BAS scores LLM confidence for abstain decisions
BAS evaluates whether LLM confidence helps decide when to answer or abstain, exposing overconfident errors that standard metrics can miss.

Large language models can sound certain even when they are wrong, and that becomes a real problem when the safer choice is to abstain. The paper BAS: A Decision-Theoretic Approach to Evaluating Large Language Model Confidence argues that standard confidence metrics miss an important part of the story: not just whether a model is calibrated, but whether its confidence actually supports better decisions under different risk preferences.
The authors propose Behavioral Alignment Score, or BAS, a metric built around an explicit answer-or-abstain utility model. In plain terms, BAS asks: if a model can either answer or refuse, and if the cost of being wrong changes with the situation, how useful is its confidence signal for making the right call?
What problem this paper is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
Most evaluation setups for LLMs still assume the model must answer. That works for many benchmark tasks, but it breaks down in real systems where abstention is an option and sometimes the best option. If a model is unsure, a well-designed assistant should be able to hold back rather than confidently deliver a harmful mistake.

The issue is that common metrics do not fully capture that decision-making layer. A model can look acceptable on calibration-style scores and still be dangerously overconfident in the cases that matter most. The paper’s core complaint is that existing protocols do not directly measure how confidence should guide abstention under different risk thresholds.
That matters for developers building systems with escalation, refusal, or human-in-the-loop review. If your confidence signal is only loosely connected to the actual decision of whether to answer, then the metric you optimize may not match the behavior you want in production.
How BAS works in plain English
BAS is derived from a decision-theoretic utility model with two actions: answer or abstain. Rather than treating confidence as a standalone number to be judged in isolation, the metric evaluates the realized utility of decisions across a continuum of risk thresholds. That makes it sensitive to both the size of the confidence estimate and its ordering across examples.
The idea is simple enough: a confidence score is only useful if it helps separate cases where the model should speak from cases where it should stay quiet. BAS aggregates the utility of those choices, so a model is rewarded for confidence that leads to better abstention-aware behavior, not just for being numerically close on average.
The paper also makes a theoretical claim: truthful confidence estimates uniquely maximize expected BAS utility. In other words, if a model’s confidence is honest, that is the best strategy under this framework. The authors connect this to calibration, but BAS is not just another calibration score. It is designed to reflect decision-optimal behavior in a setting where overconfident errors are especially costly.
Compared with proper scoring rules such as log loss, BAS behaves differently in an important way. Log loss penalizes underconfidence and overconfidence symmetrically, while BAS applies an asymmetric penalty that strongly prioritizes avoiding overconfident mistakes. That distinction is central to why the metric may be more relevant for abstention-heavy deployments.
What the paper actually shows
