How neuron selectivity changes as models scale
A study of Rosetta Neurons finds shared neuron patterns grow sublinearly and become more selective in bigger models.
A study of Rosetta Neurons finds shared neuron patterns grow sublinearly and become more selective in bigger models.
- Research org: Unspecified in arXiv abstract
- Core data: Up to 30B parameters in language models and 5B in vision models
- Breakthrough: Measures how Rosetta Neurons change with scale and models the effect analytically
For engineers working on large models, this paper is interesting because it moves the scaling-law conversation below loss curves and into the structure of individual neurons. Instead of asking only whether a model gets better as it gets bigger, the authors ask whether the kinds of neurons inside the model also change in a predictable way.
That matters for interpretability, debugging, and data curation. If some neuron populations become more shared, more selective, or more domain-specific as scale increases, then the internal behavior of a model may become easier to reason about in some ways and harder in others.
What problem this paper is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The paper is trying to answer a simple but underexplored question: do neuron populations evolve predictably with scale, the way loss and other macroscopic metrics do? The authors argue that scaling laws have mostly focused on surface-level outcomes, while the internal organization of neurons has received less systematic attention.
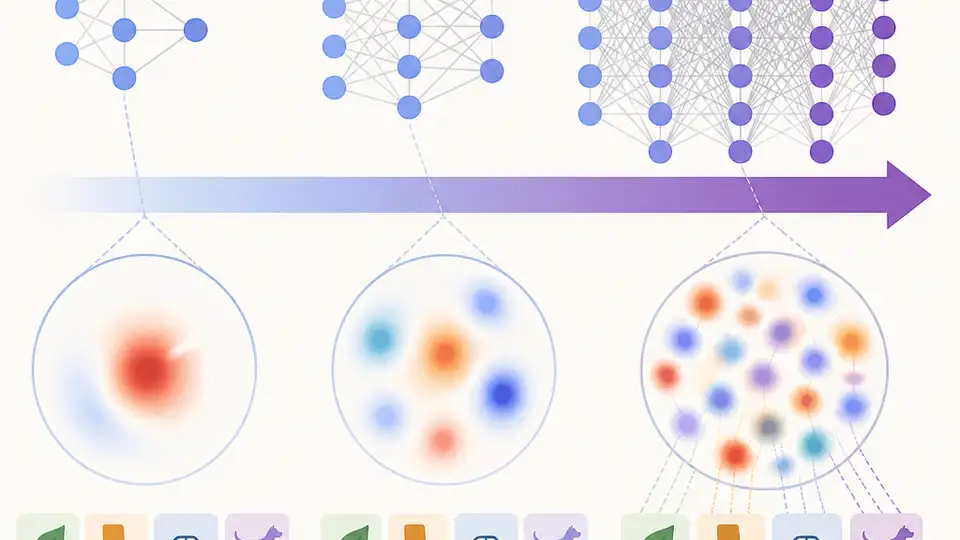
To study that, they build on a previously characterized class of neurons called Rosetta Neurons. These are neurons whose activation patterns are similar across independently trained models. That makes them a useful probe for asking whether shared internal structure persists, expands, or fragments as models get larger.
The core concern is not just interpretability for its own sake. If neuron-level structure follows a law with scale, then teams working on model inspection, feature discovery, or targeted data selection may be able to anticipate how internal representations shift as they move to larger systems.
How the method works in plain English
The authors analyze Rosetta Neurons in separate sets of language models and vision models. The language models go up to 30B parameters, and the vision models go up to 5B parameters. They then measure how the population of these neurons changes as model size grows.
One key idea is to look at both absolute count and relative fraction. A population can get larger in raw numbers while still becoming a smaller slice of the whole network. That distinction matters here, because the paper reports exactly that pattern for Rosetta Neurons.
They also look at selectivity, monosemanticity, and domain specialization. In plain terms, they ask whether these neurons become more narrowly focused on one kind of feature or concept as models scale, and whether they separate more clearly from the rest of the neuron population.
Beyond measurement, the paper includes an analytical model. The model balances feature utility against limited neuron capacity, which the authors use to explain both the sublinear scaling pattern and the polarization effect they observe.
