BAMI tackles GUI grounding bias without retraining
BAMI is a training-free method that improves GUI grounding by reducing precision and ambiguity bias in complex interfaces.

BAMI is a training-free method that improves GUI grounding by reducing precision and ambiguity bias in complex interfaces.
GUI grounding is the part of a GUI agent stack that decides where to click, drag, or interact on a screen. In practice, that sounds simple until the interface gets dense, high-resolution, or packed with similar-looking controls. This paper argues that those conditions are exactly where current models start to fail, and it proposes a way to reduce those failures without retraining the model.
The paper is BAMI: Training-Free Bias Mitigation in GUI Grounding. Its core idea is practical: instead of changing model weights, it changes how the model is used at inference time. That makes it especially relevant for developers who already have a GUI grounding model in production or in a toolchain and want better accuracy without the cost and risk of a new training cycle.
What problem the paper is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The authors focus on a failure mode that shows up in difficult benchmarks like ScreenSpot-Pro. Existing GUI grounding models can struggle when the screen is large and detailed, because the model may over-focus on precision in high-resolution images. They also struggle when the interface contains many intricate or similar elements, which creates ambiguity about the correct target.
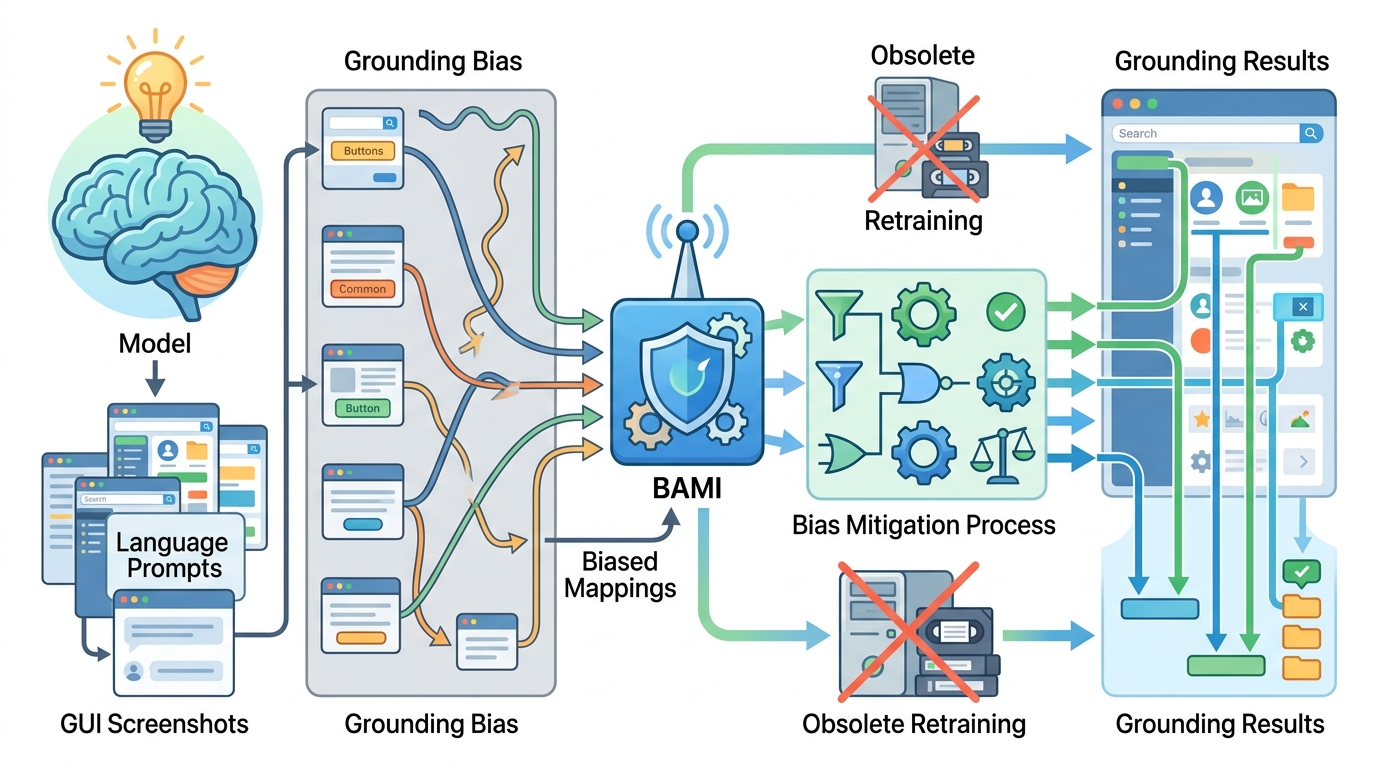
In the paper’s framing, these are two different sources of error: precision bias and ambiguity bias. Precision bias is tied to high image resolution, where a model may not localize the right area reliably. Ambiguity bias appears when the interface itself is crowded or visually complex, making it harder to distinguish between candidate targets.
