AI異常處置走向多Agent協作
XCOPS廣州站揭露阿里雲AIOps路線:異常偵測、日誌聚類、多Agent根因定位,正把維運流程做成自動化閉環。
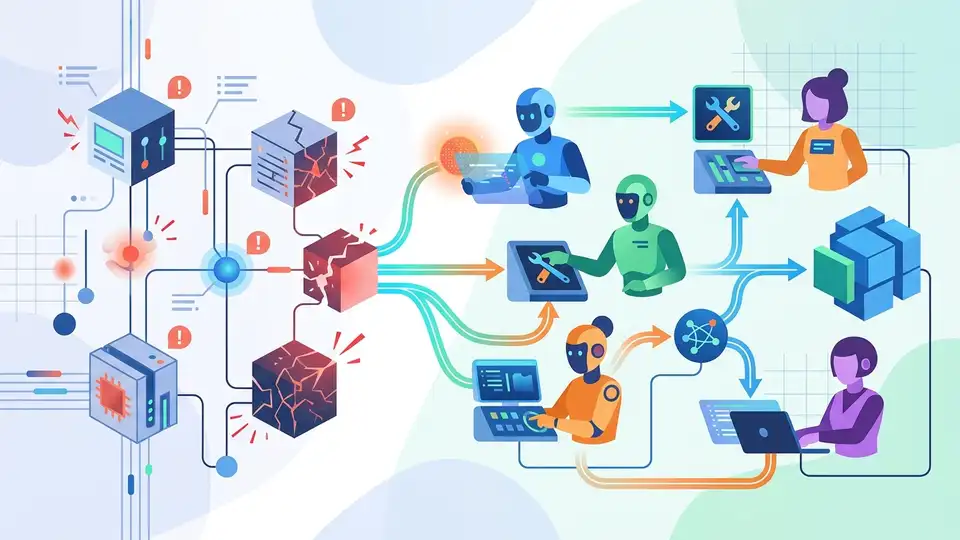
5月22日,XCOPS智能運維管理人年會廣州站,要把AI異常處置搬上檯面。這次不是空談概念。公開資訊直接丟出4個技術點:時間序列異常偵測、下鑽分析、日誌聚類、多Agent根因定位。
說白了,這已經不是「有沒有AI」的問題。這是在問,故障來了之後,系統能不能自己找線索。對SRE、AIOps、資料平台團隊來說,這種流程如果跑順,值班壓力會差很多。
更重要的是,這場分享來自阿里雲計算平台智能運維算法團隊。它談的不是 demo,而是會落到MaxCompute、Flink、DataWorks、PAI這種真實產品線。這點很關鍵。因為線上故障不會等你慢慢實驗。
為什麼異常處置變成AI題目
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
運維最花時間的,不是收到告警。是搞懂告警在吵什麼。指標飄一下,可能是流量變化,也可能是任務堆積。再不然,就是依賴服務慢了,或資料延遲了。人工排查時,工程師通常要先看監控,再翻日誌,再查呼叫鏈。
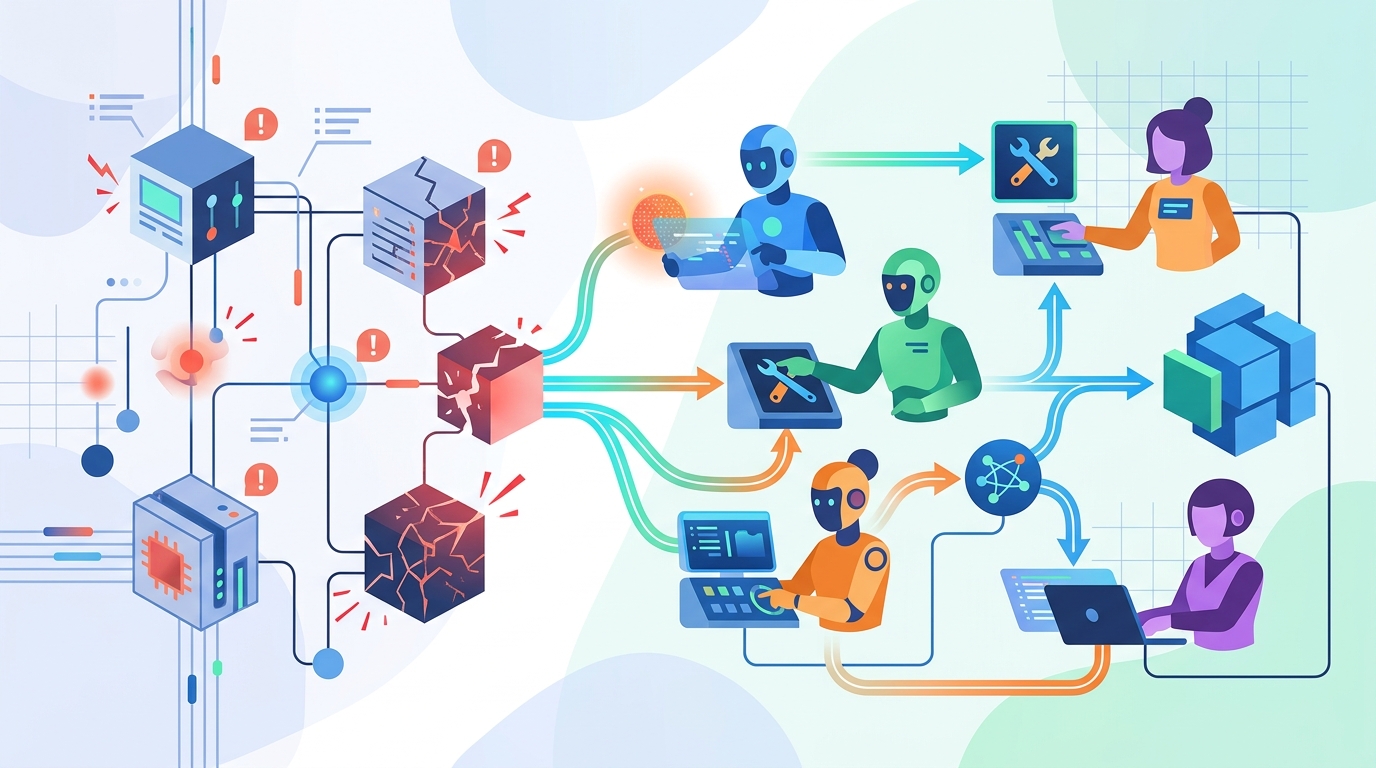
如果系統一多,這個流程就很痛。尤其是大資料平台,任務多、鏈路長、元件雜。單一告警常常只是表面症狀。你看到的是 CPU 飆高,背後可能是排程卡住。你看到的是延遲升高,根因可能在上游資料源。
阿里雲這次的方向很直接。先用通用時間序列異常偵測抓出問題。再靠下鑽分析和日誌聚類縮小範圍。最後讓多個 Agent 分工做根因定位。這種設計的重點,不是把人趕走,而是把最耗時的搜尋和比對交給模型。
