Research
AI research papers, breakthroughs, and technical deep dives. From academic publications to lab findings shaping the future of AI.
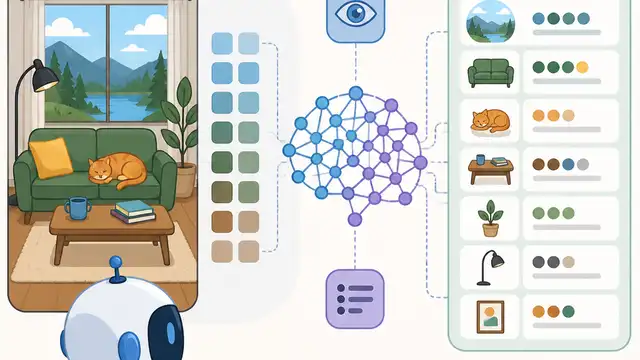
How VLMs Learned Complex Scene Descriptions
A decade of VLMs closed the gap on complex scene descriptions, but spatial dependence errors still linger.

Visual Pretraining Beats Text-Only in Language Models
Visual pretraining on the same corpora consistently outperforms text-only pretraining across backbones and benchmarks.

PHINN-EEG brings topology to dream-state EEG
PHINN-EEG replaces EEG dream detection’s spectral features with topological dynamics and a topology-conditioned synthesis model.

Google’s Android Bench update exposes Gemini’s gap
Google added new models to Android Bench, and Gemini 3.1 Pro fell to fifth behind OpenAI and Anthropic rivals.

Benchmarks should not pick your LLM in 2026
Benchmarks matter, but they should not be the primary basis for choosing an LLM in 2026.

Rust Breaks Into TIOBE’s Top 10
Rust has entered TIOBE’s top 10, showing a new path for language trend tracking.
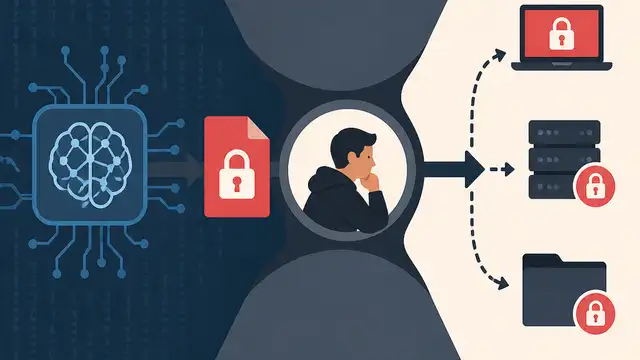
AI ransomware still needs a human bottleneck
I break down why the first AI-run ransomware attack still depended on human setup, stolen creds, and target choice.

A benchmark for scientific lineage reasoning
IG-Bench tests whether LLMs can trace scientific idea lineage and generate new ideas from it.
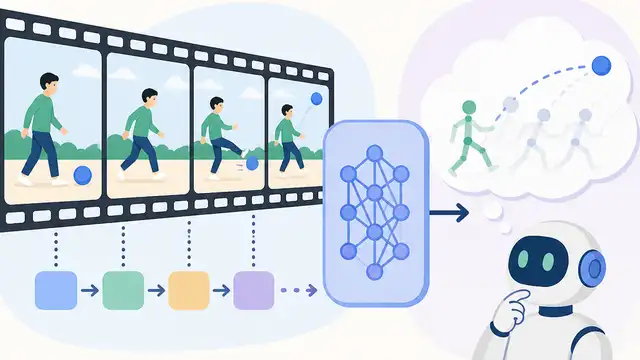
OpenCoF teaches video models to reason frame by frame
OpenCoF adds temporal supervision and reasoning tokens to make video generation models reason across frames.

UniClawBench tests proactive agents in live tasks
UniClawBench evaluates proactive agents in live Docker tasks with five capability axes and 400 bilingual scenarios.

WebAssembly-to-C still rivals native runtimes in 2026
Frank DENIS found WebAssembly-to-C still matches top runtimes on 2026 libsodium tests, even after new wide arithmetic support.
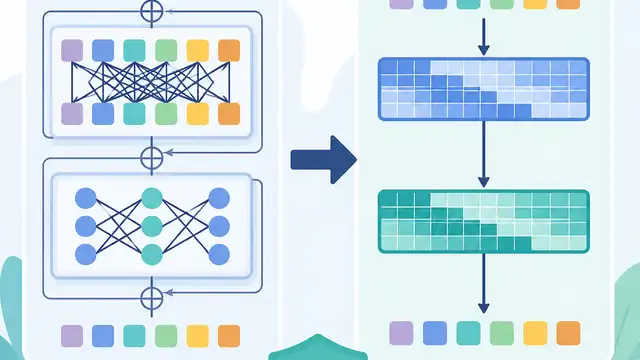
How to Linearize Transformers Without Losing Quality
A frozen-backbone linearization recipe narrows the quality gap while preserving long-context transformer behavior.
Co-LMLM lets LMs query knowledge continuously
Co-LMLM replaces fixed KB queries with continuous vector queries and improves factual precision without baking facts into weights.
SciReasoner makes structure readable to AI
SciReasoner turns structural data into tokens so AI can predict and explain biology, chemistry, and materials more transparently.

Rethinking Indic AI Through Cultural Heritage
This paper reframes Indic AI as a cultural-preservation problem and proposes Culture Sensing for more meaningful outputs.

Graph Convolutional Attention fixes graph denoising
A new graph attention method uses spectrum-aware filtering to improve denoising and diffusion without expensive structural features.

ELSA3D Makes 3D Models Reason in Scales
ELSA3D uses sparse anchors and scale-aware geometry to unify 3D generation and language reasoning.

Leanstral 1.5 proves open-source math models are now useful
Leanstral 1.5 shows open-source models can now deliver real value in formal math and code verification.
Label-free real-bogus classification with calibrated uncertainty
This paper shows injection-driven training can classify real vs bogus transients without human labels and still produce calibrated uncertainty.

Direct-OPD reuses weak-model RL gains for stronger models
Direct-OPD lifts Qwen3-1.7B from 48.3% to 62.4% on AIME 2024 by distilling RL gains from a weaker model.

CamVLA makes robot policies view-robust
CamVLA lets robots act from a single RGB view without camera calibration or depth.
Data link layer: OSI layer 2 explained
The OSI data link layer defines local frame delivery, media access, and error checks between devices on the same network segment.

The OSI model still explains networking well
The OSI model is a seven-layer reference model that still helps engineers explain how network traffic moves from bits to apps.

Evaluation Protocols for Fine-Tuned LLMs in 2026
Build a layered evaluation pipeline for fine-tuned LLMs using task metrics, judges, safety checks, and human review.

DeepSpec should be treated as a data-regeneration pipeline, not a tra…
DeepSpec is best understood as a conversation regeneration pipeline for training stronger models.
Program-as-Weights turns prompts into reusable tools
PAW compiles natural-language task specs into small local neural artifacts that run cheaply and offline.
LACUNA tests whether LLM unlearning really erases
LACUNA adds ground-truth parameter-level localization to test whether unlearning really removes memorized data.

Persistent-state AI agents open a new attack surface
A new benchmark shows AI coding agents can hide attacks across PRs and time their payloads to evade monitors.
Language critiques improve imitation learning
This paper uses natural-language critiques to train policies from suboptimal demonstrations.
One Transformer Layer Can Carry RL Gains
A layer-wise RL study finds that training one transformer layer can recover most post-training gains.