UniPool shares MoE experts across layers
UniPool replaces per-layer MoE experts with one shared pool, cutting redundancy and improving validation loss in five LLaMA-scale models.

UniPool shares one expert pool across layers to make MoE models smaller and more efficient.
Modern mixture-of-experts models usually give each transformer layer its own separate set of experts. That design is simple, but it also bakes in a strong assumption: deeper layers always need their own isolated expert capacity, and that capacity has to grow linearly as the model gets deeper. UniPool: A Globally Shared Expert Pool for Mixture-of-Experts argues that this rule is often more rigid than it needs to be.
The practical motivation is easy to understand. If a lot of expert capacity is being duplicated layer by layer, then MoE models may be paying for parameters they do not fully use. The paper points to routing probes showing that replacing a deeper layer’s learned top-k router with uniform random routing only drops downstream accuracy by 1.0-1.6 points across multiple production MoE models. That is not a proof that routing does not matter, but it is a strong hint that some layers may be more redundant than the standard design assumes.
What problem this paper is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
In a conventional MoE transformer, each layer owns its own expert set. That creates a clean mapping between depth and capacity, but it also means the number of expert parameters scales linearly with the number of layers. For engineers building larger models, that is a costly default: every extra layer can imply another chunk of expert weights, even if the layer does not need fully separate experts.
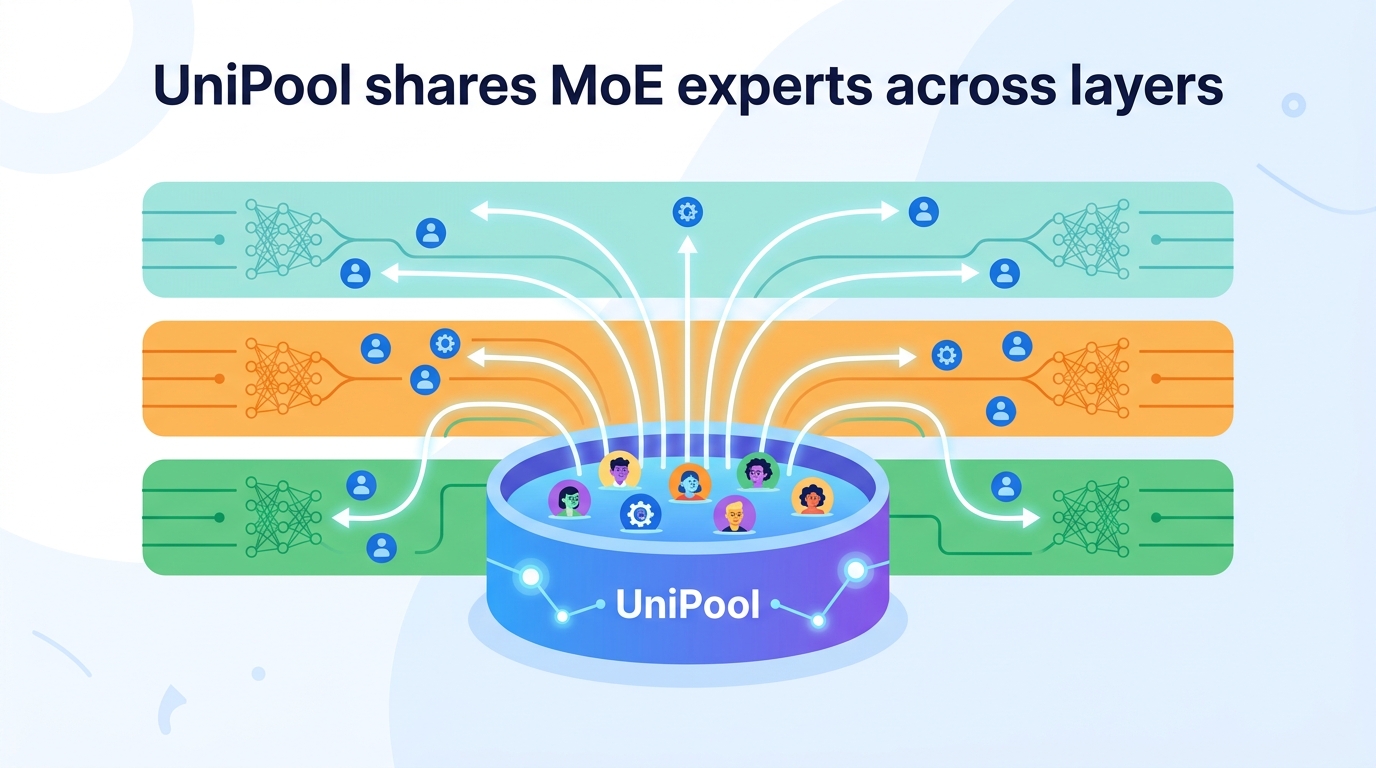
UniPool tries to break that coupling. Instead of treating expert capacity as something owned locally by each layer, it treats expert capacity as a single global budget that all layers can draw from. In other words, the model still has per-layer routing decisions, but the experts themselves live in one shared pool rather than being duplicated across depth.
