Humanoid-GPT scales motion tracking with a GPT-style model
Humanoid-GPT uses a GPT-style Transformer and 2B motion frames to improve zero-shot whole-body motion tracking.

Humanoid-GPT uses a GPT-style Transformer and 2B motion frames to improve zero-shot whole-body motion tracking.
- Research org: Unspecified in arXiv abstract
- Core data: 2B-frame retargeted corpus
- Breakthrough: GPT-style causal Transformer trained on unified mocap and in-house data
Most motion trackers in humanoid control are built to handle a narrow slice of the world: a limited dataset, a limited set of movements, and a trade-off between agility and generalization. This paper argues that the way out is not a better shallow tracker, but scale—more data, more model capacity, and a structure that can model motion as a sequence.
For engineers working on humanoid control, that matters because zero-shot motion tracking is the difference between a system that only works on the motions it was tuned for and one that can adapt to unseen behaviors without retraining for every new task. The paper’s claim is that a single generative Transformer can cover both highly dynamic motions and broader generalization if it is trained at the right scale.
What problem the paper is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The abstract frames the problem clearly: prior trackers are shallow MLP-based systems, and they are constrained by scarce data. That scarcity creates a practical tension. If you optimize for fast, agile movement, you may lose generalization. If you push for broader generalization, you may give up the ability to track complex, high-dynamic behaviors.

That trade-off is a familiar engineering problem. In control systems, narrow training distributions often produce brittle behavior when the real input drifts outside the expected range. Here, the authors are trying to move past that by scaling both the dataset and the model architecture instead of relying on a compact tracker that has to do everything with limited supervision.
The paper’s target is whole-body control, not a toy motion benchmark. That means the underlying challenge is not just predicting poses, but tracking full-body movement robustly across diverse motions and control tasks.
How Humanoid-GPT works in plain English
The core idea is to treat motion tracking more like sequence modeling. Humanoid-GPT is described as a GPT-style Transformer with causal attention, which means it processes motion as an ordered stream and predicts the next steps based on what came before. That is a natural fit for motion, where timing and continuity matter.
Instead of training on a small set of examples, the model is pre-trained on a 2B-frame retargeted corpus. The paper says this corpus unifies all major mocap datasets with large-scale in-house recordings. In practical terms, that suggests the authors are trying to build one broad motion foundation rather than many small, task-specific trackers.
The “retargeted” part is important because motion data often comes from different sources, body rigs, and capture setups. A unified corpus implies a normalization step that makes these sources usable together. The abstract does not spell out the full preprocessing pipeline, so we should not assume more than that, but the direction is clear: standardize the motion data, then scale training around it.
Another key design choice is causal attention. For developers, that signals an autoregressive setup: the model uses past motion context to inform the next output. That is different from a shallow MLP tracker that tries to map inputs directly without the same kind of sequential structure.
What the paper actually shows
The abstract says the authors ran extensive experiments and scaling analyses. It also says the model establishes a new performance frontier, with robust zero-shot generalization to unseen tasks while still tracking highly dynamic and complex motions. That is the headline result.
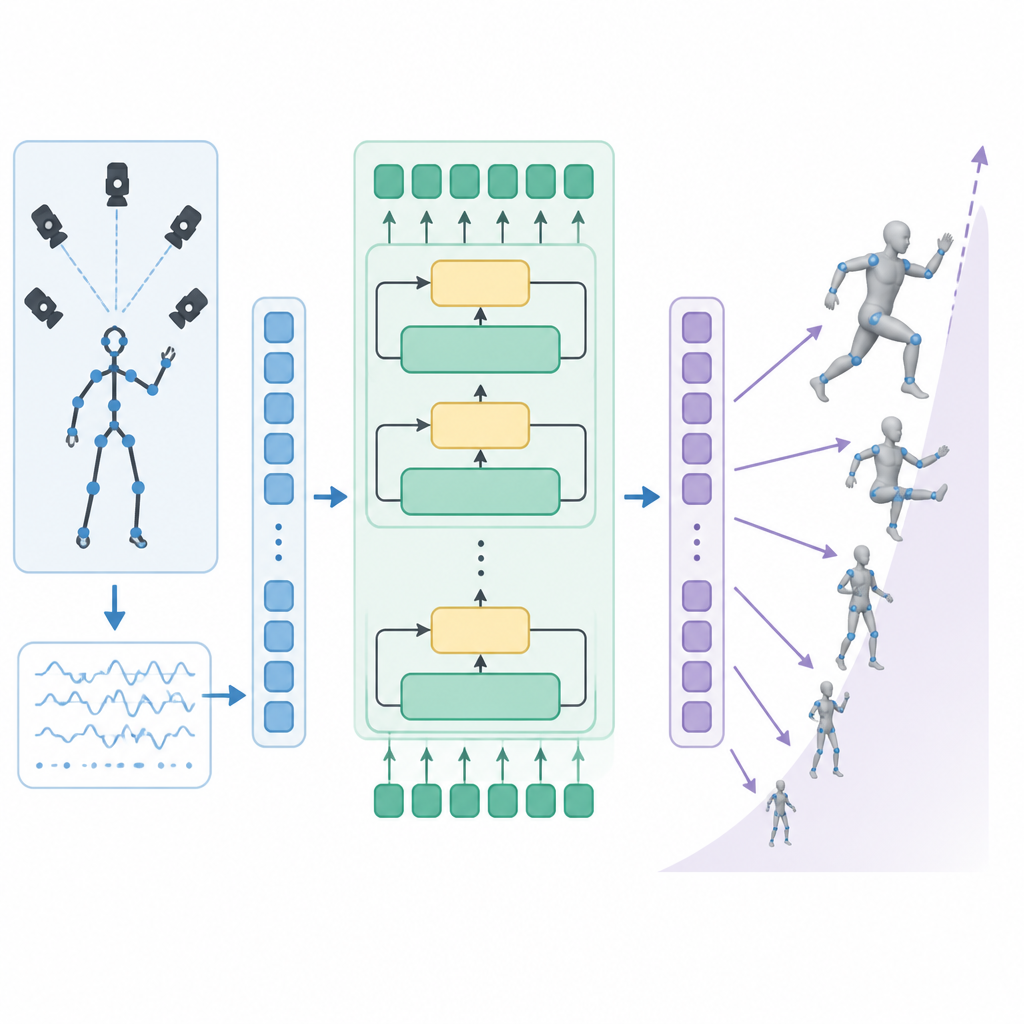
