OmniAgent brings active perception to video understanding
OmniAgent turns long-video understanding into an active reasoning loop that scales with turns, not video length.

OmniAgent turns long-video understanding into an active reasoning loop that scales with turns, not video length.
- Research org: Unspecified in arXiv abstract
- Core data: 50.5% vs. 47.3% on LVBench
- Breakthrough: POMDP-based Observation-Thought-Action cycle with persistent textual memory
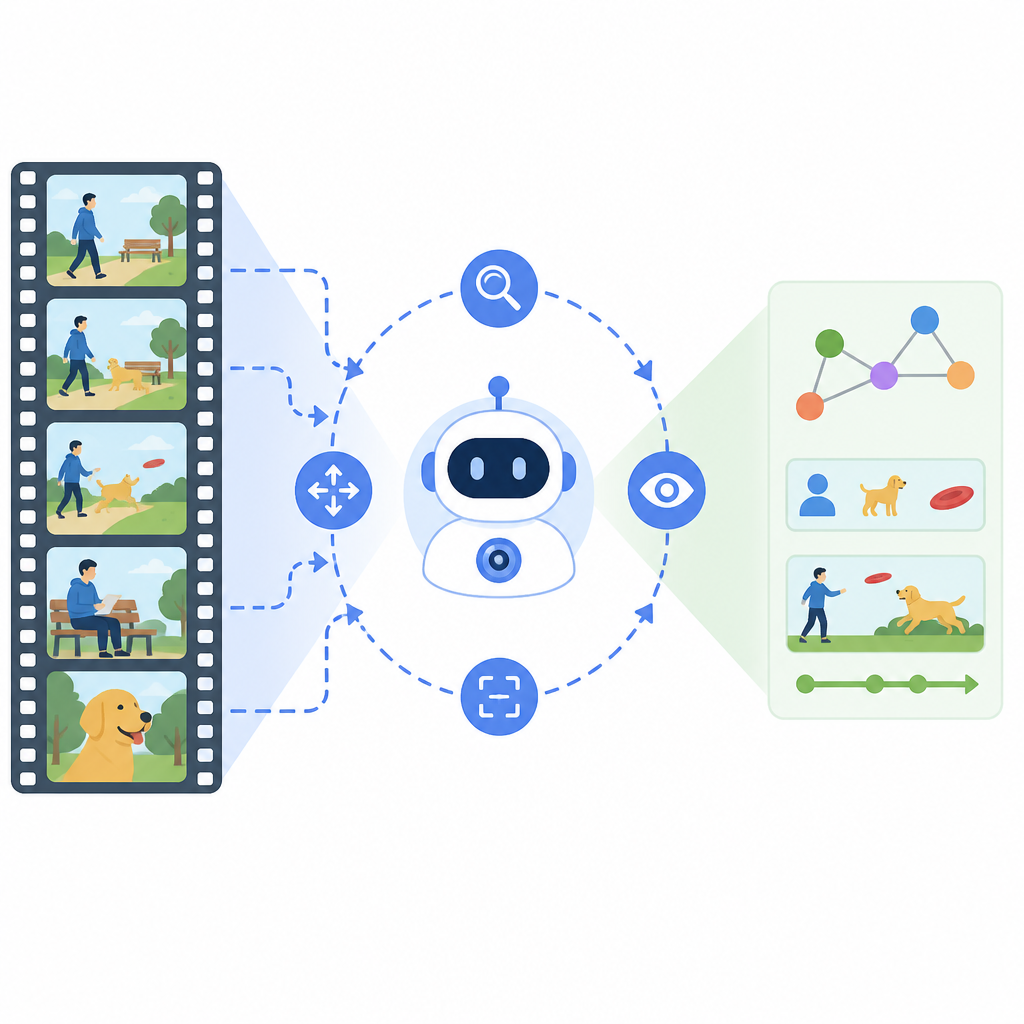
Native Active Perception as Reasoning for Omni-Modal Understanding argues that long-video models should stop treating every frame as equally important. Instead of passively scanning an entire video from start to finish, OmniAgent decides when to observe, think, and act, then stores the useful audio-visual evidence in text memory so later reasoning does not have to keep dragging the full video context around.
That matters because the usual “watch-it-all” approach gets expensive fast as videos get longer. This paper is trying to fix a very practical bottleneck: if context cost scales with duration, then long-form video understanding becomes harder to deploy, harder to scale, and harder to make interactive. The authors’ answer is to make perception itself part of the reasoning loop.
What problem the paper is fixing
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
Traditional long-video systems are passive. They process frames uniformly, even when a user’s question only needs a few moments of the clip. The abstract says this creates unnecessary compute cost, and it also means the model’s context burden grows with video length. In other words, longer input does not just mean more data; it means the reasoning system has to carry more baggage.

