為什麼微調仍然勝過只靠提示詞的 AI
微調仍是把基礎模型做成可靠專用工具的最佳方法,因為它改變模型本身,而不只是包裝在外的提示詞。

微調仍是把基礎模型做成可靠專用工具的最佳方法,因為它改變模型本身,而不只是包裝在外的提示詞。
我站在微調這一邊:只靠提示詞,AI 很難在生產環境裡穩定表現;要把模型做成能重複交付的工具,還是得訓練。原因很直接,提示詞只能影響一次輸出,微調卻會把任務偏好寫進模型參數。當同一類輸入要反覆得到一致答案時,後者才是真正可控的做法。
第一個論點
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
微調之所以贏,不是因為它聽起來更「深」,而是因為它真的改了模型。大型語言模型在下游資料集上微調,通常能比基礎模型有更好的任務表現,這在 NLP 裡已是常規做法。GPT 類模型被廣泛拿去做下游微調,目的就是把通用語言能力轉成特定任務能力,這不是修飾輸出,而是重塑分布。

最具體的例子就是 ChatGPT 本身。它不是單靠提示詞堆出來的產品,而是經過後訓練與對齊的 GPT 變體。Sparrow 這類對齊系統也依賴 post-training。這些產品之所以不只依賴 prompt,是因為 prompt 很脆弱,換個寫法、換個上下文,輸出就可能漂移;微調則能把風格、規則與領域知識固定下來。
第二個論點
效率技術的流行,反而證明大家要的是訓練,不是提示詞。LoRA 之所以受歡迎,是因為它能用幾百萬個可訓練參數去適配一個擁有數十億參數的模型,並且已經被整合進 Hugging Face 工具鏈與 Stable Diffusion 生態。這代表企業與研究團隊真正想要的是「可訓練但便宜」的適配方式,而不是永遠停留在 prompt engineering。
更進一步的 ReFT 也說明同一件事。Stanford 的研究把它描述為只修改不到 1% 的表示層,仍然是在 frozen base model 上做任務特定干預。這不是對微調的否定,而是把微調做得更精準。市場一路往更窄、更省的訓練方式走,恰恰因為訓練比靜態提示更能解決真實任務。
反方可能怎麼說
反方最強的論點不是「微調沒用」,而是「微調會傷到泛化」。研究確實指出,模型一旦朝某個資料集適配,可能在分布外表現變差,甚至扭曲預訓練特徵。對通用助理來說,這是實打實的風險:模型在目標任務上更準,卻可能在其他場景變鈍。
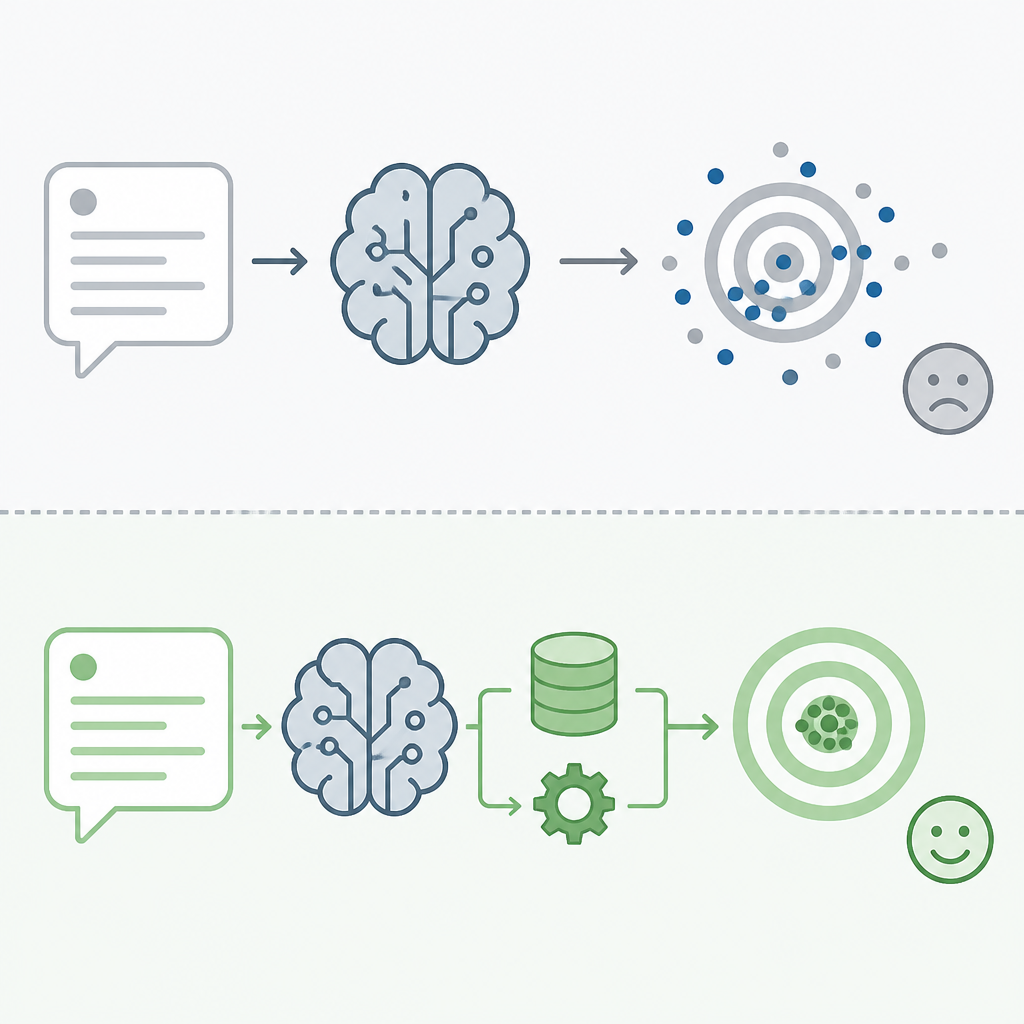
這個擔憂是真的,所以不該被輕描淡寫帶過。若你的產品目標是高度通用、快速試驗、需求還在變,prompt-only 的確更便宜,也更容易回收。微調不是萬能藥,前期資料品質差、評估不完整,反而會把錯誤寫進模型裡。
但這不構成放棄微調的理由。正確做法是承認專用化會縮窄能力,再用工程手段補回去。已有研究提出把微調後權重與原始模型做 interpolation,可在保留任務收益的同時改善分布外行為。也就是說,問題不是「能不能微調」,而是「有沒有把微調納入可回滾、可評估、可修正的流程」。
你能做什麼
如果你是工程師、PM 或創辦人,別把 prompt 當預設解法。當任務穩定、可量測、而且會大量重複時,先做微調,再決定要用全量微調、LoRA,還是更受限的 representation 方法。先建立 eval set,先測一致性與分布外表現,再把 base model 留著做回退或插值。真正該追求的不是「最會說話的模型」,而是「在你的場景裡最可靠的模型」。