代理式 AI 關鍵在 Harness
這篇論文主張,代理式 AI 的進步不只靠更大模型,而是要把記憶、路由、驗證與治理這層 harness 當成核心設計。

這篇論文主張,代理式 AI 的進步不只靠更大模型,而是要把記憶、路由、驗證與治理這層 harness 當成核心設計。
- 研究機構:arXiv 摘要未明確標註
- 核心數據:摘要無公開 benchmark 數字
- 突破點:把 harness 當主體
如果你在做 agent,這篇的重點很直接:真正卡住系統的,往往不是模型本身,而是模型外面那層執行架構。作者把它叫做 agent harness,涵蓋記憶、檢索、路由、編排、驗證和治理。這不是把模型包一包而已,而是把整個長流程行為,當成系統設計問題來處理。
這個切法很重要。因為很多 agent 評估,只看最後有沒有完成任務。論文認為這樣不夠。長程表現好不好,常常取決於整套系統怎麼組,而不是模型單次輸出有多強。
這篇論文想解的痛點
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
作者先指出一個很常見的現實:現在的大型語言模型,已經能用工具、能查資料、能維持某種記憶,也能跑多步驟工作流。但外圍系統常被當成雜務,像是工程細節,不像核心設計。

論文認為,這種模型中心論已經不夠用了。因為你只看最後成功率,會漏掉很多 agent 真正會出事的地方,例如 context 變髒、記憶漂移、工具協調失敗、驗證不足,或是治理機制太弱。這些問題不一定會立刻讓任務失敗,但會讓 agent 在長時間運作時不穩。
作者把這個更大的系統層叫做「agent harness」。在他們的定義裡,harness 是把模型能力轉成長程行為的結構化執行層。論文的主張很簡單:未來的進步,不只來自模型 scaling,也要來自 harness scaling。
什麼是 harness scaling
所謂 scaling harness,重點不是單一技巧,而是把模型周邊系統做成可稽核、可持久、可模組化、可驗證。換句話說,這層執行架構不能再只是「跑得動就好」,而是要能被設計、被評估,也能被優化。
論文把 harness 拆成幾個互相作用的部分:foundation model、memory substrate、context constructor、skill-routing layer、orchestration loop,以及 verification-and-governance layer。這些元件一起決定了模型看到什麼、記得什麼、會叫出哪些技能、怎麼協調步驟,還有最後如何自我檢查。
這裡沒有提出單一演算法捷徑。作者要講的是系統觀。因為使用者感受到的 agent 行為,是這些元件互動後的結果,所以只改其中一塊,通常不夠。
論文聚焦的三個瓶頸
作者把討論集中在三個核心瓶頸:context governance、trustworthy memory、dynamic skill routing。除此之外,還有 orchestration 和 governance 機制,負責協調並約束這些部分。
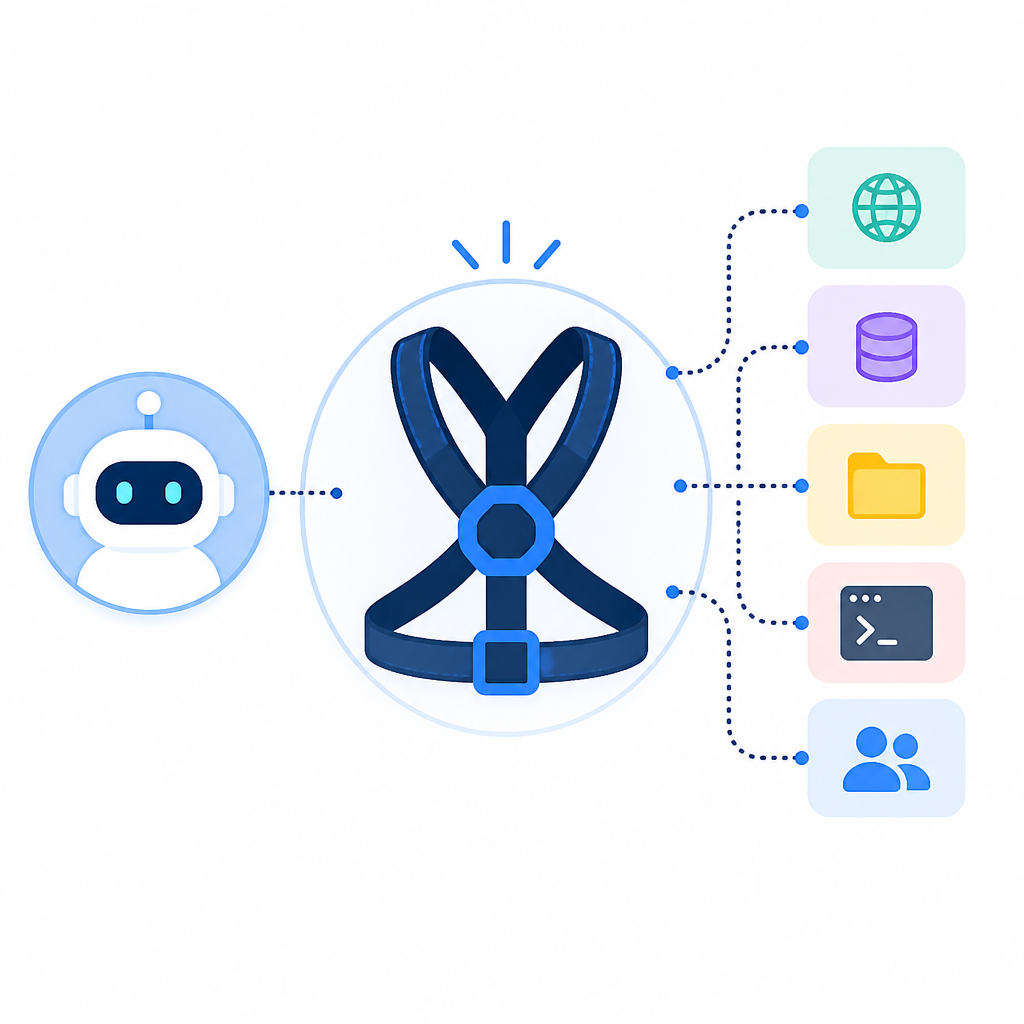
Context governance 指的是怎麼控制哪些內容進入模型的工作上下文,以及這些內容怎麼被組裝。Trustworthy memory 則是要讓資訊的寫入與讀取,能支撐長程工作,同時不要把 agent 狀態弄壞。Dynamic skill routing 則是在合適的時間,選對能力或工具,而不是每一步都走同一條路。
