為什麼 KV-cache 壓縮會決定邊緣 AI 推論
我認為邊緣 AI 推論的勝負,不會先由算力決定,而是由 KV-cache 壓縮這個記憶體瓶頸決定。

邊緣 AI 推論的關鍵,不是峰值算力,而是 KV-cache 壓縮能否把記憶體瓶頸壓下來。
我認為 Verkor.io 的 VerTQ TurboQuant accelerator 方向是對的,因為邊緣 AI 先卡住的不是 FLOPs,而是記憶體流量;而 KV cache 會隨著每個新 token 持續膨脹,最後把延遲與吞吐一起拖垮。
第一個論點:邊緣推論的真正稅金是 KV cache
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
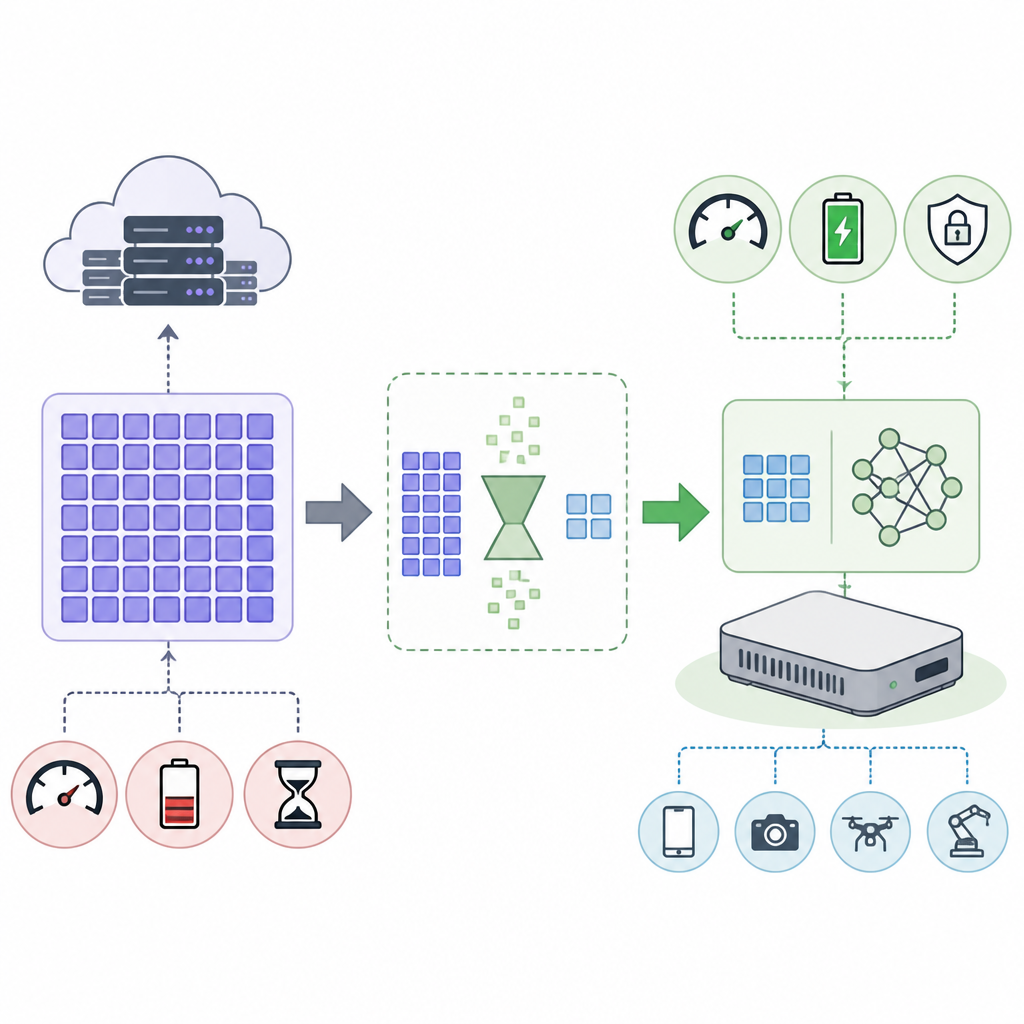
對大型語言模型來說,服務一段 prompt 的成本不是只有矩陣乘法。每生成一個 token,KV cache 就往上疊一層,序列越長、模型越大、同時在線用戶越多,記憶體壓力就越快失控。當工作集放不進本地記憶體時,延遲會突然跳升,吞吐也會掉下來。TurboQuant 把 KV cache 記憶體需求壓低 4.3 倍,意義不只是省空間,而是直接改變推論的經濟模型。

這個數字之所以重要,是因為它打到的是「會隨使用情境惡化」的成本。原本需要較大 GPU 或伺服器級記憶體系統的模型,經過 KV-cache 壓縮後,可以更接近邊緣裝置,或在同一顆晶片上支撐更多並發 session。這代表更低的每次請求成本、更小的熱設計壓力,以及更長的上下文長度可用性,而不是只在 benchmark 上看起來更快。
第二個論點:忽視記憶體壓力的硬體已經落後
邊緣市場充斥著只會宣傳高算力密度的加速器,但它們常常默默依賴資料中心才成立的假設。真實工作負載一來,長 prompt、多模態輸入、多人共享同一記憶體池,這些假設就會崩掉。若一顆晶片無法控制 KV cache 的成長,它大多數時間都會卡在記憶體搬運,而不是做有效運算。這不是小瑕疵,而是架構層級的失敗。
VerTQ 的價值在於把演算法與硬體當成同一個系統來設計。若加速器是圍繞 TurboQuant 建構,那它追求的就不是 benchmark 戲法,而是把 silicon 對準現代推論工作負載的真實形狀。對邊緣 AI 而言,電力和板面積都是固定的,散熱也有限,每多一點記憶體都要付成本,所以硬體若不把記憶體壓力納入核心設計,基本上就是走錯方向。
反方可能怎麼說
反對者會說,壓縮只是權宜之計,不是根本解法。他們也沒有說錯:任何量化或壓縮方案都會帶來取捨,最好的模型仍然需要足夠的記憶體頻寬來應付突發流量。另一個常見批評是,產業應該去設計更有效率的新架構,而不是一直把舊架構硬擠出更多空間。
但這個論點忽略了部署現實。新架構要成熟,通常得花好幾年才能跨過工具鏈、精度和生態系的門檻。KV-cache 壓縮是現在就能用的手段,而且它直接對準運營者今天已經遇到的瓶頸。它的限制也很清楚:壓縮不能消滅對好硬體的需求;但它能把可行性門檻往下推,讓原本只能留在雲端的工作負載,開始有機會落到邊緣端。
你能做什麼
如果你是工程師,別再只看 edge inference 硬體的峰值算力;請改看長上下文下的穩態 token latency、記憶體餘裕、以及真實並發數。如果你是 PM 或創辦人,把 KV-cache 效率當成產品需求,而不是實作細節。邊緣 AI 的贏家,不會是單純跑分最高的團隊,而是能把模型端壓縮和硬體端設計一起做對的人。