Vector Policy Optimization boosts search diversity
VPO trains language models to produce diverse solutions that work better in test-time search.

VPO trains language models to produce diverse solutions that work better in test-time search.
- Research org: Unspecified in arXiv abstract
- Core data: Four tasks
- Breakthrough: Trains policies for vector-valued rewards and solution diversity
Language models are increasingly being used inside search loops, not just as one-shot generators. That matters because the model is no longer judged only on a single answer; it has to produce a useful spread of candidates that a downstream search procedure can rank, filter, or combine.
This paper argues that the usual post-training setup is mismatched to that reality. If you optimize only a scalar reward, you can end up with low-entropy outputs that are good at one objective but poor at supporting inference-time search. Vector Policy Optimization, or VPO, is the paper’s answer to that problem.
What problem this paper is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The abstract focuses on a practical shift in how LLMs are used. Systems like AlphaEvolve-style search procedures select rollouts using multiple task-specific reward functions, so the model needs to be useful across a range of downstream preferences rather than a single fixed score.

Standard LLM post-training usually optimizes a pre-specified scalar reward. According to the paper, that can push models toward narrow, low-diversity behavior. In other words, the model may become very good at producing one kind of answer, but less good at producing the varied candidates that search needs.
That is the core tension this work tries to address: if test-time search is going to choose among many candidates, the policy itself should be trained to generate candidates that differ in meaningful ways. The paper frames diversity as a feature, not a bug.
How VPO works in plain English
VPO stands for Vector Policy Optimization, and the key idea is simple to describe even if the implementation is specialized. Instead of treating reward as a single number, VPO treats it as a vector. That matches settings where reward naturally breaks into multiple dimensions, such as per-test-case correctness in code generation or multiple user personas or reward models.
The paper says VPO is essentially a drop-in replacement for the GRPO advantage estimator. That means it is designed to fit into an existing RL post-training pipeline rather than requiring a completely new training stack. The twist is that it trains the model to output a set of solutions, with individual solutions specializing to different trade-offs in the vector reward space.
In practical terms, that means the model is not only learning to maximize one target. It is learning to cover more of the solution space so that later search has better raw material to work with. For engineers, that is the important shift: the training objective is aligned with how the model will actually be used at inference time.
What the paper actually shows
The abstract says VPO was evaluated across four tasks. It does not provide the task names or benchmark scores in the provided text, so there are no numeric results to quote here.
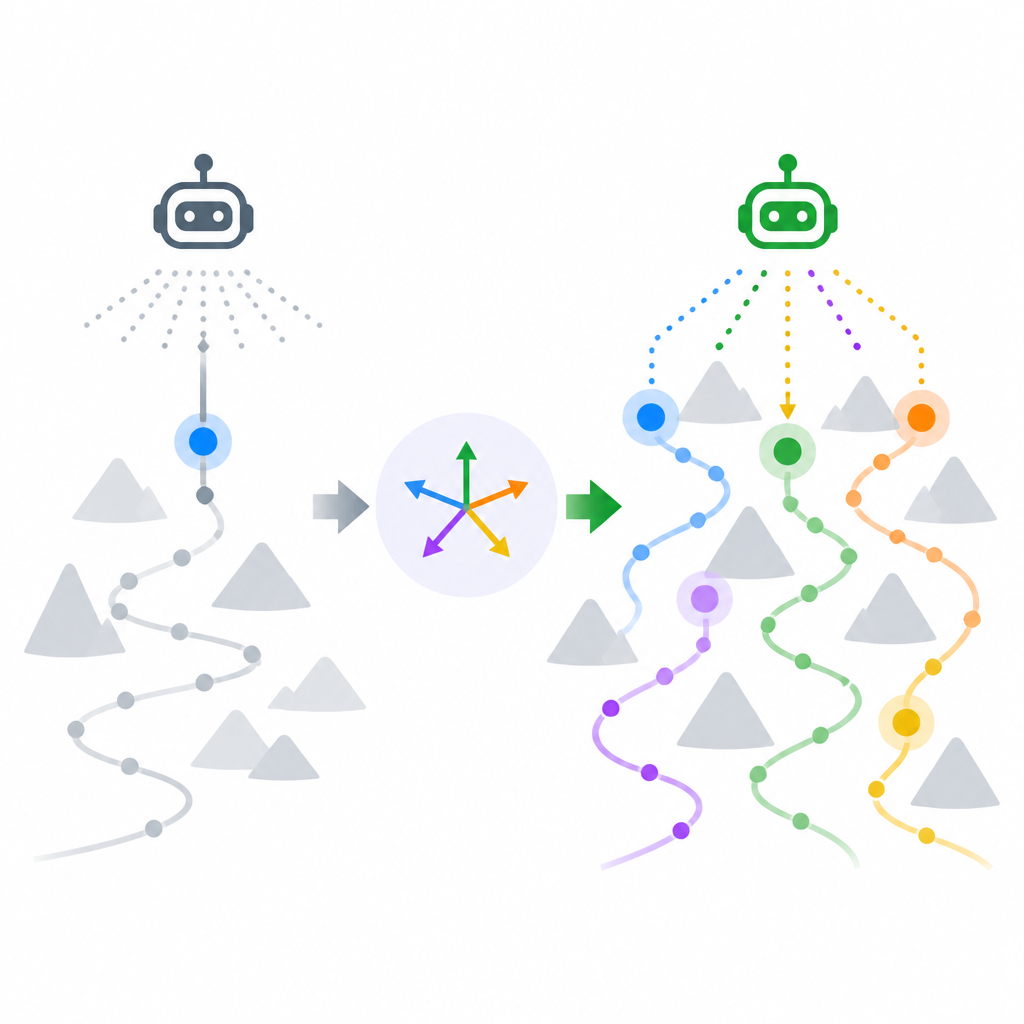
What it does claim is directionally strong: across those four tasks, VPO matches or beats the strongest scalar RL baselines on test-time search metrics such as pass@k and best@k. The gap reportedly grows as the search budget increases, which is exactly when better diversity should matter most.
