為什麼 RAG 比 Prompting 更適合私有資料
RAG 才是回答私有、常變資料的正確架構,因為它把知識放在檢索層,而不是賭模型記得住。
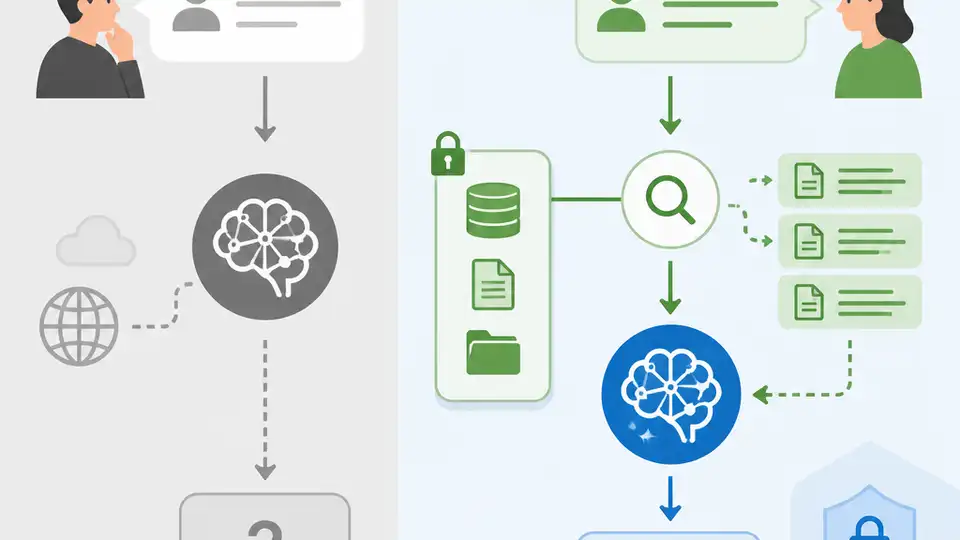
RAG 才是回答私有、常變資料的正確架構,因為它把知識放在檢索層,而不是賭模型記得住。
我站在這一邊:只要你的問題來自公司文件、內部知識庫、政策文件或最新事件,RAG 就比純 Prompting 更可靠。原因很直接,LLM 的強項是生成,不是記住你沒訓練過的私有內容;一旦資料更新,靠提示詞硬問只會把模型推向猜測。OpenAI、Anthropic、Google 這類模型再強,也不會自動知道你昨天改了哪條 SOP。
第一個論點
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
Prompt-only 的核心問題是它把「找答案」和「寫答案」混成同一件事。當模型面對 Slack 訊息、Jira ticket、內部 wiki 這些訓練外資料時,它沒有真正的記憶,只能根據上下文拼湊回應。這也是為什麼企業場景裡最常見的失敗不是文法錯,而是事實錯;一份 500 頁手冊不可能被塞進上下文視窗後還維持穩定品質。
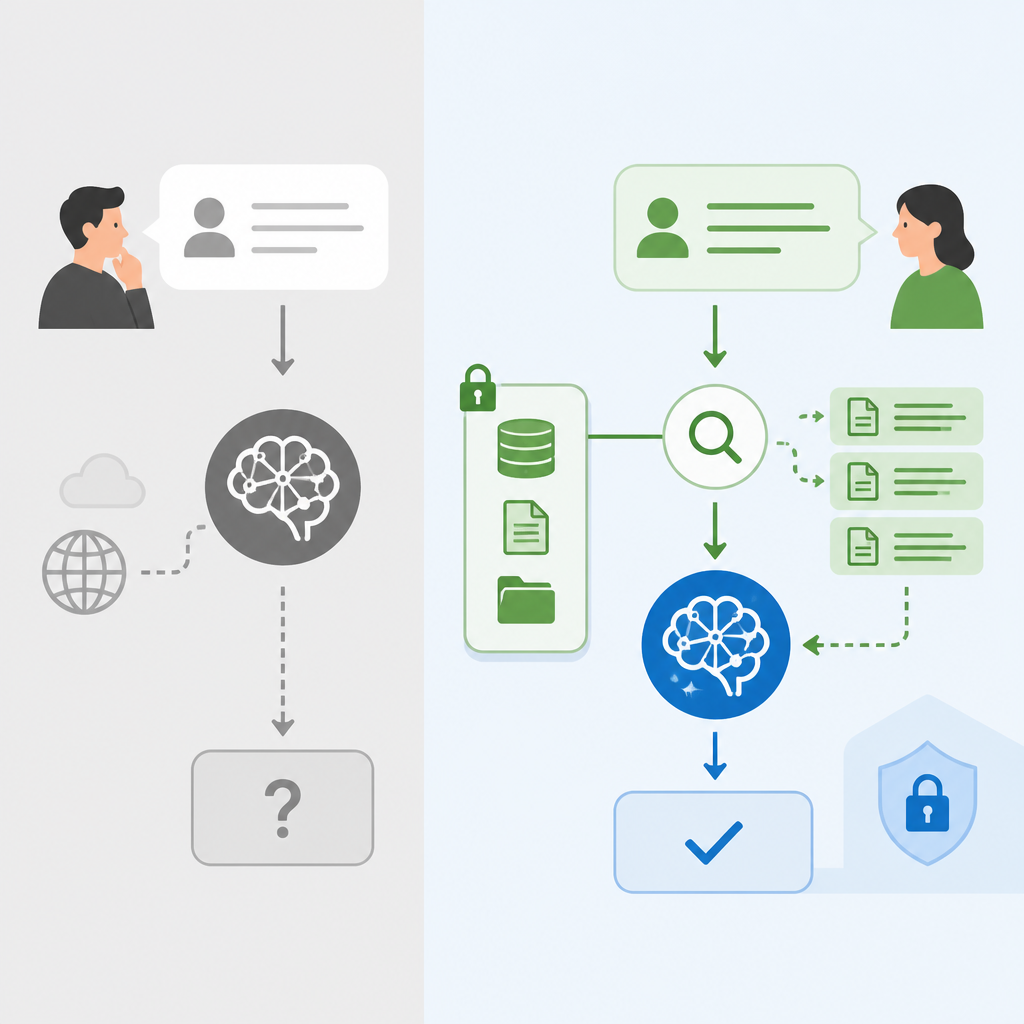