That distinction matters because it moves the problem from a vague “the model is bad on hard screenshots” complaint to a more actionable diagnosis. If the errors come from how the model handles resolution and candidate confusion, then a mitigation strategy can be designed around those specific failure patterns.
How BAMI works in plain English
To identify where the model is going wrong, the authors introduce a method called Masked Prediction Distribution, or MPD, attribution. The abstract does not go into a full implementation walkthrough, but the role of MPD is clear: it helps attribute errors and expose the two bias sources the paper targets.
On top of that diagnosis, the paper proposes Bias-Aware Manipulation Inference, or BAMI. The key point is that BAMI is training-free. It does not require updating the model or collecting a new labeled dataset. Instead, it applies two inference-time manipulations: coarse-to-fine focus and candidate selection.
Coarse-to-fine focus suggests a staged approach to localization. Rather than trying to land on the exact target immediately, the system first narrows down the region and then refines the search. Candidate selection addresses ambiguity by filtering or prioritizing among possible interface elements before making the final grounding decision.
That design is appealing because it matches how engineers often debug vision systems in production: first reduce the search space, then resolve the hard edge cases. BAMI turns that intuition into a method for GUI grounding.
What the paper actually shows
The abstract says the authors ran extensive experiments and found that BAMI significantly improves the accuracy of multiple GUI grounding models in a training-free setting. It also says ablation studies support the robustness of the approach across different parameter configurations.
The one concrete result called out in the abstract is on TianXi-Action-7B. With BAMI applied, accuracy on ScreenSpot-Pro rises from 51.9% to 57.8%. That is a gain of 5.9 percentage points, which is meaningful for a method that does not retrain the underlying model.
The abstract does not provide a full benchmark table, so we should not assume how BAMI performs across every dataset, model family, or interface type. It also does not list latency impact, compute overhead, or whether the inference manipulations add noticeable runtime cost. Those are important questions for deployment, but they are not answered in the source text provided here.
- Training-free: no model retraining is required.
- Targets two error sources: precision bias and ambiguity bias.
- Uses MPD attribution to diagnose failures.
- Reports a 51.9% to 57.8% accuracy gain on ScreenSpot-Pro for TianXi-Action-7B.
- Claims robustness through ablation studies across parameter settings.
Why developers should care
If you are building a GUI agent, the practical appeal of BAMI is straightforward: it offers a way to improve grounding quality without touching the model weights. That can matter a lot when the model is expensive to retrain, when you do not control the training pipeline, or when you want a safer path to iterate on behavior in production.
It is also useful as a debugging lens. Even if you do not adopt the method as-is, the paper’s split between precision bias and ambiguity bias gives you a vocabulary for analyzing failures in screenshot-based agents. If a model misses targets on dense, high-resolution screens, the issue may not be general “model weakness” but a specific inference-time mismatch between resolution handling and candidate selection.
For teams shipping automation tools, this kind of mitigation can be easier to operationalize than a full retrain. A training-free approach can be layered onto existing systems, tested behind a feature flag, and rolled back if it hurts performance elsewhere. The paper suggests that this is not just theoretical convenience; it can produce measurable gains on a difficult benchmark.
What is still unclear
The source material leaves some important engineering questions open. We do not get a detailed algorithm description in the abstract, so the exact mechanics of MPD, coarse-to-fine focus, and candidate selection would need to be read in the paper itself. We also do not know how sensitive the method is to different GUI styles, languages, or device form factors.
Another open question is whether the gains generalize beyond the reported benchmark and model example. The abstract mentions “various GUI grounding models,” but it does not enumerate them or show per-model results here. Likewise, the paper says the method is robust across parameter configurations, but the specific ranges and trade-offs are not included in the provided notes.
Even with those limits, the main takeaway is clear: BAMI treats GUI grounding errors as an inference problem that can be mitigated with better attention and candidate handling, not just more training. For developers working on GUI agents, that is a useful reminder that some accuracy gains may be available before you reach for a new model.
// Related Articles
- [RSCH]
TurboQuant and the SEO Shift for Small Sites
- [RSCH]
TurboQuant vs FP8: vLLM’s first broad test
- [RSCH]
LLMbda calculus gives agents safety rules
- [RSCH]
A simpler beamspace denoiser for mmWave MIMO
- [RSCH]
Why AI benchmark wins in cyber should scare defenders
- [RSCH]
Why Linux security needs a patch-wave mindset