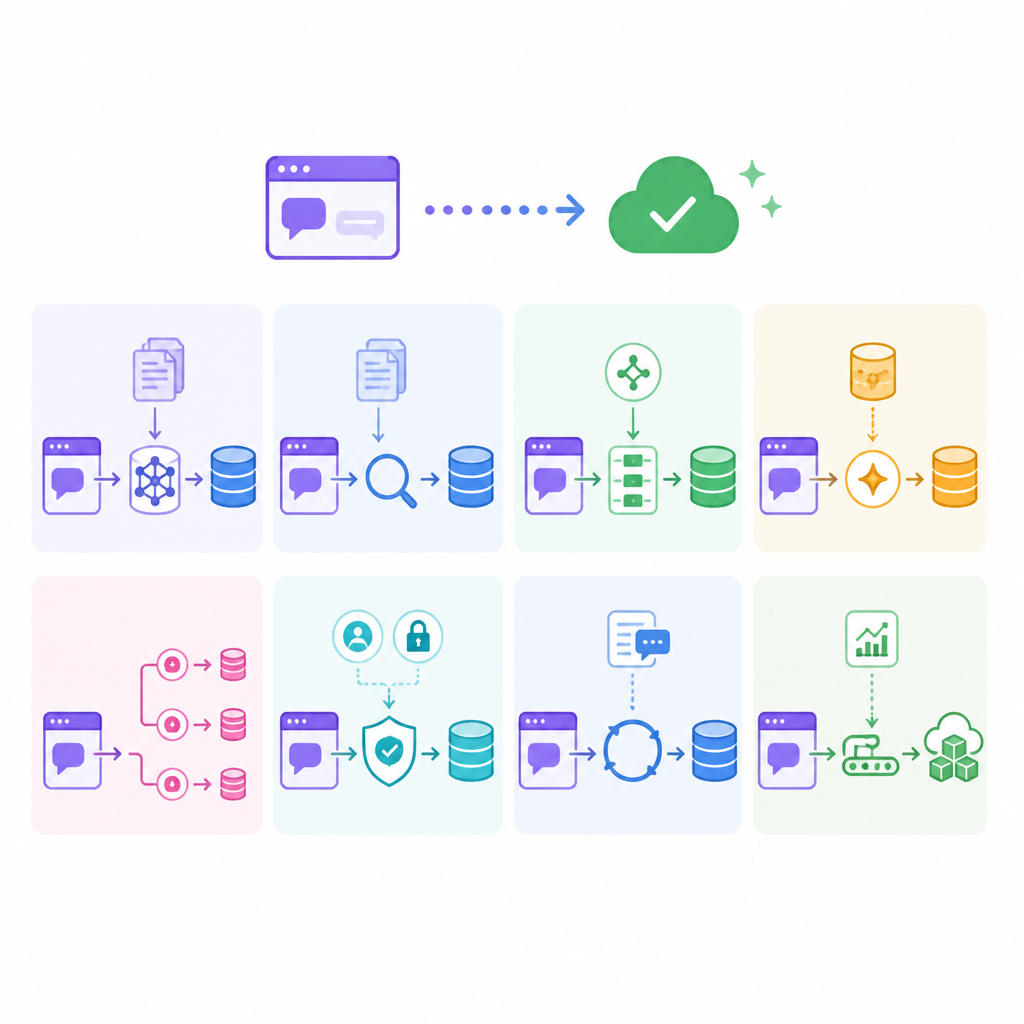
8 種 RAG 模式把 Demo 變上線
我把 8 種 RAG 架構模式拆開講,順手給你一份可直接抄走的選型模板,避免 demo 很漂亮、上線就失控。

我把 8 種 RAG 架構模式拆開講,順手給你一份可直接抄走的選型模板,避免 demo 很漂亮、上線就失控。
我最近一直在看 RAG 系統,越看越火大。demo 階段真的很容易:向量、切塊、檢索、塞進 prompt,畫面漂亮到不行。可是真人一來,問題就開始髒了:半個型號、拼錯字、一次問兩件事、答案要跨四份文件才拼得起來。這時候模型還是很有自信,只是自信得不對勁。更煩的是,很多團隊把這種失準怪給模型,卻沒先看檢索到底爛在哪裡。
我想拆的不是「RAG 是什麼」,而是「RAG 其實有很多種做法」。我看過太多人一開始就想上 agent、上 graph、上更大的模型,結果先把最基本的檢索問題拖到最後才補。那種做法很像先買跑車再去學怎麼轉彎,燒錢又難看。這篇就是把我整理出來的思路講白:每一種模式到底在補哪種洞、代價是什麼、我會在哪裡停手。
這份拆解的觸發來源是 Navneet Bhalodiya 在 AIThinkerLab.com 寫的文章,原文把 8 種 RAG 模式和選型邏輯整理得很清楚。文中也提到 RAG About It 在 2026 年 5 月轉述的一組生產部署數據:把 agentic pipeline 搭配 knowledge graph 後,幻覺率大約降了 62%,樣本是 47 個 production deployments。這數字有參考價值,但前提是你知道它解的是哪一類問題。
別再把 RAG 當成單一路線
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
RAG 已經不是單一 pipeline,而是一組解不同失敗模式的架構模式。
我先翻譯一下:你如果還把 RAG 當成「向量檢索 + 生成」那一套,很多問題你根本看不見。最基本的 retrieve-and-generate 只能處理「找得到相關段落,然後照著答」這種題目。只要你的使用者開始用縮寫、型號、跨文件比對、或需要多跳推理,這條管線就會開始漏水。人家以為是模型不夠聰明,實際上常常是檢索形狀錯了。

我自己最常看到的錯法,是團隊一直調 prompt、一直換 model,卻沒先問:到底是找不到、找到了排太後面、還是找到了但上下文不夠?這三件事是完全不同的問題,卻常被混成一句「RAG 不準」。
實操寫法很簡單:不要先問「我要用哪種 RAG」,先問「我的失敗模式是什麼」。把 query、retrieved chunks、final answer、是否 grounded 全部記錄下來。你連失敗長什麼樣都說不出來,就先別急著加複雜度。你不是在做架構升級,你是在幫自己堆裝飾品。
- 先看失敗模式,再選架構。
- 先做可觀測性,再談進階模式。
最土的 naive RAG,通常還是第一步
把文件切塊、做 embedding、存進向量庫,查詢時再 embedding 一次,把最近的幾塊塞進 prompt。
這就是教科書版 naive RAG。老實說,它還是該先上場的版本。FAQ、乾淨的政策文件、簡單查詢,這種場景用 naive RAG 就夠了,便宜、快、好理解。你不用一開始就把整個系統搞得像研究計畫,先讓使用者有東西可用比較實際。
