Why Agentic RAG Is Better Than Static RAG for Real Work
Agentic RAG beats static RAG for complex, multi-step questions, but it costs more and needs tighter controls.

Agentic RAG is the better choice for complex questions that need retrieval, checking, and iteration.
Agentic RAG is the right default for any team that expects users to ask messy, multi-part questions, because one-shot retrieval fails exactly where production systems fail most: cross-source synthesis, follow-up reasoning, and verification. The article’s core example is telling. A query that asks for sales comparisons across quarters plus risk factors from an SEC filing is not a single retrieval task. It is at least three tasks: identify the metrics, fetch the right time slices, and ground the answer in the filing. Static RAG cannot do that cleanly, while an agent can decompose, route, retry, and assemble evidence before generation.
First argument: one-shot retrieval breaks on real queries
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
Traditional RAG assumes the problem is “find the nearest chunks, then answer.” That works for narrow factual lookups, but it falls apart when the question contains multiple intents. The article’s sales-and-filing example shows the failure mode clearly: a single embedding search over the whole prompt returns a blended compromise, not a targeted retrieval plan. In practice, that means the model gets a muddled context window and produces a polished but shallow answer.
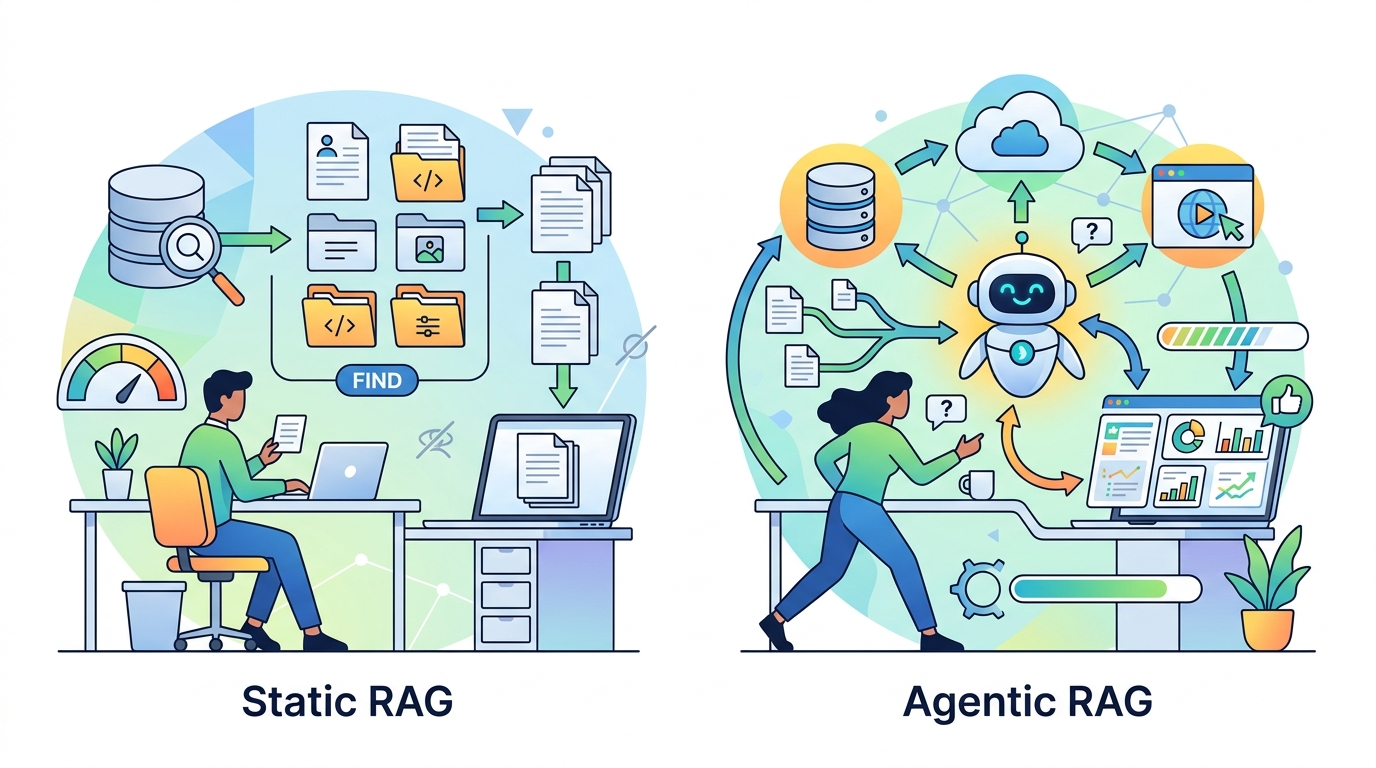
Agentic RAG fixes this by making retrieval conditional on what the system learns along the way. The agent can split the question into sub-questions, send each one to the right store, and then decide whether the evidence is enough. That is not a cosmetic upgrade. It changes retrieval from a static prelude to a reasoning loop. For products that serve analysts, support teams, or internal knowledge workers, that difference is the line between useful and unreliable.
Second argument: iteration is the feature that improves trust
The strongest part of the article is its emphasis on self-correction. Static RAG passes retrieved chunks straight to the generator, even when the context is weak or contradictory. Agentic RAG adds a validation step: check relevance, detect gaps, and retrieve again if the evidence does not hold up. That matters because hallucination is often not a model problem alone. It is a retrieval quality problem that the pipeline never notices.