The paper also points out that some interactive frameworks already exist, but they still rely on a global pre-scan. That means they may be more selective than a naive baseline, but they do not fully break the dependence on video length. OmniAgent is positioned as the first native omni-modal agent that makes selective perception the default behavior rather than an add-on.
For developers, the distinction is important. A model that can only answer after ingesting everything is fine for offline analysis, but it is awkward for products that need fast iteration, lower inference cost, or step-by-step interactive exploration of a long clip. The paper is pushing toward a design where the model asks for more evidence only when it needs it.
How OmniAgent works in plain English
The core idea is to model video understanding as a POMDP, or partially observable Markov decision process. That sounds formal, but the practical meaning is simple: the agent does not assume it sees the whole truth at once. It repeatedly cycles through Observation, Thought, and Action, choosing what to inspect next based on what it already knows.
Instead of keeping raw video context alive throughout the whole conversation, OmniAgent selectively distills audio-visual cues into a persistent textual memory. That memory becomes the working state for reasoning. The result is a system that can separate reasoning complexity from raw video duration, which is the main architectural claim in the abstract.
To make this work, the authors introduce two training components. The first is Agentic Supervised Fine-Tuning, which bootstraps native active perception using best-of-N trajectory synthesis plus dual-stage quality control. The second is Agentic Reinforcement Learning with TAURA, short for Turn-aware Adaptive Uncertainty Rescaled Advantage, which uses turn-level entropy to guide credit assignment toward the turns where important discoveries happen.
In practical terms, the training story is about teaching the agent not just to answer questions, but to choose good questions for itself. That is the difference between a model that passively consumes context and one that can actively search for the evidence it needs.
What the paper actually shows
The abstract reports results across ten benchmarks, including VideoMME and LVBench. It says OmniAgent achieves state-of-the-art performance among open-source models, but the abstract does not list the full benchmark table, so those details are not available in the source text provided here.
One concrete number does stand out: on LVBench, the 7B OmniAgent outperforms Qwen2.5-VL-72B, a model that is 10 times larger, with 50.5% versus 47.3%. That is the clearest signal in the abstract that active perception can matter more than raw parameter count for this kind of task.
The paper also claims positive test-time scaling. That means performance improves as the number of reasoning turns increases. This is a useful property because it suggests the agent can trade extra deliberation for better answers in a controlled way, rather than being locked into a single fixed pass over the video.
That said, the abstract stops short of giving the exact cost profile of those extra turns. It also does not provide latency, memory usage, or throughput numbers in the source notes here, so the practical compute tradeoff remains something readers would need to inspect in the full paper.
Why developers should care
If you are building video assistants, search tools, moderation systems, or any workflow where the question may only depend on a small part of a long clip, this paper points to a different architecture choice. Instead of scaling context windows and hoping brute force is enough, you can design the model to actively gather evidence.
That opens the door to systems that are more efficient on long content and potentially easier to control. A persistent textual memory can also be easier to inspect than a giant raw multimodal context, which may help with debugging and traceability. The paper does not prove those operational benefits directly, but the design clearly aims in that direction.
- Active perception can reduce unnecessary full-video processing.
- Turn-based reasoning may improve long-video accuracy without matching model size.
- Text memory can make multimodal reasoning more inspectable than raw frame stuffing.
Limits and open questions
The biggest limitation in the abstract is that it gives only a high-level view of the method. We know the training setup names, the POMDP framing, and the memory design, but not the implementation details that would matter for reproduction, such as action space design, memory schema, or how the agent chooses what to observe next.
The abstract also does not tell us how expensive test-time scaling is, only that performance improves with more reasoning turns. For real deployments, that tradeoff is crucial. An agent that gets better when it thinks longer is useful, but only if the extra thinking is affordable in the product context.
Finally, the benchmark story is promising but still bounded by the abstract. We have one explicit comparison on LVBench and a claim of ten-benchmark state-of-the-art performance among open-source models, but not the full set of numbers here. So the safest reading is that OmniAgent looks like a strong step toward active multimodal reasoning, not a finished answer to every long-video problem.
Even with those caveats, the paper’s direction is clear: long-video understanding may work better when the model behaves less like a recorder and more like an investigator. For engineers, that is a useful mental shift, because it changes the optimization target from “process everything” to “ask for the right evidence at the right time.”
// Related Articles
- [RSCH]
LOCUS opens U.S. local law for legal AI
- [RSCH]
Turing-RL trains user simulators by fooling judges
- [RSCH]
ArXiv AI papers push agents, memory, and data
- [RSCH]
ReproRepo scales reproducibility audits with GitHub issues
- [RSCH]
Variable-Width Transformers cut wasted capacity
- [RSCH]
VERITAS lets robots verify and improve at runtime