DynaFLIP teaches robot vision motion
DynaFLIP trains robot vision to encode motion, not just appearance, for better manipulation generalization.

DynaFLIP trains robot vision to encode motion, not just appearance, for better manipulation generalization.
- Research org: Unspecified in arXiv abstract
- Core data: +22.5% under out-of-distribution scenarios
- Breakthrough: Tri-modal image-language-3D flow pretraining with simplex-volume alignment
Robot manipulation systems usually rely on visual encoders that were trained to recognize static images or align images with language. That works for naming objects, but it can miss the part that matters most for control: how a scene changes when a robot acts on it. DynaFLIP: Rethinking Robotics Perception via Tri-Modal-Dynamics Guided Representation argues that this gap should be fixed upstream, inside perception itself.
The practical idea is simple: if the encoder already understands motion-relevant structure, downstream policies do not have to rediscover it from scratch. That matters for developers because perception quality often becomes the hidden bottleneck in robot generalization, especially when the robot leaves the exact conditions it saw during training.
What problem this paper is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The paper starts from a familiar robotics problem: action success depends on perception that preserves the parts of the scene relevant to control. Most existing pipelines, however, use visual encoders pre-trained for static recognition or vision-language alignment. Those encoders are good at identifying what is present, but they are not explicitly trained to capture how the world changes under action.

In other words, motion understanding is often pushed downstream into the policy. DynaFLIP argues that this leaves a blind spot in the representation itself. If the backbone does not encode dynamics well, the policy has to compensate later, which can limit transfer across tasks, environments, and real-world conditions.
The paper frames this as a representation-learning problem rather than only a policy-learning problem. That is an important distinction for robotics engineers: instead of adding more task-specific logic on top, the authors try to make the visual backbone itself more useful for manipulation.
How the method works in plain English
DynaFLIP is a dynamics-aware multimodal pre-training framework. It uses image-language-3D flow triplets built from heterogeneous human and robot videos, and those triplets supervise training for an image-only encoder. The goal is to make the encoder sensitive to motion-relevant cues without requiring the final model to ingest all three modalities at deployment.
The core geometric idea is to make the three modalities occupy a small simplex volume in a shared hyperspherical space. The paper says that a smaller simplex volume means stronger alignment among the image, language, and 3D flow views. If that sounds abstract, the engineering intuition is straightforward: the model is encouraged to represent different descriptions of the same underlying scene transition in a tightly coordinated way.
The authors also note a problem with naïvely minimizing simplex volume: it can create geometric ambiguity or collapse to trivial solutions. To avoid that, DynaFLIP combines simplex-volume minimization with a cosine regularizer and a contrastive objective. That combination is the actual training recipe, not just the geometric intuition.
For practitioners, the interesting part is that the output is still an image-only encoder. The multimodal supervision is used during training, but the resulting representation can act as a reusable visual backbone. That makes the method easier to plug into existing robotics stacks than a system that requires extra modalities at inference time.
What the paper actually shows