This matters because MoE systems are often justified as a way to increase capacity without making inference prohibitively expensive. If the architecture itself is wasting expert parameters through rigid ownership rules, then the efficiency story gets weaker. UniPool is an attempt to make the capacity allocation more flexible without abandoning sparse expert routing.
How UniPool works in plain English
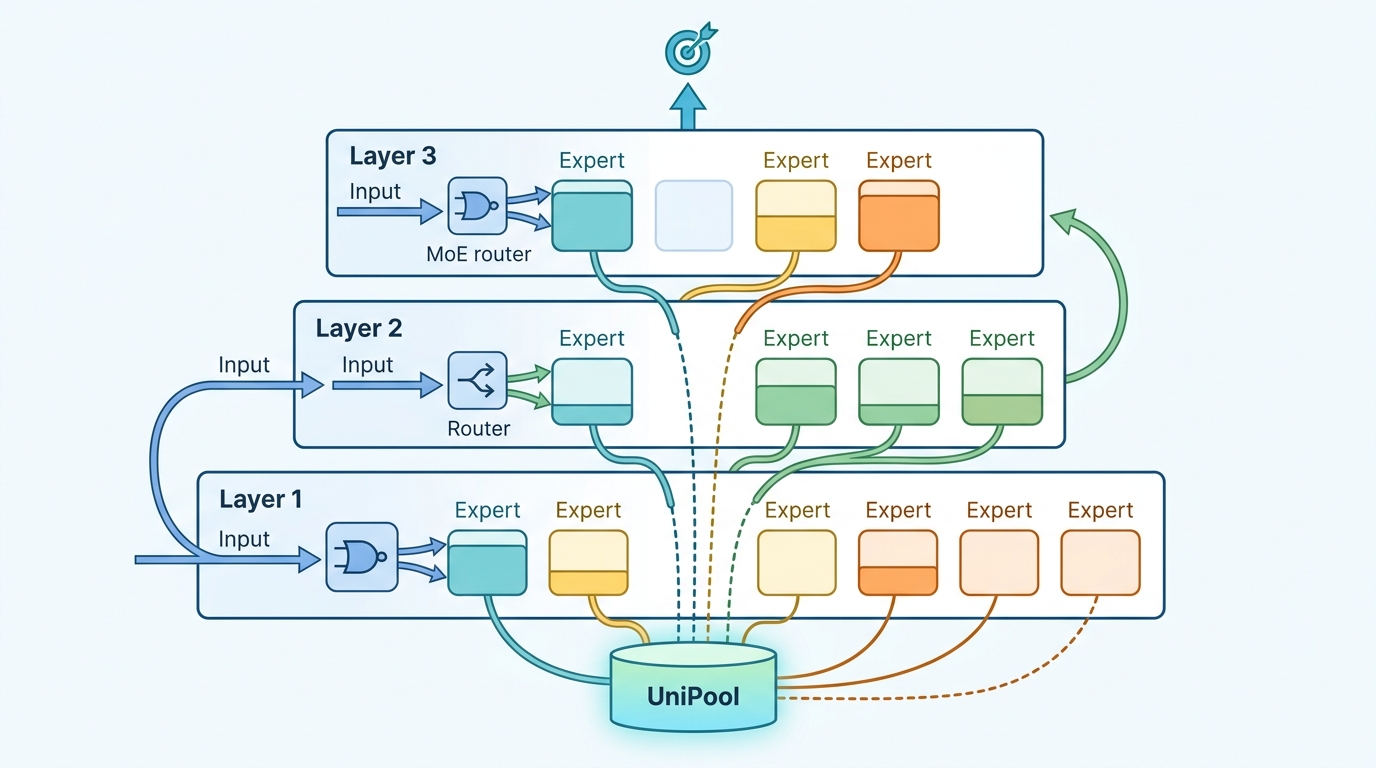
The core change is straightforward: replace per-layer expert ownership with a globally shared expert pool. Each transformer layer gets its own router, but those routers all point into the same set of experts. That means different layers can reuse the same expert capacity instead of each carrying a private copy.
