精確後驗分數解線性反問題
EPS 把線性反問題的後驗分數寫成閉式,讓既有去噪器訓練與採樣流程幾乎不用改。

EPS 把線性反問題的後驗分數寫成閉式,讓既有去噪器訓練與採樣流程幾乎不用改。
- 研究機構:arXiv 摘要未明確標註
- 核心數據:去噪器評估次數約少一個數量級
- 突破點:閉式後驗分數
Exact Posterior Score Estimation for Solving Linear Inverse Problems 這篇在處理一個很常見的落差:擴散模型和 flow-based 模型很會學資料先驗,但線性反問題要的是「看起來合理」之外,還要對量測值一致的後驗樣本。這篇摘要主張,對線性高斯反問題,可以把後驗分數精確寫出來,而且訓練時仍可沿用標準去噪目標,不必把整套 denoiser 結構打掉重練。
這件事的價值很直接。很多實務系統不是維持一個預訓練去噪器,再外掛近似的量測修正,就是乾脆訓練另一個條件式模型。但前者常常要多一層近似修正,後者又可能失去原本去噪器的優勢。EPS 想做的是,把後驗條件直接塞回去噪框架裡,讓「學先驗」和「符合量測」不再互相拉扯。
它想解的痛點是什麼
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
擴散模型和 flow-based 模型的核心能力,是把高斯雜訊一步步反推回資料分布。白話說,它們知道怎麼把亂掉的訊號修回一個合理樣本。但線性反問題不是只要合理樣本。你還要這個樣本跟觀測資料對得上。
摘要指出,現有方法通常卡在兩邊。第一種做法是固定一個預訓練去噪器,再用近似的量測匹配修正去推結果。第二種做法是直接訓練條件式修復模型,但這樣可能就不再保留原本去噪預訓練的結構。EPS 的定位,就是想避開這個取捨。
對開發者來說,這個問題很實際。如果你的 sampler 每一步都得額外做量測修正,流程會變複雜,算力也會上去。如果你整個重訓成條件模型,又不一定能重用既有 diffusion backbone。這篇就是在處理這個「想要後驗,但不想把系統改爛」的工程痛點。
方法到底怎麼運作
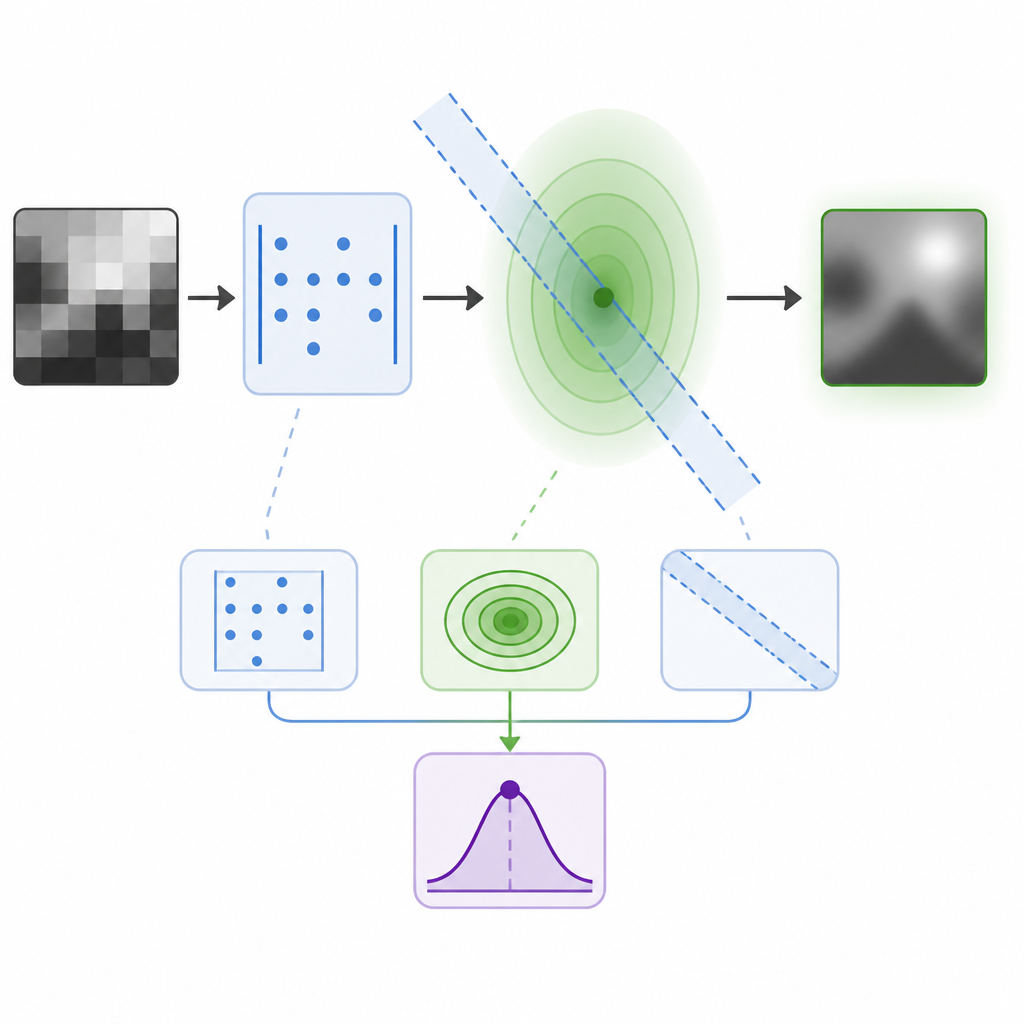
這篇的核心,是把線性高斯反問題下的「精確後驗分數」推成閉式,而且是建立在一般 Gaussian interpolants 的設定上。摘要沒有把完整推導展開,但它給了一個很重要的解讀:後驗採樣可以被改寫成一個去噪問題,只是這個去噪是在一個和算子有關的 shifted pivot 上進行,雜訊協方差則是 anisotropic 的,也就是不是每個方向都一樣。
這句話看起來很硬,但工程上的意思其實很清楚。EPS 不是把條件資訊當成外掛修正,而是把後驗本身重新寫成仍然像去噪的形式。那個 pivot 會跟 measurement operator 有關,表示量測矩陣怎麼作用,會直接進到 score 的表達式裡。
有了這個等式之後,作者把它做成 Exact Posterior Score,簡稱 EPS,當成一個去噪訓練目標。這裡最重要的設計,是它保留了標準預訓練的輸入輸出結構。也就是說,你可以從頭訓練,也可以拿既有 denoiser 做 fine-tune,而不需要把 backbone 換成另一套完全不同的條件式架構。
推論階段也很關鍵。摘要明確提到,EPS 直接使用底層 backbone 的 sampler,不需要 likelihood gradients 或 projections。這代表後驗修正不是在 runtime 再多跑一個迴圈,而是被吸收到訓練裡。對部署來說,這通常比外掛修正更乾淨。
