Tag
1 articles
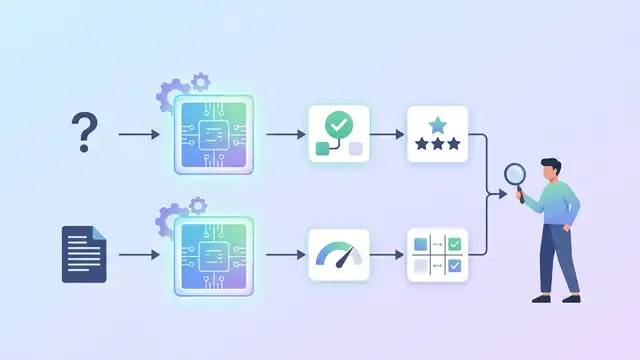
A diagnostic toolkit shows LLM judges can look stable on average while still being unreliable on individual inputs.