Sharing experts across layers creates a new training problem, though. If every layer can hit the same pool, some experts could get overloaded while others go underused. To keep training stable, the paper adds a pool-level auxiliary loss that balances expert utilization across the entire shared pool. It also uses NormRouter, which the paper describes as providing sparse and scale-stable routing into the shared expert pool.
So the recipe is not just “share everything and hope for the best.” It is a combination of architectural sharing plus training controls meant to keep the pool from collapsing into a few overused experts. That balance is the key implementation detail for anyone thinking about reproducing the idea in a real MoE stack.
What the paper actually shows
The evaluation covers five LLaMA-architecture model scales: 182M, 469M, 650M, 830M, and 978M parameters. All models are trained on 30B tokens from the Pile. The paper says UniPool consistently improves validation loss and perplexity over matched vanilla MoE baselines across these scales.
The most concrete number in the abstract is that UniPool reduces validation loss by up to 0.0386 relative to vanilla MoE. The paper also reports that reduced-pool UniPool variants, using only 41.6% to 66.7% of the vanilla expert-parameter budget, match or outperform layer-wise MoE at the tested scales. That is the most important result for people who care about model efficiency: the shared-pool design can use noticeably less expert capacity without giving up performance in these experiments.
There is also a broader scaling claim here. The authors argue that pool size becomes an explicit depth-scaling hyperparameter under UniPool. Instead of assuming expert parameters must grow linearly with depth, the paper shows they can grow sublinearly and still remain more effective than the vanilla layer-wise design in the tested setups.
Another notable result is that UniPool’s benefits compose with finer-grained expert decomposition. The abstract does not give more detail than that, so we should not overread it, but the implication is that shared pooling is not a one-shot trick that only works in a narrow configuration.
Why developers should care
If you build or tune MoE systems, the big takeaway is that expert placement may be more flexible than the standard layer-by-layer design suggests. UniPool offers a way to think about expert capacity as a shared resource, which could reduce parameter duplication and make depth scaling less expensive.
That is useful in practice for a few reasons:
- It may lower the expert-parameter budget needed at a given model scale.
- It gives pool size a direct tuning knob instead of forcing linear growth with depth.
- It suggests that some MoE layers may not need fully isolated expert sets to stay effective.
- It introduces a training pattern that tries to keep shared experts balanced and stable.
For engineering teams, the appeal is not just smaller models. A shared pool could also simplify capacity planning, since you are no longer making the same expert allocation decision independently for every layer. That said, the paper does not provide inference latency, throughput, memory breakdowns, or deployment cost numbers in the abstract, so those practical system-level gains remain unproven here.
What is still unclear
The abstract gives strong evidence that the shared-pool idea works on the tested model scales, but it does not answer every question a production team would ask. We do not get detailed latency measurements, serving behavior, or failure modes under different routing distributions. We also do not know from the abstract how sensitive the method is to pool size, router choice, or training recipe beyond the reported use of NormRouter and the pool-level auxiliary loss.
There is also an important scope limit: the results are on five LLaMA-architecture scales trained on the Pile. That is a useful spread, but it is still a specific experimental setting. Whether the same pattern holds across other architectures, datasets, or larger production deployments is not established in the abstract.
Even with those caveats, the paper makes a clear technical point: the standard assumption that every layer needs its own expert bank may be overly conservative. UniPool shows that a globally shared expert pool can preserve or improve validation metrics while using less expert capacity, which is exactly the kind of architectural simplification MoE practitioners should pay attention to.
// Related Articles
- [RSCH]
How VLMs Learned Complex Scene Descriptions
- [RSCH]
Visual Pretraining Beats Text-Only in Language Models
- [RSCH]
PHINN-EEG brings topology to dream-state EEG
- [RSCH]
Google’s Android Bench update exposes Gemini’s gap
- [RSCH]
Benchmarks should not pick your LLM in 2026
- [RSCH]
Rust Breaks Into TIOBE’s Top 10