Ollama flaw can leak process memory remotely
A critical Ollama bug can leak process memory remotely, exposing keys, prompts, and user data across exposed servers.

A critical Ollama bug can leak process memory from exposed servers.
Ollama has a serious security problem: a remote attacker can send a crafted GGUF file, trigger an out-of-bounds read, and pull data out of process memory. The flaw is tracked as CVE-2026-7482, carries a CVSS score of 9.1, and Cyera has dubbed it Bleeding Llama.
| Fact | Value |
|---|---|
| CVE | CVE-2026-7482 |
| CVSS score | 9.1 |
| Likely exposed servers | 300,000+ |
| Ollama GitHub stars | 171,000+ |
| Ollama forks | 16,100+ |
| Fixed in | 0.17.1 |
What the bug actually does
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
Ollama is popular because it lets people run large language models locally instead of sending prompts to a cloud service. That convenience comes with a bigger attack surface, especially when the REST API is exposed to a network.

According to the CVE description, versions before 0.17.1 accept attacker-supplied GGUF files through the /api/create endpoint. If the declared tensor offset and size are larger than the real file, the server can read past the heap buffer during quantization in fs/ggml/gguf.go and server/quantization.go.
GGUF, short for GPT-Generated Unified Format, is the file format Ollama uses to store and load models locally. The bug lives in code that uses Go’s unsafe package, which means the language’s normal memory safety guarantees do not apply in that path.
- Attack surface: exposed Ollama servers with the REST API reachable over the network
- Trigger: a malformed GGUF file with inflated tensor metadata
- Impact: remote memory disclosure from the Ollama process
- Likely loot: environment variables, API keys, system prompts, and active chat data
Why this leak matters in real deployments
This is not the kind of flaw that just dumps a few bytes and goes away. If the attacker can cause Ollama to serialize the resulting model artifact and push it outward, the memory contents can be exfiltrated through the /api/push endpoint to an attacker-controlled registry.
Cyera security researcher Dor Attias described the risk in blunt terms: “An attacker can learn basically anything about the organization from your AI inference — API keys, proprietary code, customer contracts, and much more.” He added that the impact gets worse when engineering teams wire Ollama into tools like Claude Code, because tool outputs can also end up in the process heap.
“An attacker can learn basically anything about the organization from your AI inference — API keys, proprietary code, customer contracts, and much more.” — Dor Attias, Cyera
That quote matters because it changes how you think about local AI servers. The danger is not limited to model weights or prompt text. It reaches the surrounding workflow, including secrets that were never meant to leave the box.
For teams running Ollama in production or in shared internal environments, the practical lesson is simple: if the API is reachable from anywhere outside a tightly controlled network, treat it like a high-value target.