- 異常發現:時間序列模型先抓波動
- 問題定界:下鑽分析配合日誌聚類
- 根因定位:多Agent分工查線索
- 平台落地:接到異常處置平台,形成閉環
多Agent的重點,不是多,是分工
很多人聽到多Agent,第一個反應是「是不是很多模型一起聊天」。講白了,這種想像太表面。真正能落地的多Agent系統,重點是角色切分。每個 Agent 做一件事,然後把結果串起來。
在異常處置裡,這種分工很實用。有的 Agent 看指標。有的 Agent 查日誌。有的 Agent 負責工具呼叫。有的 Agent 整理證據,拼出因果鏈。這樣做的好處很明顯。模型不用一次吞下全部上下文。工程上也比較好控權限、審計和工具邊界。
這次分享的講者是阿里雲算法專家張穎瑩。她在智能運維領域做了8年,長期支援 MaxCompute、Flink、DataWorks、PAI 等產品。她也參與過SREWorks開源大資料運維平台開發,還參與中國信通院《智能運維能力成熟度模型》標準編寫。這種背景,代表她講的不是紙上談兵。
“用產品和服務支撐計算平台 MaxCompute、Flink、Dataworks、PAI 等多個大數據&AI產品的智能化運維。” —— 張穎瑩,阿里雲計算平台智能運維算法團隊負責人
這句話很直白。它把目標講清楚了。不是做一個漂亮模型,而是把模型塞進產品鏈路,持續處理線上問題。這才是企業最在意的地方。
和傳統AIOps比,差在閉環速度
傳統AIOps常見做法,是告警降噪、異常偵測、事件關聯。這些能力有用,但到根因定位時,常常還是要人接手。多Agent方案想做的事,是把「從告警到解釋」這段路縮短。