但它的天花板也很明顯。切塊永遠是取捨:切太小,脈絡斷掉;切太大,檢索又變糊。dense retrieval 對語意很強,對精確字串很弱,所以它很容易漏掉錯誤碼、料號、法條、產品名稱這種人類一眼就能 Ctrl+F 找到的東西。然後模型就會很自然地補一個看起來合理、其實不對的答案。
我之前做過一個客服助理,大家一直抱怨「它都找不到對的文章」。模型不笨,問題在檢索。我們 embedding 做得不差,prompt 也沒爛,但使用者一直輸入代碼和縮寫,語意向量就是會把它們糊在一起。最後真正救場的不是更大的模型,是 sparse search。
- 文件小、乾淨、問題單純,就先用 naive RAG。
- 把它當 baseline,後面升級才知道有沒有真的變好。
實操寫法:先做最簡版,但一定要把失敗攤出來。記錄 recall@k、答案是否 grounded、以及「沒答對」的案例。你如果分不出是檢索沒撈到,還是模型看了也不理,那你就是在盲修。
Hybrid retrieval 是補 embeddings 最常漏的洞
Hybrid retrieval 把 dense vector search 和 sparse keyword search(BM25)一起用,再把兩邊結果融合。
這招我真的希望更多團隊早點用。dense retrieval 擅長語意,sparse retrieval 擅長精確字面。企業資料通常兩種都需要。只要你的 corpus 裡有產品代碼、名稱、縮寫、工單編號、法條這些東西,純語意搜尋就是在漏錢。
白話講,不要逼 embedding 去做它不擅長的事。讓 BM25 負責字面命中,讓 vector search 負責語意相近,再用像 Reciprocal Rank Fusion 這種方法把結果合併。這樣在 LLM 看到上下文之前,你就先把候選集弄得像樣很多。很無聊,但通常很有效。
我跟不少團隊吵過這件事。很多人一開始都想追求「更聰明」的檢索,結果其實他們根本是基本檢索沒做好。Hybrid search 上了之後,系統常常只是比較常找到明顯正解,使用者體感就差很多。這種改善很樸素,但是真有用。
- 只要精確字串和語意都重要,就該考慮 hybrid retrieval。
- 特別適合有術語、代碼、專有名詞的資料庫。
實操寫法:先把 BM25 加進來,再談更多 LLM 呼叫。如果你的向量資料庫原生支援 hybrid search,直接用;不支援就分開跑兩個 retriever,再做結果融合。然後拿真實查詢去比,不要拿你自己精心挑的十題 demo。
Reranker 才是把「差不多」變成「真的對」
先撈一大批候選,再用 cross-encoder reranker 重新排序,按真正相關性排。
這一步很多人嫌麻煩,因為它看起來像多一道工。但我反而覺得,這就是把系統從「大概有找到」拉到「真的有找到」的地方。第一階段檢索負責召回,reranker 負責精排。只要正解在前 20 名裡,但不在前 3 名,reranker 常常就能把它救回來。對 RAG 來說,這差很多,因為最後塞給模型的上下文本來就不多。
翻成白話就是:不要幻想 embedding 自己就能決定最終相關性。cross-encoder reranker 會把 query 和候選內容一起看,所以它對「這段到底有沒有真的回答問題」的判斷通常比純向量更準。很多時候,比起換更貴的 embedding 模型,先加 reranker 更划算。
