Tag
1 articles
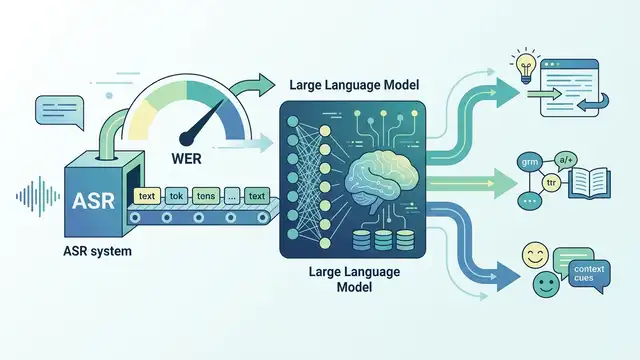
This paper tests decoder-based LLMs as ASR evaluators and finds they beat WER on human agreement, with 92–94% on one task.