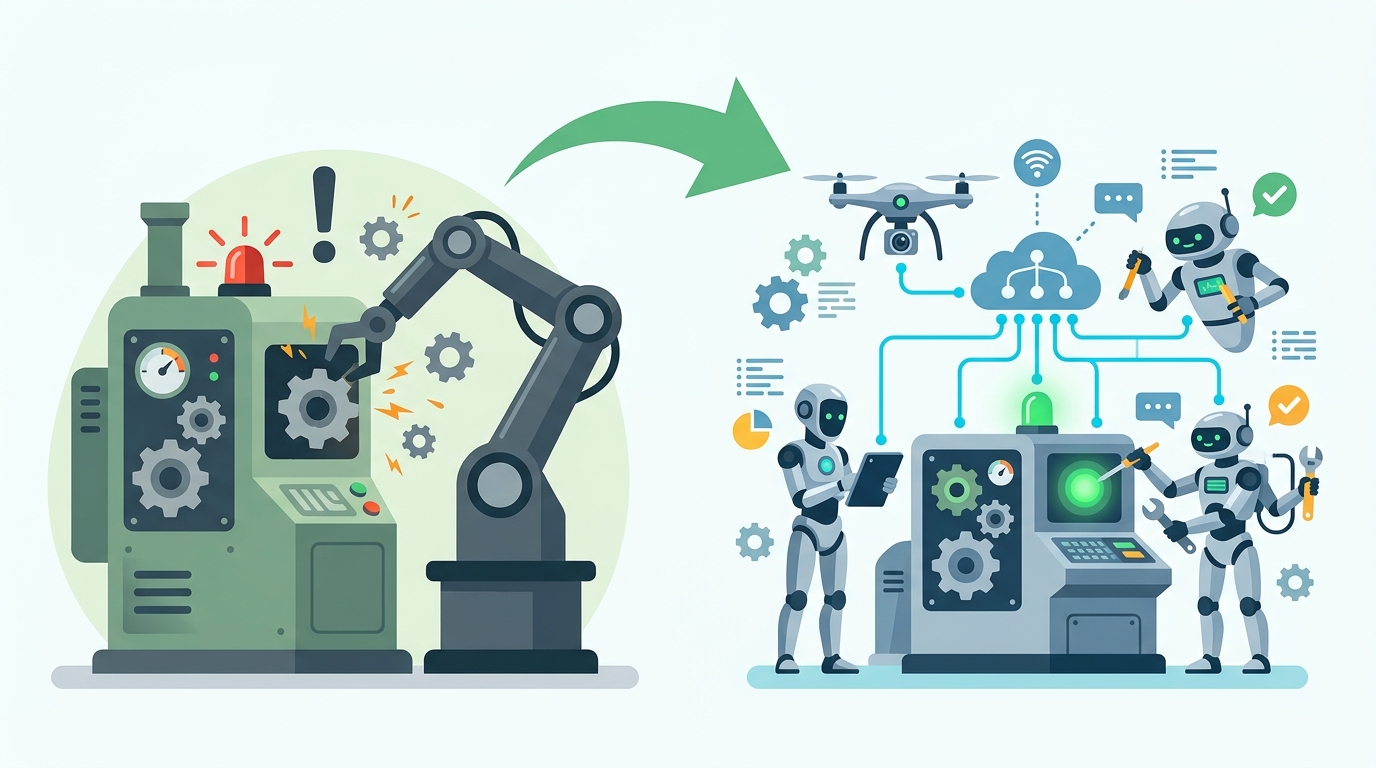
如果把流程攤開看,差別會很明顯。傳統流程裡,告警出來後,工程師可能要花 30 分鐘到數小時排查。AI 流程先把異常抓出來,再自動下鑽和聚類,先把候選範圍縮小。多Agent 流程則是讓不同角色並行工作,少掉很多單線排查的等待時間。
阿里雲這次還提到工具箱建設。這點很現實。大模型再會講,如果拿不到監控、日誌、配置、變更紀錄,推理品質就會掉。工具越完整,Agent 越像真的運維同事,而不是只會講建議的聊天框。
- 傳統流程:人工看告警,常耗時 30 分鐘以上
- AI流程:先偵測,再下鑽,再聚類
- 多Agent流程:並行查線索,減少等待
- 平台化流程:把經驗沉澱成工具箱
這也解釋了為什麼現在很多企業不缺模型,缺的是應用框架。模型要接權限系統、觀測系統、工單系統。能接進生產鏈路,才有機會把「發現問題」推進到「解決問題」。
廣州站透露的,是更務實的方向
這場分享放在XCOPS廣州站,訊號很清楚。AI運維已經不是「要不要做」的階段,而是「怎麼做才穩」的階段。大會議程還提到垂類Agent、人機協作、資料庫自治、金融核心改造。這代表業界關注點已經從單點模型,轉向系統級交付。
再看張穎瑩的履歷,也很有說服力。她帶隊拿過ICASSP國際智能運維演算法大賽冠軍,研究成果也被 ICLR、KDD、VLDB、SIGMOD、ICDE、WWW、CIKM、ICASSP 等國際會議接收。對一個運維團隊來說,這種科研和工程雙線並進的背景,不算常見。
我覺得,這次公開資訊最重要的地方,是它把問題講得很清楚。現在不是「模型能不能偵測異常」。而是「模型能不能在 5 分鐘內把異常說清楚」。這會直接影響運維團隊怎麼分工,也會影響監控產品怎麼設計。