How the attack chain works
The reported exploitation path is straightforward and ugly. An attacker uploads a crafted GGUF file, calls /api/create to trigger model creation, then uses /api/push to move leaked memory data out to an external registry.
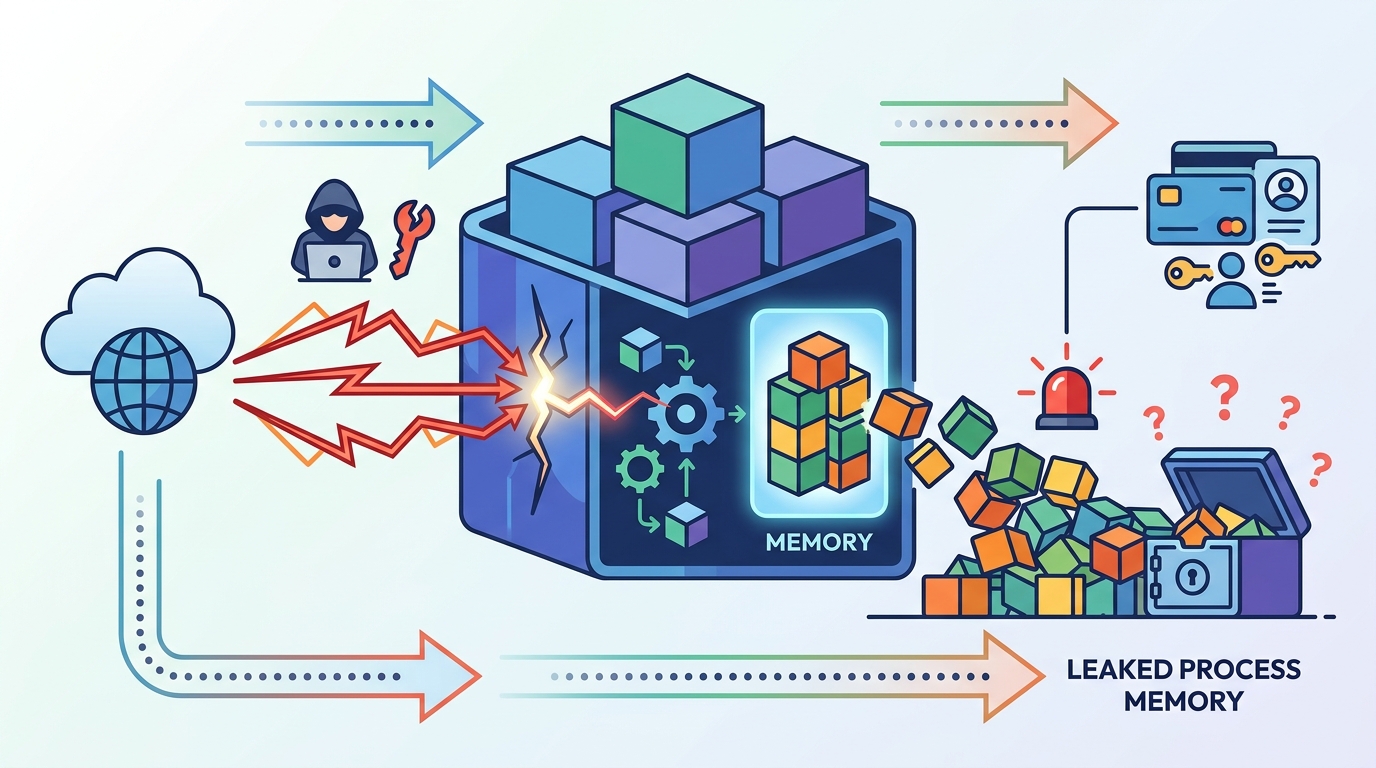
That chain matters because each step is ordinary on its own. File upload, model creation, and model publishing are normal Ollama operations. The bug turns those legitimate actions into a memory disclosure path.
- Step 1: send a malicious GGUF file with oversized tensor metadata
- Step 2: invoke
/api/createto force the out-of-bounds read - Step 3: use
/api/pushto exfiltrate the leaked heap contents
Cyera says the flaw likely affects more than 300,000 servers worldwide. That number is a reminder that local AI tooling is no longer a hobbyist corner case. It is infrastructure, and infrastructure gets scanned.
There is also a broader point here about trust. Teams often assume that because a model runs locally, the risk stays local too. This bug shows how a single exposed endpoint can turn a private inference server into a data source for an attacker.
What to compare, patch, and watch next
Ollama is not the only project dealing with memory safety and update-chain issues, but this disclosure is especially sharp because it hits both confidentiality and operational trust. The fix for CVE-2026-7482 is available in Ollama 0.17.1, so version checks matter right away.
There is also a separate Windows problem in Ollama’s updater, tracked by CVE-2026-42248 and CVE-2026-42249. Those flaws can be chained into persistent code execution on Windows systems that auto-start the desktop client and poll for updates.
- CVE-2026-7482: heap out-of-bounds read in the GGUF loader, fixed in 0.17.1
- CVE-2026-42248: missing signature verification in the Windows updater
- CVE-2026-42249: path traversal in the Windows updater staging path
- Windows exposure window: versions 0.12.10 through 0.17.5 are called out in the disclosure
- Default behavior: AutoUpdateEnabled is on unless admins turn it off
The defensive checklist is short but important: update Ollama, restrict network access, put an authentication proxy or API gateway in front of every instance, and audit whether any server is reachable from the internet. If you use the Windows client, disable automatic updates and remove the Startup folder shortcut until the update path is verified.
If your organization treats local LLM hosting as a safe internal tool, this is the kind of incident that should change the policy. The next question is not whether a public Ollama instance can be found, but how many already are and whether they are exposing prompts, keys, or customer data right now.
For related coverage, see our guide on exposed AI services and common misconfigurations.
// Related Articles
- [RSCH]
How VLMs Learned Complex Scene Descriptions
- [RSCH]
Visual Pretraining Beats Text-Only in Language Models
- [RSCH]
PHINN-EEG brings topology to dream-state EEG
- [RSCH]
Google’s Android Bench update exposes Gemini’s gap
- [RSCH]
Benchmarks should not pick your LLM in 2026
- [RSCH]
Rust Breaks Into TIOBE’s Top 10