我喜歡 reranking 的原因很簡單:它讓系統沒那麼飄。沒有 reranker 時,檢索有時候很玄,答案明明在候選裡,卻剛好沒進你送給模型的那幾段。有 reranker 之後,你是在用一點延遲換很多精度。只要你不是卡在極端嚴格的 p99,這筆交易通常值得。
實操寫法:先廣撈,再精排。可以先抓 top 20 到 top 50 候選,再把前幾名丟給生成。看你的「答案是否存在於檢索上下文」比例有沒有上升。如果有,reranker 就留著;如果沒有,問題多半還在更前面。
Query transformation 是在補人類問法太爛
把使用者輸入先改寫,再拿去檢索;可以擴寫、拆成子問題,或先生成假想答案再去找。
這個模式之所以存在,是因為人類真的不會好好問問題。我不是要罵使用者,因為我自己也常這樣問:一句話塞兩個需求、指代詞一堆、縮寫滿天飛,還期待系統自己懂。它通常不懂。
白話一點說,就是先把 query 整理過再檢索,讓 retriever 比較有機會命中。你可以展開縮寫、把複合問題拆成多個子查詢,或用 HyDE 先生出一段假想答案,再拿那段去做 embedding。這樣比直接拿使用者那句半成品去搜,通常更好。
我之前碰過一個支援流程,大家一直問很模糊的問題,檢索就是抓不到。後來我們不是改 corpus,而是先把 query 拆小,命中率就上去了。這種修法我很愛,因為不用重建索引,也不用整套推倒重來。
- 使用者常問得很糊、很長、很混,就考慮 query transformation。
- 不要預設每個 request 都要改寫,否則延遲和失敗點都會一起上升。
實操寫法:只針對複合問題、指代不清、縮寫很多的 query 做轉換。不要每次都改寫,否則簡單查詢會被你弄得像在走手續。能省就省,該拆才拆。
GraphRAG 不是萬靈丹,它只適合關聯型問題
GraphRAG 會從語料抽出實體與關係,建成知識圖譜,再做社群摘要。
這東西很容易讓人上頭,因為它看起來很像「資料終於被整理好了」。但我先講結論:GraphRAG 不是拿來取代一般檢索的,它是拿來處理「你要把很多文件裡的關係串起來」這種題目。也就是說,問題不是找一段,而是把散在各處的事實接起來。
這就是平面檢索和圖檢索最大的差別。平面檢索是局部的,圖檢索是關聯的。如果使用者問的是多份報告裡反覆出現的實體、跨文件的關係、或主題如何演變,那圖結構就會比單純語意相似更有用。
Microsoft 在 2024 年 7 月把 GraphRAG 開源,做法包含 LLM 驅動的 entity extraction 和 Leiden algorithm 做 community detection。這套東西不是輕量方案,建置和維護成本都高,所以我不會在問題還能靠更好的 retriever 和 reranker 解決時,就急著上圖。
實操寫法:只有當你證明「跨文件綜合」才是瓶頸時,才考慮 GraphRAG。若問題本質只是單文件問答,或加一個 reranker 就夠,那就別把自己拖進圖譜維護地獄。架構圖畫得漂亮,不代表產品會比較好用。
Agentic RAG 很猛,但也很貴
Agentic RAG 把控制權交給推理迴圈:模型自己拆問題、挑工具、查資料、檢查結果、再迭代。
這種模式最容易被濫用。因為它聽起來很聰明,像是系統終於會「自己想辦法」了。確實,對多跳研究、深度調查、複雜工作流來說,agentic loop 很有價值。當單次檢索不夠時,它可以規劃、搜尋、驗證、再來一次。