對正在做AIOps或資料平台自治的團隊,我的建議很直接。先別急著再加告警規則。先把日誌、指標、變更、拓樸、工單串起來。先做出一條能驗證的異常處置閉環。誰先跑通,誰就先少掉一堆夜班苦工。
這波變化,其實有產業背景
AI進運維,不是突然冒出來的。它是被線上系統逼出來的。雲端服務越多,元件越多,故障樣態就越碎。以前一個服務掛掉,人工看幾個節點就懂。現在一個問題可能牽動多個叢集、多條資料管線,還有跨區部署。
所以,AIOps 的價值也在變。早期大家想解決的是告警太多。後來變成事件關聯。現在更進一步,是希望系統自己做初步判讀。這也是為什麼多Agent、日誌聚類、下鑽分析會一起出現。它們不是獨立功能,而是同一條流程的不同段落。
從市場角度看,這種能力很可能先在大資料、AI 平台、金融核心系統落地。因為這些場景對停機最敏感,也最怕人工慢半拍。對一般中小型系統來說,可能還不需要這麼重的架構。但只要系統規模一上來,這些工具就會變得很實際。
如果你是工程團隊,現在就該問一個問題:你的監控系統,能不能在 5 分鐘內給出 3 個可驗證的根因候選?如果答案還不行,那就代表還有很大的自動化空間。
接下來,看誰先把閉環做穩
我的判斷很直接。接下來 12 個月,真正有價值的不是更多告警,而是更快的根因定位。誰能把異常偵測、日誌聚類、多Agent 推理、工單處理串成一條鏈,誰就能把維運成本壓下來。
如果你在做SRE、AIOps、資料平台,現在就可以開始盤點三件事。第一,監控資料夠不夠完整。第二,日誌和變更紀錄能不能打通。第三,現有流程能不能讓 Agent 介入。這三件事做完,才有機會把AI真的接進運維。
講白了,未來不是看誰模型名字比較炫。是看誰能在真實伺服器環境裡,5 分鐘內把問題講清楚。這件事很土,但很值錢。