RAG 的優勢在於它先檢索再生成,把問題改寫成「先找到相關片段,再根據片段回答」。這不是理論上的漂亮說法,而是工程上的必要條件。像 ChromaDB、Pinecone、Weaviate 這類向量資料庫,配合 chunking 與 embeddings,能把大文件拆成可搜尋單位;實務上,當文件從 10 頁變成 1,000 頁時,Prompting 的成本和失真都會同步上升,RAG 才能維持可用性。
第二個論點
對私有資料來說,RAG 也比 fine-tuning 更符合成本結構。Fine-tuning 的問題不是不能做,而是它把「知識更新」綁死在模型權重裡。若你的政策每週都在變,或產品文件每天都在改,為了補一條新規則就重訓一次,既慢又貴。相較之下,RAG 只要更新來源文件、重新索引,系統就能立刻反映新內容。
這也是為什麼很多內部助理、客服知識庫、法務文件搜尋系統最後都走向 RAG。它保留了 LLM 的語言能力,卻把事實依據交給檢索層。以一個常見案例來看,團隊若要做「chat with PDF」,用 Python 加 LangChain 或 LlamaIndex,再接一個向量庫,通常比訓練一個專用模型更快上線,也更容易審計答案來源;對需要可追溯性的企業,這點比花俏的生成能力更重要。
反方可能怎麼說