但代價也很直接:延遲更高、token 更多、漂移點更多、除錯更痛。原文提到一組 2026 年 5 月的 benchmark,說把 agentic pipeline 搭配 knowledge graph 後,在 47 個 production deployments 裡幻覺率大約降了 62%。我會把它解讀成:當任務夠複雜、流程設計也夠嚴謹時,迭代式編排確實能少出很多爛答案;但這不代表 agent 可以拿來當預設方案。
我看過不少團隊把 agent 當成「讓系統更會想」的捷徑。這通常是錯的。檢索爛的時候,agent 只會把爛檢索放大成更貴的爛檢索。如果問題只需要一兩份文件,agent 反而是過度設計。
實操寫法:先定義哪些 query 類型真的需要多步推理,再幫它設預算,包含 latency、token、retry 次數。然後測它是不是比簡單版本更 grounded。沒變好就拿掉。我知道這話很硬,但我寧可上線一個無聊但穩的系統,也不要一個很會演、但常常亂講的系統。
Multimodal RAG 是給文字以外的知識
Multimodal RAG 不只檢索文字,也檢索圖片、表格、音訊和影片。
文字型 RAG 很好用,但前提是你的資料真的都在文字裡。只要來源開始包含維修照片、掃描表格、產品圖、通話錄音、影片片段,硬把它們當成段落處理,就會很卡。這不是模型不夠強,是資料型態根本不同。
白話講,就是檢索層要能理解多模態,而不是只會 embed 文字切塊。這會影響索引方式、儲存方式、評估方式,還有一堆新的失敗模式。它有用,但維運成本比純文字版高不少,不適合一開始就亂上。
我會把 multimodal RAG 當成特化模式。如果你的知識有一大塊本來就不在文字裡,那值得做;如果只是少數邊角案例,就別為了看起來很厲害而硬上。很多團隊其實只是想把架構做得很忙,結果產品沒比較好。
- 來源有圖片、表格、音訊、影片,就該考慮 multimodal RAG。
- 它的索引、評估、監控成本都比純文字高。
實操寫法:先盤點你的資料來源。答案如果真的要靠截圖、圖紙、錄音,那就提早規劃 multimodal;如果不需要,就維持 text-first,少踩一堆坑。
可抄的模板
# RAG 架構選型模板(可直接貼到團隊文件或 PRD)
## 1) 先看失敗模式
- 如果使用者常找不到精確名稱、代碼、ID、法條:先加 hybrid retrieval
- 如果正解有撈到,但排序不夠前面:加 reranker
- 如果問題常常很模糊、很長、一次問兩件事:加 query transformation
- 如果錯答案代價很高:加校正或自我檢查步驟
- 如果答案要跨很多文件才能拼起來:評估 GraphRAG
- 如果單次檢索不夠,需要多步查詢與驗證:評估 agentic RAG
- 如果來源不是只有文字:評估 multimodal RAG
## 2) 建置順序
1. 先做 naive RAG baseline
2. 先加 hybrid retrieval(dense + BM25)
3. 再加 reranker
4. 只有在 query 很髒時才做 query transformation
5. 高風險領域再加 relevance grading / abstention
6. 跨文件綜合需求明確時再上 GraphRAG
7. 需要多步工具使用時再上 agentic RAG
8. 真的有圖片、表格、音訊、影片再做 multimodal RAG
## 3) 決策欄位
- 語料規模:____________________
