Why KV-cache compression will decide edge AI inference
TurboQuant-style KV-cache compression is the real bottleneck-breaker for edge AI inference.

TurboQuant-style KV-cache compression is the real bottleneck-breaker for edge AI inference.
Verkor.io’s VerTQ TurboQuant accelerator is the right bet because edge AI does not fail on raw compute first; it fails on memory traffic, and the KV cache is where that pain compounds with every generated token.
KV cache, not FLOPs, is the tax on edge inference
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
For large language models, the cost of serving a prompt is not just matrix math. Each new token extends the KV cache, and that cache grows with sequence length, model size, and concurrent users. When the working set no longer fits cleanly in local memory, latency jumps and throughput falls. That is why a 4.3x reduction in KV cache memory requirements matters more than another incremental TOPS claim. It attacks the part of inference that gets worse the longer the conversation runs.

Google’s TurboQuant algorithm is important precisely because it targets this bottleneck directly. A 4.3x reduction is not a cosmetic optimization; it changes deployment economics. A model that previously needed a larger GPU or a server-class memory subsystem can move closer to an edge device, or support more simultaneous sessions on the same silicon. In practice, that means lower cost per request, less thermal pressure, and fewer compromises on context length.
Hardware that ignores memory pressure is already behind
The edge market has been flooded with accelerators that advertise high compute density while quietly relying on assumptions that only hold in the data center. That strategy breaks the moment real workloads arrive: longer prompts, multimodal inputs, and multiple users competing for the same memory pool. A chip that cannot keep KV cache growth under control will spend its life stalled on memory movement instead of doing useful work.
VerTQ’s value is that it treats algorithm and hardware as one system. If the accelerator is built around TurboQuant, then the design is not merely chasing benchmark theater. It is aligning silicon with the actual shape of modern inference workloads. That is the right direction for edge AI, where power and board space are fixed, cooling is limited, and every extra byte of memory has a cost attached to it.
The counter-argument
Critics will say compression is a workaround, not a solution. They are right that any quantization scheme introduces tradeoffs, and they are right that the best model still needs enough memory bandwidth to serve bursts without collapsing. They will also argue that the industry should focus on more efficient architectures rather than squeezing old ones harder.
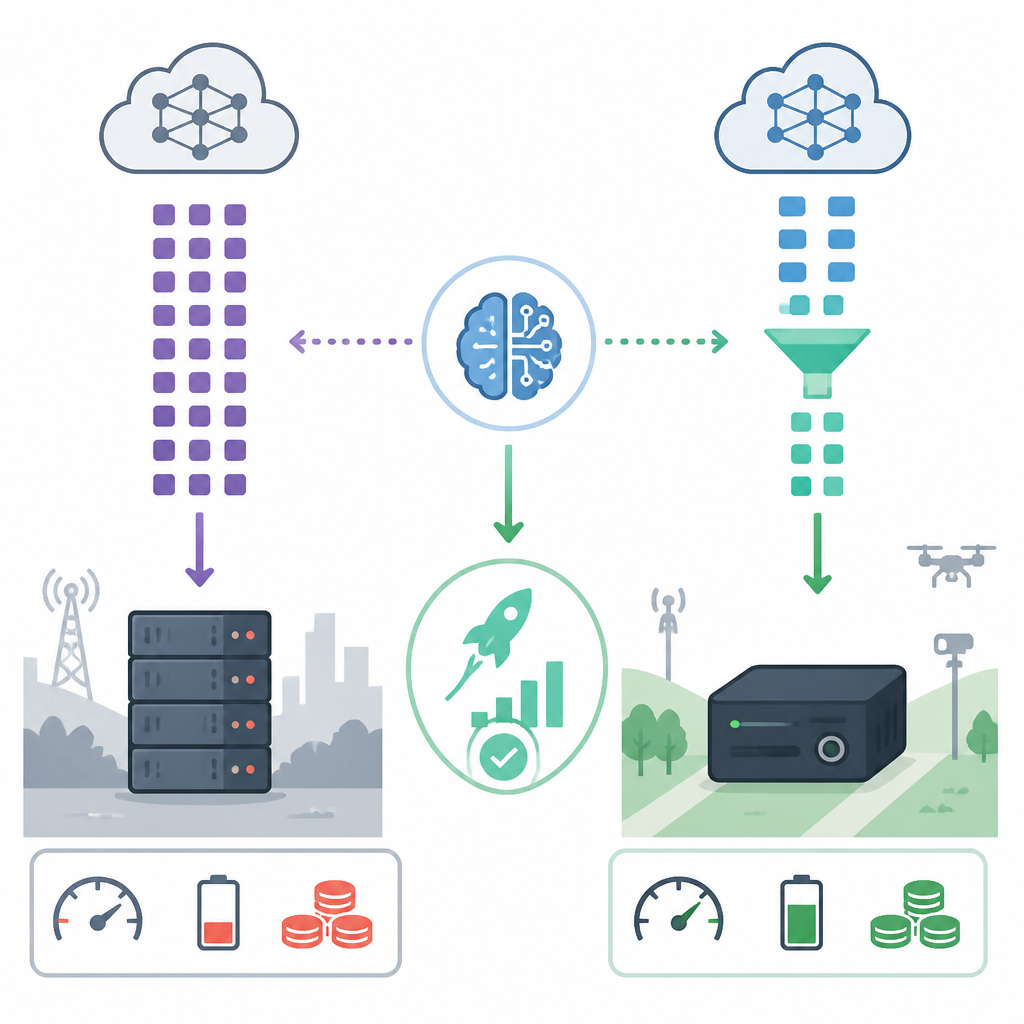
That argument misses the deployment reality. New architectures take years to mature across tooling, accuracy, and ecosystem support. KV-cache compression is available now, and it addresses a concrete bottleneck that operators face today. The limit is clear: compression does not erase the need for good hardware. But it does move the ceiling far enough to make edge inference practical for workloads that would otherwise stay trapped in the cloud.
What to do with this
If you are an engineer, stop evaluating edge inference hardware by peak compute alone. Measure sustained token latency, memory headroom under long-context loads, and concurrency at realistic prompt lengths. If you are a PM or founder, treat KV-cache efficiency as a product requirement, not an implementation detail. The winners in edge AI will be the teams that pair model-side compression with hardware that is designed to exploit it.
// Related Articles
- [TOOLS]
Magenta RealTime 2 lets you score in the DAW
- [TOOLS]
Open-source AI tools beat Claude’s paid tiers on value
- [TOOLS]
500 AI agent projects show where agents work now
- [TOOLS]
Chocolatey’s Go package turns installs into policy
- [TOOLS]
Go support policy turns releases into a checklist
- [TOOLS]
RustDesk self-hosting setup for secure remote access