正是哪些資料在推動學習。

這篇論文證明,單看相關性會誤判任務可學性,必須用因果方法才能分辨真正是哪些資料在推動學習。
- 研究機構:arXiv 摘要未明確標註
- 核心數據:摘要無公開 benchmark 數字
- 突破點:binning semiring 控頻
這篇論文在講一個很實際、也很容易被忽略的問題:模型到底是因為看了多少資料才學會某個任務,還是只是剛好碰到和它相關的別種訊號。作者的答案很直接。只靠相關性去看學習曲線,會誤判。
更重要的是,這不是單純的評分方法小修小補。作者把它當成一個「量測問題」來處理。也就是說,問題不在模型有沒有學到,而在你用什麼方式判定它學到了什麼。
這篇論文想修掉什麼漏洞
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
在語言模型研究裡,大家常會問:某個任務需要多少任務專屬資料,模型才真的學會?聽起來簡單,但實際上很難回答。因為真實資料裡的任務彼此常常重疊,還會互相干擾。

如果你只看「資料頻率」和「表現」之間的關聯,很容易把學習歸因到錯的子任務。某個行為看起來是被更多資料推起來的,實際上可能是另一個一起出現的特徵在起作用。
作者認為,這不是小誤差,而是標準評估方式的結構性缺陷。也就是說,問題不是你算得不夠細,而是你本來就在問錯問題。
這個觀點對開發者很重要。因為一旦你把相關性誤當因果,後面的資料設計、課程式訓練、任務難度判讀,都可能跟著走偏。
為什麼選 formal language 當測試場
這篇不是直接從自然語言大雜燴下手,而是先把問題放進 formal language 的控制環境。作者使用的是由 probabilistic finite automata 所誘導出的形式語言。這樣做的好處,是任務結構清楚,資料生成過程也比較容易分析。
這個選擇的重點,不是說 formal language 就是最終應用。重點是它能當作一個乾淨的 testbed。你可以在這裡明確地控制任務屬性、採樣過程,然後觀察「可學性」到底怎麼被量到。
換句話說,作者是在證明一件事:就算在一個已經很乾淨的環境裡,純相關的評估也還是可能出錯。那如果把同樣方法搬到真實語料,風險只會更高。
對工程實務來說,這是個很有用的警訊。因為真實資料裡的語言現象更混雜,任務邊界也更模糊。若在沙盒裡都不穩,到了線上資料通常只會更難解釋。
方法到底怎麼做
這篇論文的核心技術點,是 Causal methods for measuring task learnability 裡提出的 binning semiring。白話一點說,這是一種代數工具,能讓研究者控制某個目標屬性在抽樣語料裡出現的頻率。
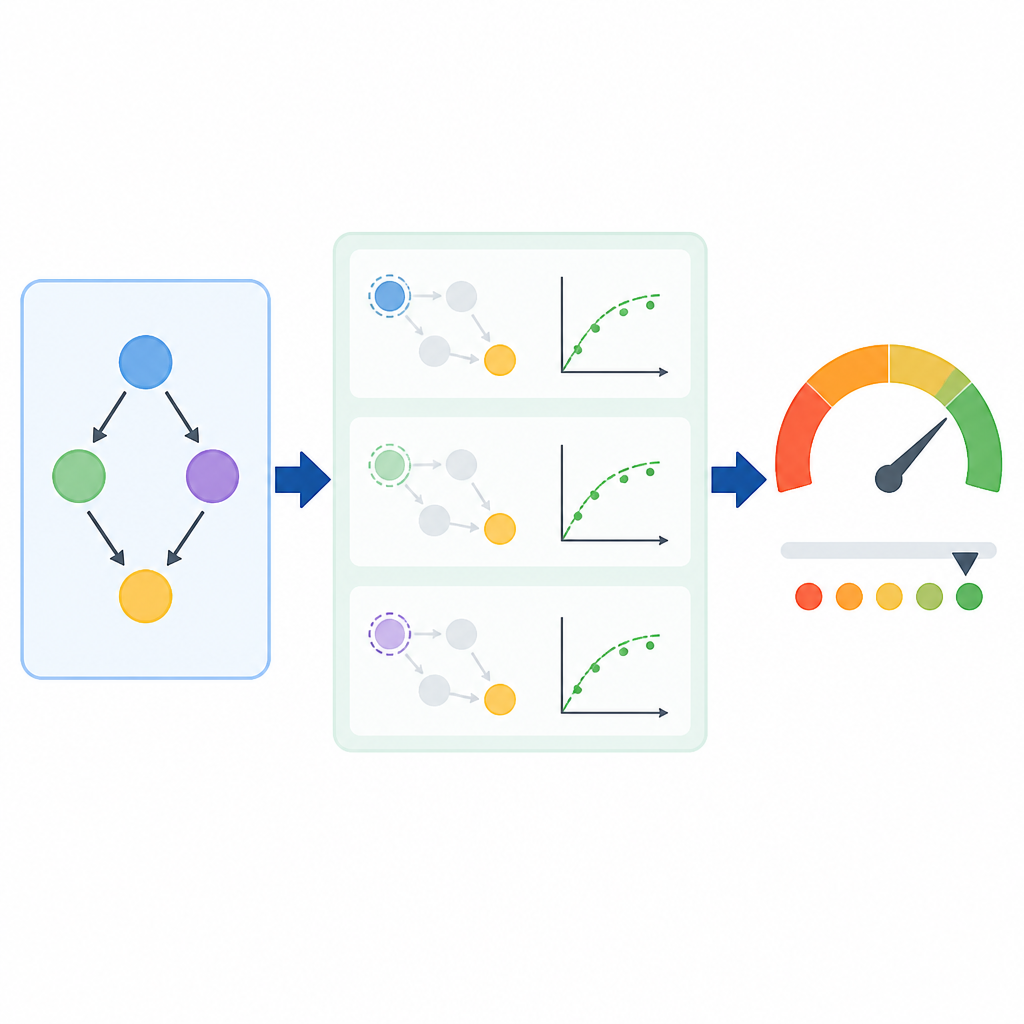
這個控制很關鍵。因為一旦頻率從「被動觀察到的現象」變成「可以調整的實驗變數」,你就能問更精準的問題:模型表現變好,真的是因為這個屬性變多了,還是只是跟它一起出現的其他因素在推動結果?
作者不只做頻率控制,還把整個流程寫成 causal graphical model。這代表他們不是把資料當成一張平面的分數表,而是明確考慮了依賴關係、混雜因子,以及從語料建構到可學性觀測值之間的因果路徑。