What the paper actually shows
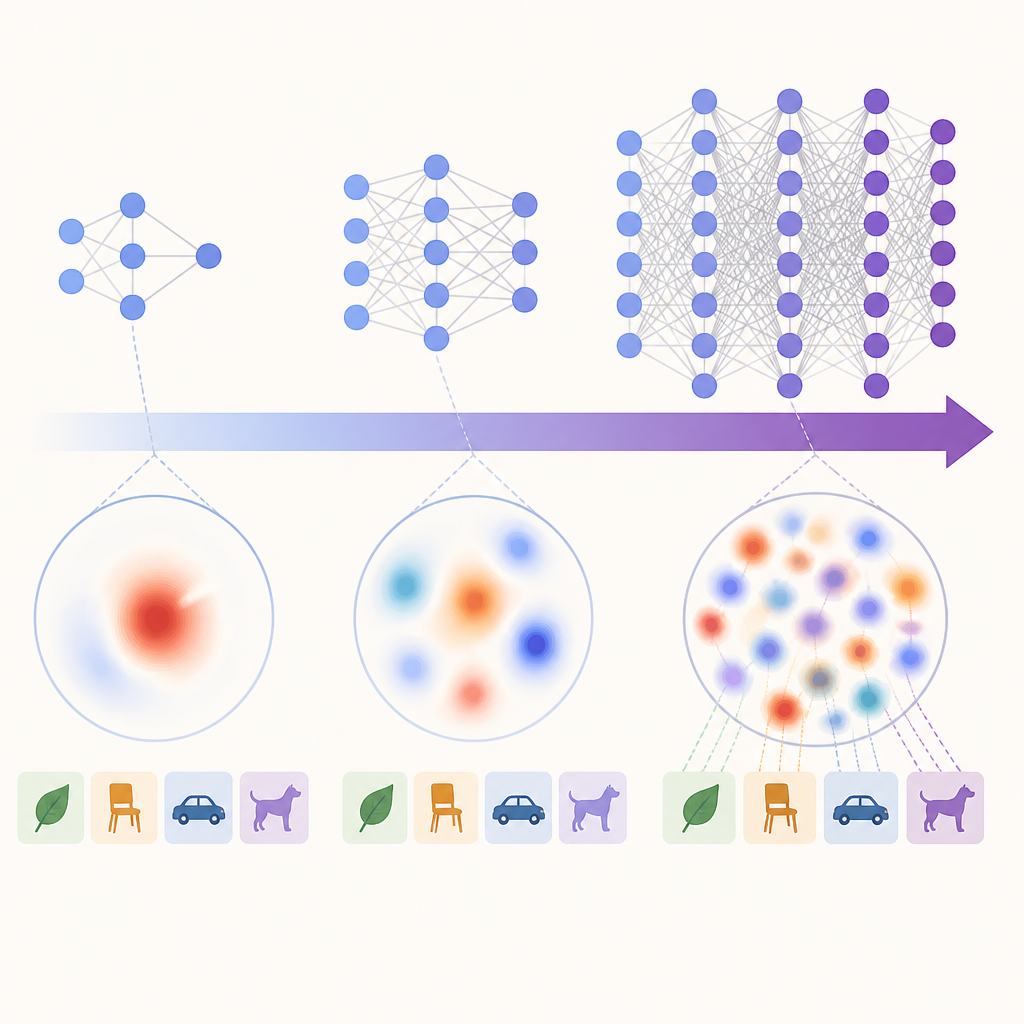
The headline result is a sublinear power law for Rosetta Neurons. As model size increases, the absolute number of these neurons grows, but their fraction of the total neuron count shrinks. In other words, bigger models have more of them, but they take up less of the network.
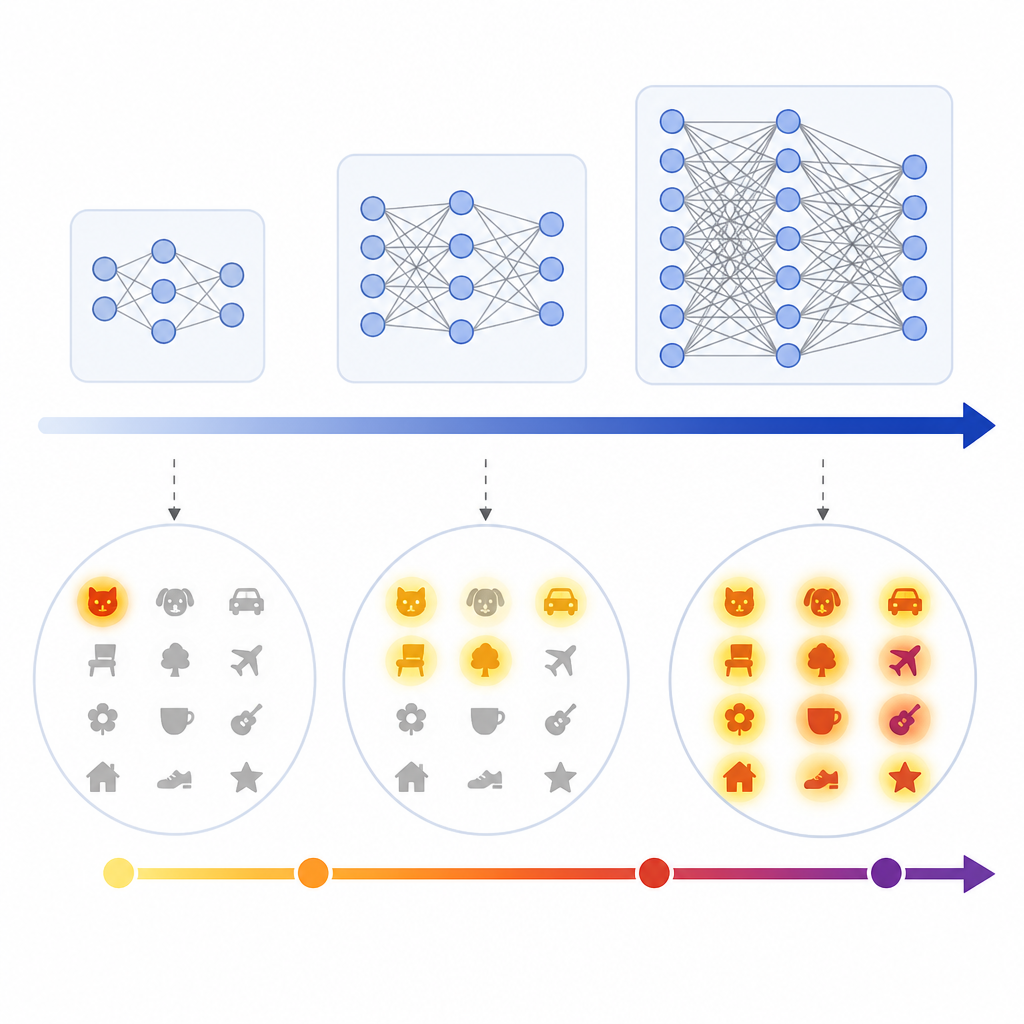
The second major result is what the authors call a Neuron Polarization Effect. Rosetta Neurons become more selective and increasingly monosemantic with scale, while a growing non-Rosetta population remains less selective. The paper frames this as a separation between a more interpretable shared population and a broader, less selective one.
The authors also report that Rosetta Neurons become more domain-specialized with scale. They illustrate this with a targeted data-filtering case study for continued pretraining, showing how the selectivity of these neurons can be used in a practical data-selection setting.
What the abstract does not give is benchmark-style performance numbers for downstream tasks. There are no accuracy tables, no loss deltas, and no explicit ablation scores in the abstract, so it is not possible to claim quantified gains beyond the scaling trends and qualitative case study described there.
Why developers should care
If you build or fine-tune large models, this paper suggests that internal representations may not just get bigger; they may reorganize in structured ways. That could affect how you think about interpretability tools, neuron tracing, feature discovery, and dataset curation.
The practical implication is that neuron populations may become more uneven as scale increases. A smaller fraction of neurons may carry more of the shared, highly selective structure, while the rest of the network becomes less selective. That is useful to know if you are trying to isolate concepts, debug behavior, or identify data that reinforces a desired domain.
The data-filtering case study hints at a workflow engineers may care about: use neuron selectivity to help choose continued-pretraining data. The abstract does not provide enough detail to treat this as a general recipe, but it does show the authors are thinking about operational uses, not just interpretability metrics.
Limits and open questions