論文實際證明了什麼
摘要提到,作者在五個線性反問題上做了評估,資料集涵蓋 FFHQ 和 ImageNet。結果上,EPS 在 fidelity、perceptual 和 distributional metrics 上都優於 training-free 與 training-based baseline。不過摘要沒有公開完整 benchmark 數字,所以這裡不能硬補具體分數。
真正有數字的地方,是效率。摘要說 EPS 相較於 gradient-based posterior samplers,大約少了一個數量級的 denoiser evaluations。這一點很值得注意,因為在 diffusion 類管線裡,denoiser evaluation 往往就是推論成本的大頭。少一個數量級,通常不是小修小補,而是會直接影響能不能上線。
摘要也說,這個方法同時支援從頭訓練和 fine-tuning。這讓它比只適合事後修正的做法更彈性,也比只能全新訓練的條件模型更容易接進既有系統。只是摘要沒有說用了哪些 backbone 架構,所以不能把它解讀成某一種特定模型的結果。
- 評估了 5 個線性反問題
- 資料涵蓋 FFHQ 與 ImageNet
- 比較了 training-free 與 training-based baseline
對開發者有什麼影響
如果你在做 restoration、reconstruction,或是任何帶 measurement conditioning 的生成系統,這篇會有吸引力,因為它想把 posterior sampling 變回「像普通去噪一樣」的事。這通常意味著訓練流程更單純,也比較容易重用既有 diffusion backbone,而不是每次都重新設計條件模組。
算力面向也很實際。去噪器評估次數少一個數量級,對 latency-sensitive 的管線來說很可能是決定性的差異。摘要沒有提供 wall-clock、記憶體占用,或部署環境下的實測數據,所以還不能直接推論成實際服務成本下降多少。
但這篇也有明確邊界。EPS 的推導是針對線性高斯反問題,而且建立在 general Gaussian interpolants 之上。這是一個有用的類別,但仍然只是某一類問題。摘要沒有宣稱它同樣適用於非線性反問題、非高斯觀測模型,或任意 measurement operator。
所以比較務實的讀法是:如果你的問題結構剛好符合這些假設,EPS 可能是一條更乾淨的後驗生成路線;如果你的任務更複雜,就不能直接把它當成萬用解法。
還有哪些資訊沒說清楚
摘要沒有交代幾個對實作很重要的細節。像是五個反問題各自是什麼、用了哪些 denoiser 架構、sampler 的超參數怎麼設、以及絕對指標是多少,摘要都沒有寫。它也沒有提供 ablation,說明到底是哪一段設計帶來主要增益。
這代表目前最穩妥的結論只能收斂到一件事:EPS 提供了線性反問題下的精確後驗分數形式,而且在作者測試的基準上,看起來同時改善了品質和效率。
對已經在做 diffusion-based reconstruction 的團隊來說,這篇值得細看,因為它不是再疊一層 inference-time 技巧,而是直接從 score 層級重寫條件問題。若推導和實作都成立,這種改法通常比外掛修補更有機會把整條 pipeline 簡化下來。