ConvexTok 把分詞器變成最佳化問題
ConvexTok 把分詞器建構改寫成線性規劃,讓 tokenization 更接近最佳解,且在常見詞彙大小下可逼近最優 1% 內。
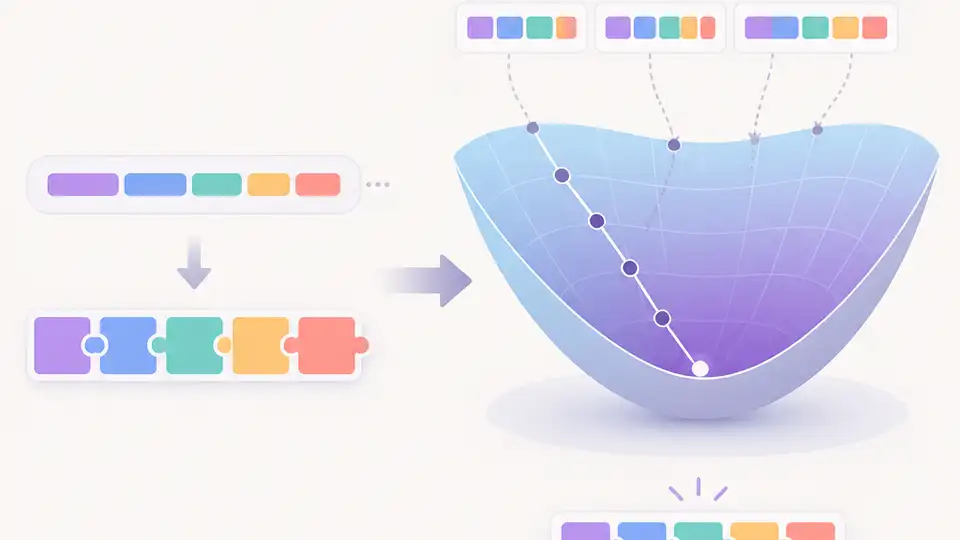
ConvexTok 把分詞器建構改寫成線性規劃,讓 tokenization 更接近最佳解。
- 研究機構:arXiv 摘要未明確標註
- 核心數據:常見詞彙大小下距最優 1% 內
- 突破點:把分詞器建構寫成線性規劃
Tokenization 平常看起來像前處理細節,但它其實會一路影響模型效率、上下文使用、訓練成本,甚至文字切得乾不乾淨。這篇論文要處理的,就是這個常被當成理所當然的環節:既然分詞器會決定後面很多資源分配,為什麼還要只靠貪婪式做法去拼出來?
ConvexTok 的主張很直接:把分詞器建構當成一個最佳化問題,而不是一個逐步試錯的啟發式流程。這個轉向的重點,不只是換一種演算法,而是把 tokenization 從黑盒子變成可以分析、可以界定距離最優有多遠的問題。
這篇論文想修的是什麼痛點
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
現有常見分詞器,例如 BPE 和 Unigram,通常是貪婪式建構。意思是,它們每一步都做眼前看起來最好的選擇,但不會把整個詞彙表的最終效果一起納入顯式最佳化。這種做法快、簡單,也夠常用,但不代表它真的接近在某個目標下的最佳解。
作者認為,這就是問題所在。當你只看局部選擇,最後得到的詞彙表可能「夠好」,卻不一定真的夠接近最優。對研究者或工程團隊來說,這種不確定性很麻煩,因為你很難知道自己是在差一點點,還是其實已經卡在方法本身的上限附近。
這篇摘要沒有把 tokenization 說成已經被徹底解決。它處理的是一個明確的目標函數,所有結論也都綁在這個目標上。這點很重要,因為它代表 ConvexTok 不是要取代所有既有分詞器,而是提供一個更有原則、也更可檢驗的建構方式。
ConvexTok 到底怎麼做
核心方法是把分詞器設計改寫成線性規劃,然後用凸最佳化工具去解。作者把這套方法命名為 ConvexTok。白話一點說,它不是一邊走一邊挑 token,而是把整個詞彙建構問題攤開來,一次找出更全局的解。
這種全局視角是技術上的關鍵。貪婪式方法的優點,是簡單而且容易實作;缺點是它只對當下做局部最佳化。ConvexTok 則是讓求解器在既定目標下,對整個詞彙表做整體權衡。它想找的不是「下一步最好」,而是「整體最划算」。
更實用的一點,是這個 formulation 帶有 certification 的味道。因為問題被寫成最佳化形式,方法可以提供一個下界,告訴你目前的分詞器離最優還有多遠。對工程團隊來說,這比單純看到一個分數更有用,因為你能判斷還有沒有繼續調整的空間。
也就是說,ConvexTok 不只是提出一個新 tokenizer,而是給 tokenization 一套可以被量化、可以被界定、也可以被檢查的框架。這讓分詞器不再只是前處理工具,而是可以被嚴格討論的最佳化物件。
這篇摘要實際證明了什麼
摘要列出的結果有三層。第一,ConvexTok 在內在的 tokenization 指標上持續改善。第二,它讓語言模型的 bits-per-byte,也就是 BpB,表現更好。第三,它也帶來下游任務的進步,但這部分沒有前兩者那麼穩定。
