Policy Invariance as a Better LLM Judge Test
This paper argues that accuracy alone is not enough to trust LLM safety judges, and proposes policy invariance as a reliability test.

Policy invariance is a reliability test for LLM safety judges.
Most teams want LLM safety judges that do more than label outputs correctly once in a while. They need judges that stay consistent when the policy changes, because a judge that flips behavior for the wrong reasons is hard to trust in production. This paper, Beyond Accuracy: Policy Invariance as a Reliability Test for LLM Safety Judges, argues that accuracy by itself is not enough and proposes policy invariance as a more useful way to check reliability.
The core idea is simple: if a judge is truly evaluating safety policy rather than memorizing surface patterns, its decisions should remain stable when the policy is rewritten in ways that should not change the underlying meaning. That matters for engineers because safety judges are often used as gatekeepers in moderation pipelines, red-teaming workflows, and automated evaluation. If the judge is brittle, downstream systems inherit that brittleness.
What problem this paper is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The paper is reacting to a common trap in LLM evaluation: a model can score well on a benchmark and still behave unreliably when the policy text or framing changes. In other words, accuracy can look good on paper while hiding sensitivity to irrelevant wording, format shifts, or prompt changes. For safety judges, that is a serious issue because the job is not just to be right on one dataset, but to be dependable across policy variations.

That distinction matters in practice. A safety judge that only performs well under a narrow prompt or a single policy wording can become a maintenance burden. Teams may have to keep tuning prompts, rewriting rules, or manually checking outputs whenever the policy evolves. The paper’s framing suggests that reliability should be tested directly, not inferred from accuracy alone.
How policy invariance works in plain English
Policy invariance is presented as a test of whether a judge’s decisions stay consistent when the policy changes in ways that should not alter the correct judgment. The paper positions this as a reliability check rather than a replacement for accuracy. That means the goal is not to ignore correctness, but to add another lens that catches failure modes accuracy can miss.
In practical terms, this kind of test asks whether the judge is responding to the policy itself or to accidental cues in the prompt setup. If two policy descriptions are semantically equivalent, a reliable judge should give the same decision. If it does not, that inconsistency is a signal that the judge may be overly sensitive to wording, formatting, or prompt-specific artifacts.
The abstract and notes do not provide the full experimental protocol, so we cannot claim exactly how the policy variants were generated or what specific judge architectures were tested. What the paper clearly does, though, is elevate invariance from a theoretical preference to a concrete reliability criterion for safety judges.
What the paper actually shows
The source material available here does not include benchmark numbers, tables, or concrete performance metrics, so there are no results to quote. That is important to say plainly: we can describe the method and motivation, but not the paper’s measured gains or failure rates from this abstract alone.