The abstract is strong on trends and light on operational specifics. It does not say how many models were included, how Rosetta Neurons were operationalized in detail, or how robust the findings are across architectures beyond the language and vision families mentioned.
It also does not tell us how the analytical model was validated against alternative explanations, or whether the same scaling behavior appears in other neuron classes. Those are important questions if this result is going to become a broader rule rather than a property of one carefully chosen population.
Another open question is how far these neuron-level scaling laws generalize to tasks that matter in production. The paper links scale to universality, selectivity, and specialization, but the abstract does not show whether those properties translate into easier debugging, better safety tooling, or better downstream accuracy.
Still, the main takeaway is clear: the internal structure of large models may itself obey scaling behavior, and that behavior is not just about quantity. It is also about how shared features concentrate, how selectivity sharpens, and how specialized neuron groups separate from the rest of the network.
Bottom line
This paper argues that neuron populations have their own scaling law. Rosetta Neurons grow in number with model size, but they occupy a smaller share of the network and become more selective, more monosemantic, and more domain-specific as models get bigger.
For developers, that means scale may change not only what a model can do, but also how its internal features are organized and how easy they are to inspect or leverage. The abstract stops short of giving benchmark numbers, but it does provide a concrete framework for thinking about model internals as a scaling phenomenon.
- Rosetta Neurons are used as the probe for shared internal structure across models.
- Language models up to 30B parameters and vision models up to 5B parameters were analyzed.
- The paper connects neuron selectivity, monosemanticity, and specialization to model scale.
// Related Articles
- [RSCH]
CRDTs keep replicas in sync without locks
- [RSCH]
Post-Deterministic Systems for Autonomous Infra
- [RSCH]
Causal methods for measuring task learnability
- [RSCH]
RL Training That Hands Off Control Gradually
- [RSCH]
OmniGameArena benchmarks VLM game agents better
- [RSCH]
TurboQuant cuts KV cache memory 6x in Google tests