- 查詢類型:____________________
- 是否依賴精確字串:____________
- 是否需要跨文件推理:__________
- p95 / p99 延遲預算:___________
- 每次查詢成本上限:____________
- 是否需要可追溯性:____________
- 是否有非文字來源:____________
## 4) 預設技術選擇
- Embedding:先用穩定的通用模型
- 多語系 / 開源取向:選擇支援多語言的 embedding 模型
- 小到中型資料:Postgres + pgvector
- 較重的過濾與規模:Qdrant、Weaviate 或 Pinecone
- 排序:先廣撈,再用 cross-encoder reranker 精排
- 改寫:只對模糊或複合查詢啟用
## 5) 路由規則
IF query 包含代碼、ID、名稱、精確詞
THEN 先跑 hybrid retrieval
IF 前幾筆結果語意接近但不真的相關
THEN 對前 20-50 筆做 rerank
IF query 有多個子句或指代不明
THEN 拆成子查詢再檢索
IF 答案必須 grounded 且錯答案代價高
THEN 加 relevance grading 與 abstain path
IF 問題需要跨多份文件綜合
THEN 試 GraphRAG
IF 問題需要多步工具使用或多跳推理
THEN 用 agentic RAG,但要設嚴格預算
IF 來源包含圖片、表格、音訊、影片
THEN 用 multimodal retrieval
## 6) 上線守門
- 記錄原始 query、改寫後 query、檢索結果、rerank 結果、最終答案
- 追蹤 grounded rate 和 citation coverage
- 量測 recall@k、MRR、延遲、每次查詢成本
- confidence 低時要有拒答路徑
- embedding、切塊、retriever 一改就重跑評估
## 7) 我的預設建議
- 先用 naive + hybrid retrieval
- reranker 先加,agent 後加
- query transformation 只給髒 query
- GraphRAG 和 agent 只在證明真的需要時才上
- multimodal 只有在資料型態真的需要時才做
這段就是我會直接丟給團隊的版本。它逼大家不要再問「現在最潮的是哪一種架構」,而是回到「我們到底在修哪一種失敗」。這個問題換對了,很多時間就省下來了。也能避免你把系統做得很大一包,最後其實只需要更好的檢索和 reranker。
如果是我明天要開一個新的 RAG 專案,我會先做 naive retrieval;只要 corpus 有精確詞,我就立刻補 hybrid search;接著上 reranker。只有當 logs 證明簡單版本真的漏掉某一類問題時,我才會考慮 query transformation、GraphRAG 或 agent。這就是很多人跳過的地方,然後又驚訝為什麼 fancy 版本更慢、更難 debug,效果只好一點點。
原始來源是 AIThinkerLab.com 的 How to Build RAG Systems in 2026: 8 Architecture Patterns。我這篇是依據原文做的拆解,搭配我自己的實作判斷、踩坑經驗和可直接複製的選型模板。