這些問題對做長流程 agent 的開發者來說都很熟。只要 context 變吵、memory 開始漂、routing 變脆弱,系統就可能失敗。即使底層模型本身很強,也一樣會翻車。
論文的語氣其實很明確:agent 的可靠性,不是模型單獨撐起來的,而是整個 harness 一起撐起來的。
這篇實際證明了什麼
先講清楚:這篇比較像 framing 與研究議程的論文,不是重 benchmark 的實證研究。摘要沒有公開 benchmark 數字,所以不能從摘要裡讀出 accuracy、throughput 或 cost 的具體結果。
作者有提到一個具體參考實作:CheetahClaws,一個 Python-native 的 reference harness,並且把它和 Claude Code、OpenClaw 做比較。不過摘要沒有放出比較結果,所以目前不能根據這份來源說哪個系統比較好,也不能說差多少。
論文真正提供的是評估方向。作者主張,harness 層級的 benchmark 不該只看一次性任務成功,而是要看 trajectory quality、memory hygiene、context efficiency、communication fidelity、verification cost,以及能不能安全地隨時間演化。
這份清單很關鍵,因為它直接改寫了什麼叫做「好 agent」。不再只是問「有沒有做對」,而是要問「有沒有做得乾淨、有效率、夠安全,而且長期穩定」。
對開發者的實際影響
如果你在做 production agent,這篇其實是在提醒你把注意力往上一層移。模型只是其中一個元件。真正決定 agent 能不能在長時間、工具密集、狀態持續的系統裡工作的是 harness。
這會直接影響工程設計。你要開始認真想:context 怎麼組、memory 怎麼寫入和讀取、技能怎麼路由、什麼時候做 verification、以及 loop 由誰治理。這些選擇的重要性,可能不輸 prompt 品質或模型選型。
論文也暗示了目前的評估習慣有點不夠。系統可能在最後答案正確率上表現不錯,但一進到 agent 模式就變得脆弱、漏資料、或成本很高。若你真的要上線,這些隱性問題通常才是最先咬人的地方。
不過,來源也很克制。摘要沒有給 benchmark 數字,也沒有在這裡宣稱新的 SOTA。所以這篇的價值,不是某個驚人的數字,而是它提供了一個看待 agent 的框架:把系統當成 harness,而不是只把它當成模型外殼。
限制與還沒回答的問題
這份來源最大的限制很明顯:摘要提供的是概念方向,不是完整實驗證據。雖然作者提到 CheetahClaws、Claude Code 和 OpenClaw 的比較,但摘要沒有交代比較結果。
這也留下不少後續問題。像是 harness 的各個元件彼此高度耦合,該怎麼分開評估?哪些指標最能代表 memory hygiene 或 verification cost?更強的治理,和系統彈性之間要怎麼平衡?
這些其實就是下一波 agent 工程最值得做的事。論文最重要的貢獻,不是某個單點技巧,而是把這些問題提升成第一級研究題目,而不是藏在模型 API 後面的實作細節。
對開發者來說,結論很實用:如果你的 agent 只在乾淨 demo 裡表現好,缺的可能不是模型,而是 harness。
- agent 的表現取決於整個系統層,不只看 foundation model。
- 論文把評估重心推向 trajectory quality、memory hygiene 與 verification cost。
- CheetahClaws 被當成 Python-native reference harness,但摘要沒有結果。