另外,作者還推導了分解後的 Kullback-Leibler divergence 指標。摘要沒有把完整公式展開,但方向很清楚:他們想把不同子任務的可學性拆開量,而不是把所有訊號混成一個總分。
這種設計的意義在於,它把「資料頻率」和「學會了沒」之間的關係,從描述性統計拉到因果識別。這也是整篇論文最實際的技術轉向。
論文真正證明了什麼
摘要沒有公開完整 benchmark 細節,所以看不到具體準確率、學習曲線或吞吐量數字。能確定的是,作者展示了一個方法論上的失敗案例:如果你不做因果介入,只用相關分析看 learnability,很可能會因為混雜因子而下錯結論。
這就是這篇的主結論。它不是在宣稱新的 state-of-the-art,也不是在比誰分數更高。它在講的是:你連量測方式都可能是錯的,所以後面算出來的結果也不一定可信。
這個訊息對研究者和工程團隊都很直接。很多時候我們以為自己在看「資料多寡對學習的影響」,其實看到的只是資料分布裡的共變關係。那不等於因果。
作者等於是在提醒大家:如果想知道模型到底學了什麼,就不能只看共現。你得能把真正的目標屬性,從其他一起變動的訊號裡拆出來。
- 相關分析可能把學習歸因到錯的子任務。
- 因果介入能把目標屬性的影響單獨拉出來。
- binning semiring 提供可控制頻率的採樣方式。
對開發者有什麼影響
如果你在做模型訓練、資料清理或評估設計,這篇論文其實是在提醒你:很多 metric 可能回答的是錯問題。模型看起來像是「多看資料就會進步」,但真正推動進步的,可能是某個剛好跟資料量一起上升的相關模式。
這對資料集設計尤其重要。你如果要決定下一批該收什麼資料、哪個子任務真的難、哪個課程順序比較合理,純相關讀法很容易把方向帶偏。
它也會影響 ablation study 的解讀方式。很多人做消融時,會把某個特徵拿掉,看表現掉多少,再推回去說這個特徵很重要。但如果資料裡還有別的共變結構,這種推論還是不夠穩。
更大的啟發是:learnability 不是只能被觀察,它應該被因果識別。這句話即使放到自然語言場景也成立,因為真實語料的任務邊界更糊,混雜更常見。
限制與還沒回答的問題
這篇的最大限制,是它主要停留在控制過的 formal language 場景。摘要沒有顯示它直接跑大規模自然語言 benchmark,所以它比較像是一個方法論 proof of concept,而不是完整的生產級評估流程。
另一個問題是可轉移性。binning semiring 和整套 causal pipeline,放到真實訓練語料時會不會還能維持同樣的可解釋性,摘要沒有交代。這通常才是最難的地方。
而且因為摘要沒有 benchmark 數字,這篇的價值也不是數字上的壓倒性勝利,而是概念上的修正。它提醒研究社群,先把量測方法做對,才有資格談模型到底學了什麼。
總結來說,這篇論文的重點不是讓模型更強,而是讓你更準確地知道「哪一些資料真的讓模型學會某件事」。對做資料效率、任務拆解、訓練課程的人來說,這是很值得記住的一步。