This is why multi-hop retrieval and query reformulation matter so much. The article points to systems like RQ-RAG and RAG-Fusion as examples of better recall through decomposition and parallel reformulation. Those are not academic niceties. They are practical responses to the reality that users do not ask perfect questions and documents do not line up neatly. If the system can refine its search before answering, it earns more trust than a pipeline that guesses once and commits.
The counter-argument
The case against agentic RAG is straightforward: it is slower, more expensive, and harder to operate. Every extra retrieval step adds latency. Every agent turn adds token cost. Every tool call opens another failure mode. For simple FAQ bots, search over a small corpus, or single-hop lookups, static RAG is cheaper and often good enough. The article is right to admit that agentic RAG is overkill for straightforward factual questions.
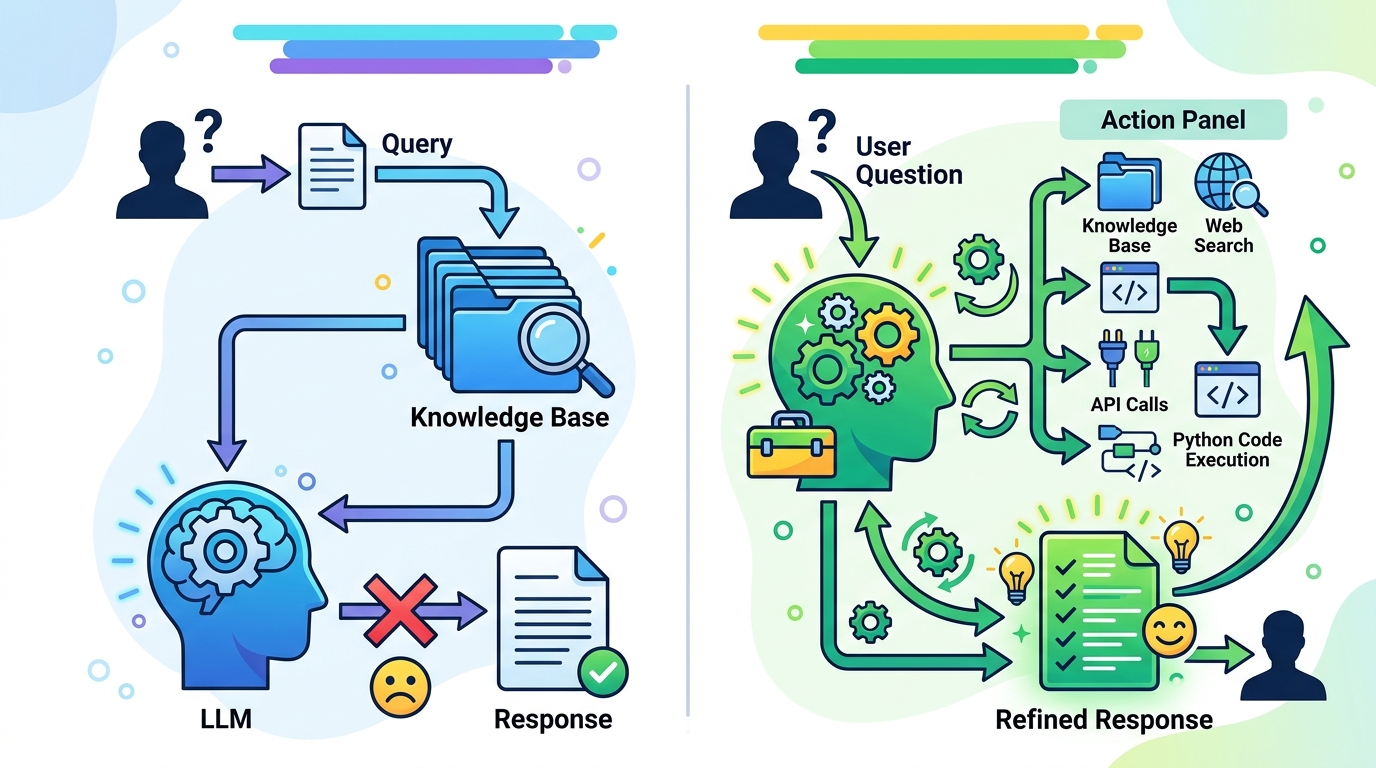
That objection is valid, but it does not overturn the argument. It defines the boundary. If your use case is simple retrieval, use static RAG and keep the system lean. If your use case requires synthesis across sources, time-sensitive lookups, or evidence checking, static RAG is the wrong architecture. The extra cost of agentic RAG is not waste in those cases. It is the price of getting answers that survive contact with reality.
What to do with this
If you are an engineer or PM, stop asking whether agentic RAG is “better” in the abstract and start classifying your queries. Build static RAG for single-hop questions, then add agent behavior only where decomposition, routing, or self-correction clearly improves answer quality. Measure latency, token spend, and retrieval accuracy separately. If the system needs multi-source synthesis, use agents. If it does not, do not pay the complexity tax. For founders, the product decision is even simpler: sell agentic RAG only where the workflow is already evidence-heavy, because that is where the architecture creates a real advantage.
// Related Articles
- [RSCH]
How VLMs Learned Complex Scene Descriptions
- [RSCH]
Visual Pretraining Beats Text-Only in Language Models
- [RSCH]
PHINN-EEG brings topology to dream-state EEG
- [RSCH]
Google’s Android Bench update exposes Gemini’s gap
- [RSCH]
Benchmarks should not pick your LLM in 2026
- [RSCH]
Rust Breaks Into TIOBE’s Top 10