不過,摘要沒有公開完整 benchmark 細節。它沒有列出資料集名稱、逐項分數,也沒有提供和 BPE、Unigram 的完整對照表。所以如果你想看一眼就知道在哪些任務上贏多少,摘要本身其實不夠。
唯一明確的量化說法,是 ConvexTok 在常見詞彙大小下,實證上能做到距離最優 1% 內。這個數字很關鍵,因為它不只是說方法漂亮,而是說在實際可用的詞彙規模下,這個線性規劃式的分詞器真的能逼近最佳解。
摘要同時也保留了重要的保守語氣:下游任務的提升「較不一致」。這代表即使 intrinsic metrics 和 BpB 變好,也不保證每個工作負載都會得到同樣幅度的收益。對實務端來說,這是必須先記住的限制。
對開發者來說,這代表什麼
如果你在做語言模型訓練或微調,tokenization 不是可有可無的步驟。它會影響序列長度、記憶體使用、訓練吞吐量,還有模型從每個 byte 裡能拿到多少訊號。分詞器只要更有效率一點,整條 pipeline 都可能跟著變。
這篇論文最值得注意的地方,是它把「分詞器好不好」這件事變得更可驗證。傳統貪婪式方法常常只告訴你做出來了,但不太告訴你離理想解還有多近。ConvexTok 則試著補上這一塊,讓團隊能用更清楚的方式評估自己的 tokenizer 是否已經接近上限。
這也帶出一個更大的工程觀點:有些平常被當作 heuristic 的管線元件,其實可能有足夠結構可以直接做最佳化。這不表示每個前處理步驟都該變成凸規劃,但至少 tokenization 這件事,作者證明了它值得被更嚴肅地對待。
限制在哪裡
先講最直接的限制:摘要沒有說明完整 benchmark 細節,所以我們無法從這份 raw 資料判斷它在不同資料集、不同任務上的實際勝負幅度。這會影響你對泛化能力的判讀。
第二個限制,是摘要沒有交代計算成本、擴展性,或實作複雜度。既然方法是基於 convex optimization,工程師自然會想知道它在更大詞彙表下要花多少時間、求解是否穩定、以及能不能順利嵌進既有訓練流程。這些關鍵問題,摘要都沒有展開。
第三個限制,是下游提升不夠一致。這意味著 ConvexTok 比較像一個在特定目標下很強的 tokenization 方法,而不是保證所有模型、所有任務都會直接受益的萬用替代品。
換句話說,這篇論文最強的不是「全面取代既有方法」,而是「把 tokenization 的最佳化邊界講清楚」。對研究或工程團隊而言,這種可證明接近最優的能力,本身就很有價值,但它不等於已經解決所有實務問題。
總結
ConvexTok 把分詞器建構從貪婪式搜尋,改寫成可求解的線性規劃。摘要顯示,它在內在指標、BpB 和部分下游任務上都有改善,而且在常見詞彙大小下能做到距最優 1% 內。
但它也不是萬靈丹。摘要沒有公開完整 benchmark,計算成本與擴展性也沒有交代,下游效果還不夠一致。對開發者來說,這篇論文最重要的訊號是:tokenization 不是只能靠經驗法則做,它也可以被當成一個有明確目標、可驗證、可逼近最優的最佳化問題。
- 分詞器可以用線性規劃來建模,而不只是貪婪式建構。
- 摘要唯一明確數字是常見詞彙大小下距最優 1% 內。
- 下游任務有進步,但摘要明說不夠一致。