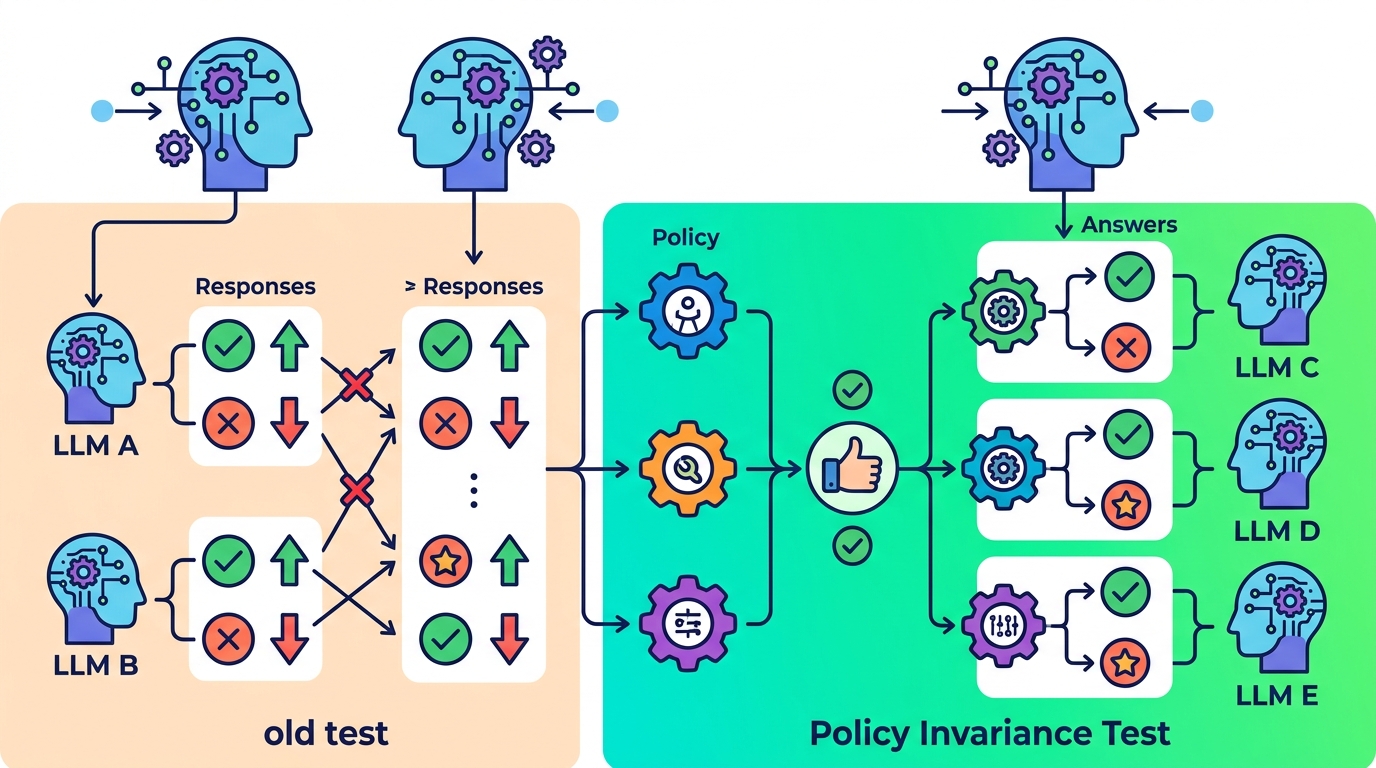
Even without numbers, the paper’s contribution is still useful because it changes the evaluation question. Instead of asking only, “Did the judge get the label right?” it asks, “Does the judge keep behaving consistently when the policy is expressed differently?” For engineers building safety systems, that is a more operationally meaningful question.
This also implies a broader point about LLM evaluation: a single score can hide unstable behavior. A judge may appear strong on a static test set while being fragile under policy rewrites. Policy invariance is meant to expose that fragility before it shows up in production.
Why developers should care
If you build moderation tools, content filters, policy classifiers, or automated evaluation pipelines, your judge is part of the control plane. When that judge is unreliable, the rest of the system becomes harder to reason about. A policy invariance check gives teams a way to probe whether the judge is actually learning the policy logic, not just the wording around it.
That can be especially useful when policies change over time. Real-world safety policies are not static, and teams often revise them for new products, new jurisdictions, or new abuse patterns. A judge that is invariant under harmless policy rewrites is easier to maintain and safer to rely on.
- Use accuracy as a baseline, not the only signal.
- Test whether judge outputs stay stable across equivalent policy phrasing.
- Watch for brittle behavior when the prompt or policy text changes.
- Treat inconsistency as a reliability bug, not just a benchmark miss.
Limitations and open questions
The biggest limitation in the source material is that it does not include the paper’s detailed methodology or results. We do not know from the abstract alone what datasets were used, how policy equivalence was defined, or whether the approach was evaluated across multiple judge models. Those details matter if you want to reproduce the work or compare it against other evaluation methods.
There is also an open question about how to operationalize policy invariance in a real team workflow. Should it be a pass/fail gate, a ranking metric, or a diagnostic tool during prompt iteration? The paper’s framing suggests reliability testing, but the exact deployment pattern is not visible in the abstract.
Still, the direction is clear: for LLM safety judges, accuracy is necessary but not sufficient. If a judge cannot stay consistent under policy changes that should not matter, then its apparent quality may be more fragile than the benchmark score suggests. That is the kind of problem developers want to catch early, before it becomes a production incident.
For teams building or buying safety evaluation systems, this paper is a reminder to look beyond headline metrics. Reliability is not just about being correct once. It is about being correct for the right reasons, even when the policy language shifts around it.
// Related Articles
- [RSCH]
How VLMs Learned Complex Scene Descriptions
- [RSCH]
Visual Pretraining Beats Text-Only in Language Models
- [RSCH]
PHINN-EEG brings topology to dream-state EEG
- [RSCH]
Google’s Android Bench update exposes Gemini’s gap
- [RSCH]
Benchmarks should not pick your LLM in 2026
- [RSCH]
Rust Breaks Into TIOBE’s Top 10