AdaCodec cuts video tokens with predictive visual codes
AdaCodec compresses video for MLLMs by encoding only unpredictable frames and inter-frame changes.
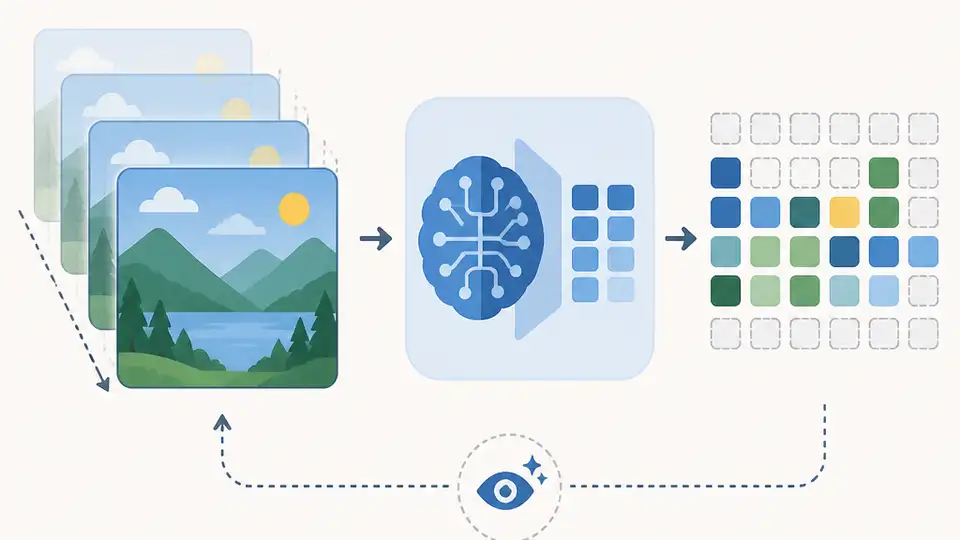
AdaCodec compresses video for MLLMs by encoding only unpredictable frames and inter-frame changes.
- Research org: Unspecified in arXiv abstract
- Core data: 32k tokens vs 224k baseline
- Breakthrough: Predictive visual code with reference frames and compact P-tokens
Video models are still wasting a lot of bandwidth on redundancy. If adjacent frames mostly repeat the same objects, background, and layout, then encoding every sampled frame as if it were a brand-new RGB image is expensive and often unnecessary.
AdaCodec: A Predictive Visual Code for Video MLLMs takes that observation seriously and turns it into a new video interface for multimodal large language models. Instead of always sending full visual tokens, the model sends a reference frame only when the scene is hard to predict from prior context, and otherwise sends a compact description of what changed.
What problem this paper is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The paper is aimed at a very practical inefficiency in video MLLMs: repeated visual tokens. In current systems, each sampled frame is usually encoded independently as an RGB image, even when most of the visual content is already present in earlier frames. That means the model keeps paying for the same information over and over.
This matters because video is naturally temporally redundant. Most clips do not change completely from frame to frame. For developers building video understanding systems, that redundancy translates into higher token budgets, slower inference, and less room for longer context.
The abstract frames the issue as a mismatch between how video actually behaves and how video MLLMs consume it. The paper argues for a more direct interface: transmit a full frame only when the model cannot predict the scene well from prior context, and otherwise transmit a compact representation of the inter-frame changes.
How AdaCodec works in plain English
AdaCodec is the paper’s name for this predictive interface. The core idea is simple: use a full reference frame when necessary, and use compact change tokens when not.
The paper says AdaCodec spends full visual tokens on a reference frame only when its conditional predictive cost is high. When the scene is predictable, it encodes inter-frame changes instead. Those changes include motion and prediction residuals, which are packaged as compact P-tokens.
In other words, AdaCodec is not trying to represent every frame from scratch. It tries to represent what the next frame adds. That is the key shift: from “encode the image” to “encode the difference from what we already know.”
For engineers, that distinction is important. A system that can preserve useful video information while spending fewer tokens on redundant content can potentially fit more video into the same budget, or reduce latency for the same amount of input.
What the paper actually shows
The abstract reports results across eleven benchmarks. It says AdaCodec improves over the Qwen3-VL-8B per-frame RGB baseline at a matched visual-token budget. That is the main comparison point in the paper as presented here.