The paper also makes a more striking claim about evolutionary search: VPO models unlock problems that GRPO models cannot solve at all. That suggests the diversity learned during training can change not just ranking performance, but whether search succeeds in the first place.
Because the abstract does not include the benchmark table, the exact magnitude of the gains is not available in the source material here. Still, the qualitative takeaway is clear: when search has more room to explore, a policy trained for diversity appears to benefit more than a policy trained for a single scalar objective.
Why developers should care
If you are building agentic systems, code generators, or any pipeline that samples many candidate solutions before selecting one, this paper points to an important design principle: train for searchability, not just final-answer quality. A model that looks slightly worse under a single-score training objective may actually be much better once search is part of the system.
That matters for code generation in particular, where the abstract explicitly calls out per-test-case correctness as a vector reward example. It also matters for multi-persona assistants, multi-objective ranking, and any setup where the “best” answer depends on which downstream criterion you use.
There is also an engineering implication for post-training stacks. If VPO really is a drop-in replacement for GRPO’s advantage estimator, then the barrier to trying it may be relatively low for teams already using RL-based post-training. The idea is not to replace inference-time search, but to make the model a better partner for it.
Limits and open questions
The source material is clear about the method’s direction, but thin on implementation detail. We do not get the exact training recipe, compute cost, dataset composition, or benchmark numbers in the abstract provided here.
We also do not see evidence from the abstract alone about how broadly the approach transfers beyond the four reported tasks, or how sensitive it is to the choice of vector reward formulation. Those are important questions because “diversity” can mean different things depending on the task.
Another open question is operational: if a team adopts VPO, how should they decide which reward dimensions to expose during training? The paper’s framing suggests that vector-valued rewards are common in practice, but the abstract does not spell out a general recipe for constructing them.
Even with those gaps, the central message is useful. As test-time search becomes more standard, the training objective may need to shift from maximizing one answer to producing a portfolio of answers. VPO is a concrete attempt to make that happen.
Bottom line
VPO is a reminder that better inference-time search starts with better training-time diversity. For developers building systems that sample, rank, and refine multiple candidates, that is a meaningful change in how to think about post-training.
- It reframes RL post-training around vector rewards instead of one scalar score.
- It is designed to work with search procedures that need diverse candidate solutions.
- It reports better search performance than scalar RL baselines across four tasks, with no benchmark numbers given in the abstract.
// Related Articles
- [RSCH]
CRDTs keep replicas in sync without locks
- [RSCH]
Post-Deterministic Systems for Autonomous Infra
- [RSCH]
Causal methods for measuring task learnability
- [RSCH]
RL Training That Hands Off Control Gradually
- [RSCH]
OmniGameArena benchmarks VLM game agents better
- [RSCH]
TurboQuant cuts KV cache memory 6x in Google tests