The abstract says the authors analyzed the learned representations and found that DynaFLIP focuses on control-relevant regions critical for manipulation. It also says the resulting dynamics-aware representations serve as reusable visual backbones and consistently outperform baselines across diverse downstream policies, including VLAs.
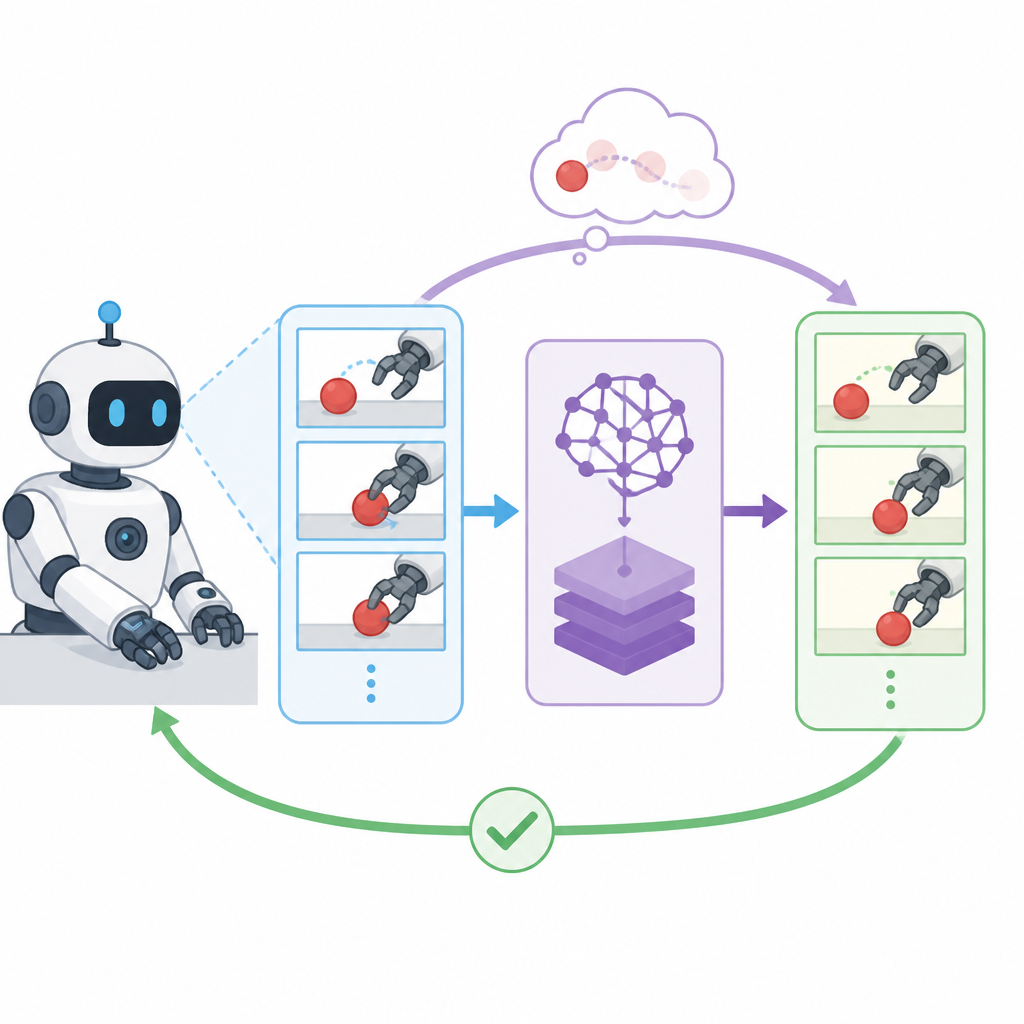
The paper reports validation across diverse simulation and real-world setups. The strongest number mentioned in the abstract is a gain reaching +22.5% under out-of-distribution scenarios. The abstract does not provide the full benchmark table, task list, or exact metric definition, so those details are not available from the source text alone.
That missing context matters. A headline improvement can mean different things depending on whether the metric is success rate, accuracy, or another robotics measure. The abstract confirms the direction of the result, but it does not expose the full evaluation protocol here.
Still, the reported pattern is meaningful: the method is not just improving in-distribution performance, but specifically helping when conditions shift. For robotics, that is often the real test. A representation that survives distribution shift is usually more valuable than one that only looks good on familiar scenes.
Why developers should care
If you build robot policies, this paper points to a useful design shift: improve the backbone before tuning the policy. That can reduce the burden on downstream learning, especially in manipulation settings where object appearance alone is not enough to decide what action should happen next.
It also reinforces a broader lesson from multimodal learning: language and 3D motion cues are not only for end-task reasoning. They can be used as training-time structure to shape a better visual encoder. In practice, that means better representations may come from richer supervision even when deployment stays image-only.
There are also clear limitations in what the abstract tells us. We do not get the full set of benchmarks, the exact downstream policies, the scale of the training data beyond “heterogeneous human and robot videos,” or the compute cost of training. The abstract also does not claim that DynaFLIP removes the need for task-specific adaptation entirely.
So the right way to read this paper is as a representation-learning upgrade for robotics perception, not a universal fix. It suggests that if you want robots to generalize better, you should train visual features to encode not just what is in the scene, but how the scene changes under action. That is a practical idea, and it is one that fits cleanly into existing robotics pipelines.
Bottom line
DynaFLIP tries to move motion understanding into the visual encoder itself by aligning image, language, and 3D flow during pretraining. The paper’s main evidence is that this produces representations that help downstream manipulation policies, including out-of-distribution cases, with gains reaching +22.5% in the reported abstract.
For engineers, the takeaway is not “use this exact model tomorrow,” but “representation quality matters as much as policy design.” If your robot stack struggles with generalization, the bottleneck may be the encoder’s inability to represent dynamics, not just the policy head’s inability to act on them.
- Dynamics-aware pretraining may improve manipulation backbones without requiring multimodal inference.
- The method uses simplex-volume alignment plus cosine and contrastive regularization to avoid collapse.
- The abstract reports strong OOD gains, but not the full benchmark suite or training cost.
// Related Articles
- [RSCH]
ArXiv AI papers push agents, memory, and data
- [RSCH]
ReproRepo scales reproducibility audits with GitHub issues
- [RSCH]
Variable-Width Transformers cut wasted capacity
- [RSCH]
VERITAS lets robots verify and improve at runtime
- [RSCH]
Phase noise makes massive MIMO information age
- [RSCH]
18 AI benchmarks now rank GPT-5.5, Claude, Gemini