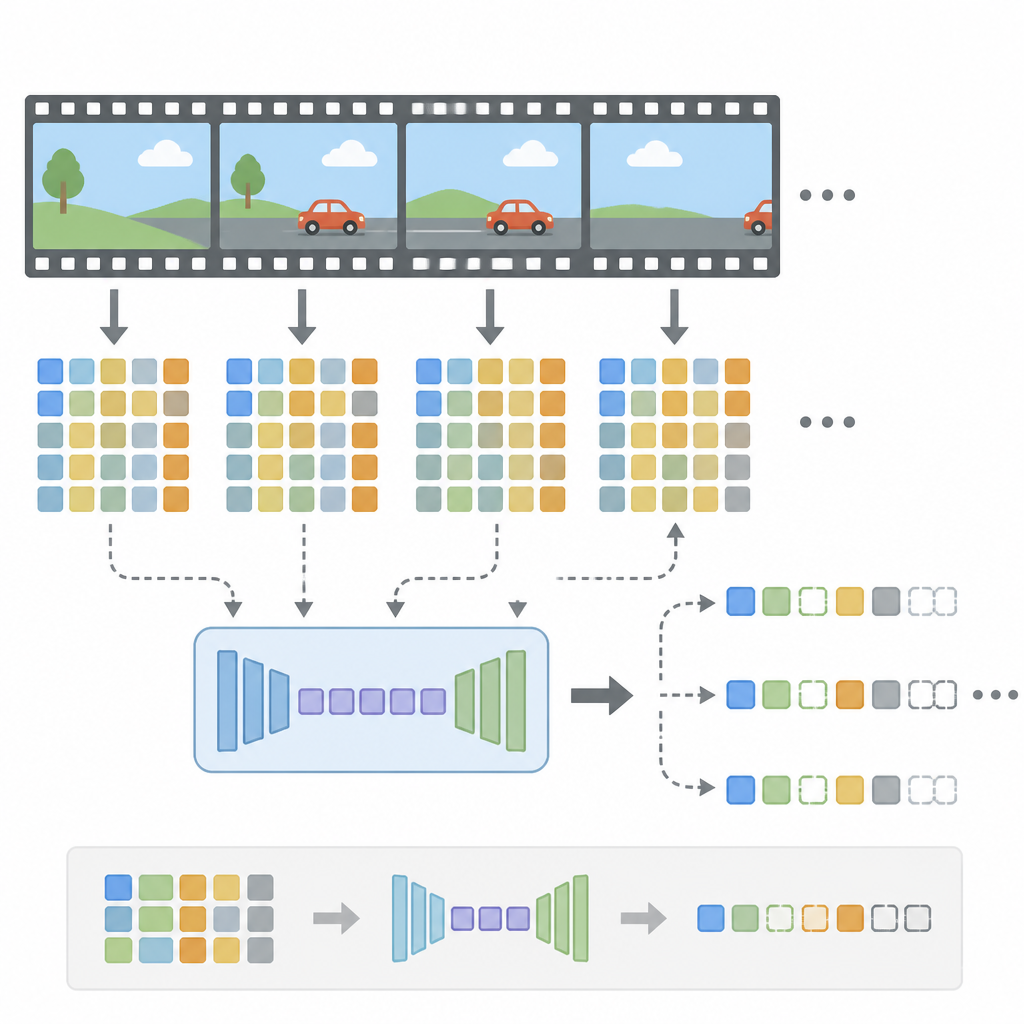
The most concrete efficiency number in the abstract is the token budget reduction: even at one-seventh the budget, AdaCodec with 32k tokens surpasses the 224k baseline on all long-video benchmarks. That is a strong claim about how much redundancy the method can remove while still preserving performance.
On five general-video benchmarks, the paper says AdaCodec raises the average score while also reducing time-to-first-token from 9.26 seconds to 1.62 seconds. That latency drop is likely to matter as much as the accuracy gains for interactive systems, where users feel startup delay immediately.
One thing the abstract does not provide is the full benchmark table, so it does not tell us the exact score deltas on each of the eleven tasks. It also does not specify the details of the benchmark suite beyond distinguishing long-video and general-video evaluations. So the safest reading is that AdaCodec appears to improve both efficiency and quality, but the exact margins depend on the benchmark.
Why developers should care
If you are building a video assistant, a surveillance analyzer, a meeting summarizer, or any other video MLLM product, token efficiency is not a cosmetic detail. It affects how much video you can process, how quickly the model starts responding, and how expensive each request becomes.
AdaCodec points toward a design that could be more practical than “treat every frame like a fresh image.” By using predictive coding, it tries to align the video input pipeline with the actual structure of video data: mostly stable, with localized changes.
That also suggests a broader engineering lesson. For sequence models, a better representation is often not a bigger model, but a smarter interface to the data. AdaCodec is essentially an input-side optimization for video MLLMs, and the abstract claims that this alone can deliver both better scores and lower latency.
What’s still unclear
The abstract is promising, but it leaves open several questions that matter in practice. It does not explain how the predictive cost is computed in detail, how P-tokens are formed internally, or how sensitive the method is to different kinds of motion and scene cuts.
It also does not tell us whether AdaCodec requires special training data, whether it generalizes across model families, or how it behaves on videos with rapid scene changes, camera shake, or heavy occlusion. Those are exactly the cases where predictive compression can become harder.
So the right takeaway is not that video MLLMs are solved. It is that the paper offers a concrete, token-efficient alternative to per-frame RGB encoding, and the reported results suggest that a predictive visual code can be a better fit for redundant video than the status quo.
The bottom line
AdaCodec reframes video understanding as a prediction problem: send full visual context only when needed, and otherwise send compact change information. According to the abstract, that approach improves performance at matched budgets, cuts token use sharply, and reduces time-to-first-token in at least some settings.
For developers, the appeal is straightforward. If the results hold up beyond the reported benchmarks, predictive visual coding could make video MLLMs cheaper, faster, and more scalable without forcing a tradeoff between efficiency and quality.
- It targets redundancy in per-frame RGB video encoding.
- It uses reference frames plus compact P-tokens for changes.
- It reports better results at lower token budgets and lower latency.
// Related Articles
- [RSCH]
CRDTs keep replicas in sync without locks
- [RSCH]
Post-Deterministic Systems for Autonomous Infra
- [RSCH]
Causal methods for measuring task learnability
- [RSCH]
RL Training That Hands Off Control Gradually
- [RSCH]
OmniGameArena benchmarks VLM game agents better
- [RSCH]
TurboQuant cuts KV cache memory 6x in Google tests