Tag
shared memory
Shared memory is a key CUDA performance lever on GPUs, shaping how warps exchange data, avoid bank conflicts, and overlap HBM latency with compute through features like cp.async and pipelined loading.
2 articles

Tools & Apps/Apr 3
NVIDIA Forum Debates a SU(7) CUDA Lattice Engine
A CUDA forum thread on Anchor4 SU(7) mixes lattice theory, shared memory tuning, and warp-level tricks for GPU synchronization.
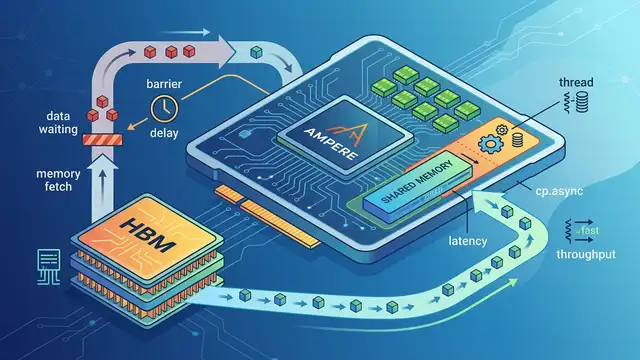
Research/Apr 3
cp.async on Ampere: Hide HBM Latency on A100
Ampere’s cp.async moves data without stalling warps, cutting HBM waits from 450–600 cycles into overlapped compute on A100.