What the abstract does not provide is benchmark numbers. There are no exact scores, no named test suites, and no percentage gains in the text provided here. So the safe reading is that the paper claims a qualitative and comparative improvement, but the abstract alone does not let us quantify the size of that improvement.
Still, the phrasing matters. “Zero-shot generalization to unseen motions and control tasks” suggests the model is not just overfitting to a fixed motion library. “Highly dynamic behaviors” suggests it can maintain control when movement gets fast or complex. Together, those are the two properties that usually pull in opposite directions in smaller trackers.
There is also an implied scaling result: the authors believe the gains come from scaling both data and model capacity, not from one of those factors alone. That is a useful signal for teams deciding where to invest. If the paper holds up under closer inspection, it suggests that motion tracking may benefit from the same general recipe seen in other sequence modeling domains: more diverse data plus a larger Transformer.
Why developers should care
If you build humanoid control systems, simulation tooling, motion imitation pipelines, or robotics research stacks, this paper points to a concrete architectural shift. Instead of treating motion tracking as a small regression problem, it treats it as a large-scale generative sequence problem. That changes how you think about data collection, training infrastructure, and model design.
It also raises a practical possibility: one model that can handle a broader range of motions without per-task retraining. For teams working on general-purpose humanoids, that could reduce the amount of hand-tuning required for every new movement family or control scenario.
At the same time, the abstract leaves important questions open. It does not describe inference cost, latency, or deployment complexity. It also does not say how much of the gain comes from the architecture versus the size and diversity of the corpus. And because the source is an abstract, we do not get failure cases, ablation details, or evidence about how the model behaves outside the reported experimental setup.
What is still missing
The biggest limitation in the source material is simple: the abstract is high-level. We know the model uses causal attention and a 2B-frame corpus, but we do not know the exact training recipe, the motion task definitions, or the evaluation protocol. Those details matter a lot if you want to reproduce the result or compare it against your own stack.
We also do not get benchmark numbers in the abstract, so there is no way to judge how large the performance gap is. The claim of a “new performance frontier” is promising, but it is still a claim until you inspect the full paper and its experimental tables.
Even so, the direction is useful. The paper is making a strong bet that motion tracking will improve when it is built like a modern sequence model and trained on a much larger motion corpus. For practitioners, that is a reminder that data scale and model structure are not just training details—they can be the main lever for generalization.
Bottom line
Humanoid-GPT is a scale-first approach to humanoid motion tracking: unify a huge motion corpus, use a GPT-style causal Transformer, and aim for zero-shot generalization without sacrificing dynamic motion tracking. The abstract does not prove every operational detail, but it does make a clear engineering argument about where the next gains may come from.
- Scale motion data before assuming a small tracker can generalize.
- Sequence models may fit whole-body control better than shallow MLP trackers.
- The abstract promises strong zero-shot behavior, but benchmark details are not provided here.
// Related Articles
- [RSCH]
CRDTs keep replicas in sync without locks
- [RSCH]
Post-Deterministic Systems for Autonomous Infra
- [RSCH]
Causal methods for measuring task learnability
- [RSCH]
RL Training That Hands Off Control Gradually
- [RSCH]
OmniGameArena benchmarks VLM game agents better
- [RSCH]
TurboQuant cuts KV cache memory 6x in Google tests