反對者的論點其實不弱。RAG 會失敗,因為檢索本身就可能錯:chunk 切得不好、embedding 品質差、召回不到關鍵段落,最後模型還是會拿著不完整上下文胡說八道。再加上 RAG 系統多了 loader、splitter、向量庫、reranker、prompt template 這些元件,整體複雜度比一段 prompt 高很多。
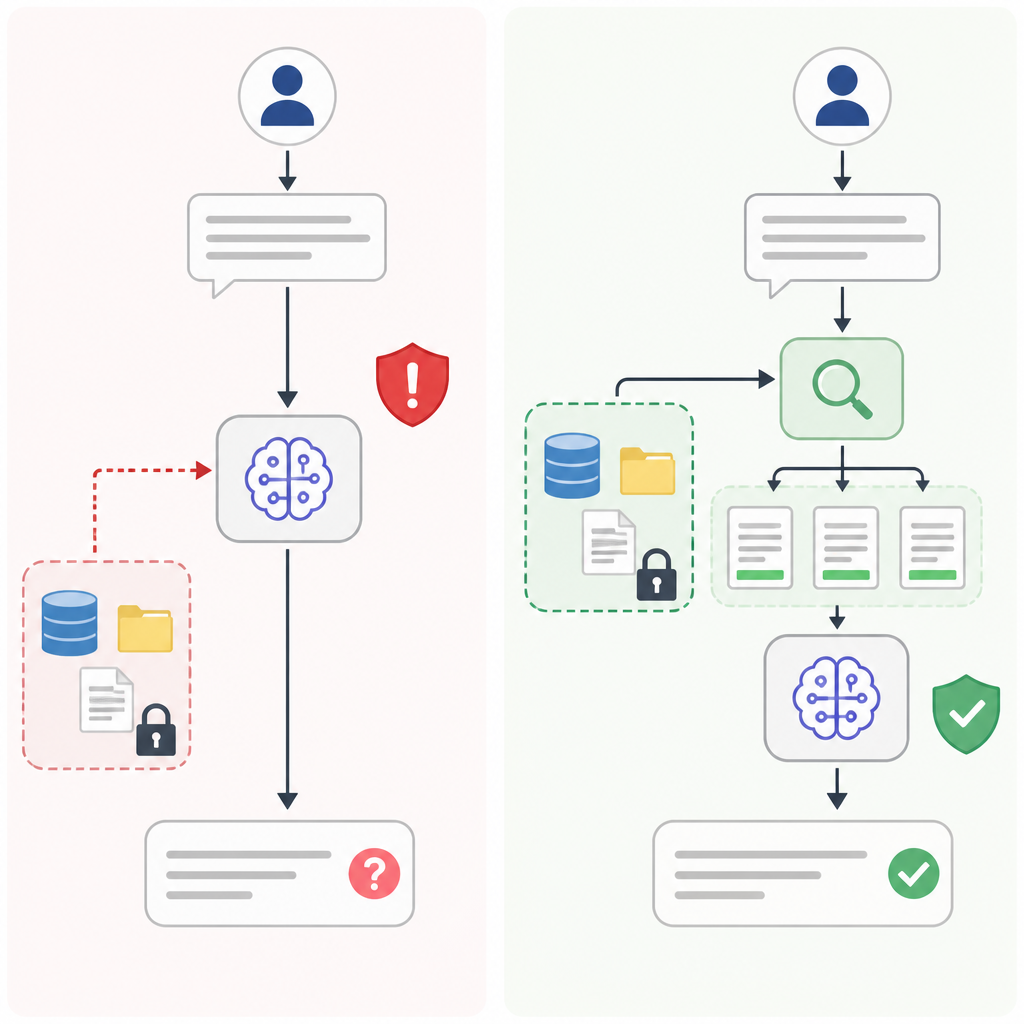
這個批評在原型階段尤其成立。若你只有一份短文件,或只是做一次性分析,直接 prompt 的確更快,甚至更省事。問題在於,這種情境不構成反對 RAG 的理由,只是說明你現在還不需要它。
真正的分界線是資料是否私有、是否常變、是否需要可追溯。只要答案必須對齊來源,而且來源會更新,prompt-only 就會把風險留在模型幻覺裡;RAG 雖然多一層工程,但它至少把錯誤限制在可觀測、可修正的檢索流程中。
你能做什麼
如果你是工程師,別先做 UI,先做檢索品質:把文件來源整理乾淨,刻意設計 chunk 大小,測試 top-k 召回是否真的找到正確段落,再決定要不要加 reranking。如果你是 PM 或創辦人,把 RAG 用在「文件會變、答案要有依據」的場景,例如政策查詢、產品手冊、法務條款、客服知識庫;這些地方才有明確 ROI。不要試圖讓模型記住你的私有知識,應該讓系統把知識找對,再交給模型說清楚。