The authors use BAS alongside widely used metrics such as ECE and AURC to build a benchmark of self-reported confidence reliability across multiple LLMs and tasks. The abstract does not provide the full benchmark table or concrete numeric scores, so the headline here is qualitative rather than numeric: the benchmark shows substantial variation in decision-useful confidence across models and tasks.
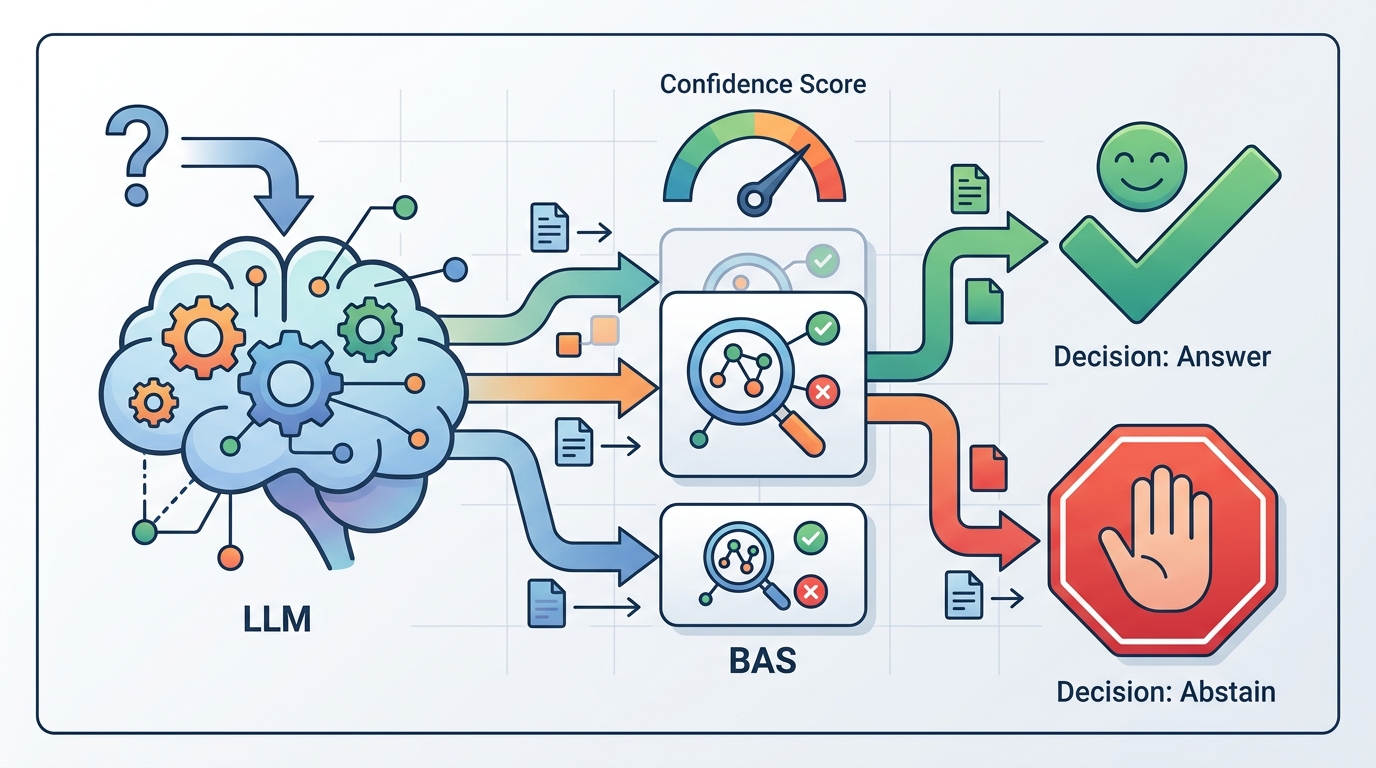
One of the paper’s main findings is that larger and more accurate models tend to achieve higher BAS. That is encouraging, but it is not the end of the story. Even frontier models still show severe overconfidence, which means a strong base model can still be a weak decision-maker if its confidence is not trustworthy.
Another important result is that models with similar ECE or AURC can have very different BAS values. That is a practical warning sign for anyone relying on standard metrics alone: two systems that look comparable on calibration or ranking-based measures may behave very differently when the actual goal is deciding whether to answer or abstain.
The paper also reports that simple interventions can improve confidence reliability. Specifically, top-k confidence elicitation and post-hoc calibration can meaningfully boost BAS. The abstract does not spell out which tasks benefit most or how large the gains are, so the safe takeaway is that relatively lightweight changes to how confidence is elicited or adjusted can matter.
Why developers should care
If you are building an LLM product that needs safe refusal, escalation, or selective answering, BAS is closer to the real operational question than a generic confidence metric. It evaluates whether confidence helps the system make the right decision under risk, not just whether the score looks well-behaved in aggregate.
That makes BAS useful in a few concrete ways:
- It can help compare models when abstention is part of the product design.
- It can expose overconfident failures that ECE or AURC may hide.
- It gives teams a way to think about confidence as a decision signal, not just a number attached to an answer.
- It suggests that calibration and confidence elicitation should be tested in the context of downstream utility, not in isolation.
For implementation-minded teams, the paper’s framing also encourages a more realistic evaluation stack. Instead of asking only “is the model calibrated?”, you can ask “does this confidence score actually improve answer-versus-abstain decisions for the risk profile we care about?” That is a more production-relevant question for customer support, medical triage, code assistance, compliance workflows, and any other setting where a wrong answer can be worse than no answer.
Limits and open questions
The abstract makes the strengths of BAS clear, but it also leaves several practical questions open. We do not get the full benchmark breakdown, the exact task list, or the detailed experimental setup in the source notes here, so it is hard to judge how broadly the results generalize across domains.
There is also a broader product question: how should a team choose the risk thresholds that BAS integrates over? The paper says the metric spans a continuum of risk thresholds, which is useful, but real applications often have domain-specific costs that are not easy to summarize in one curve. That means BAS may be best viewed as a principled evaluation tool rather than a complete deployment policy.
Still, the contribution is clear. BAS pushes confidence evaluation toward the thing practitioners actually care about: whether the model knows when not to answer. For developers building abstention-aware systems, that is a much more actionable target than confidence calibration alone.
// Related Articles
- [RSCH]
How VLMs Learned Complex Scene Descriptions
- [RSCH]
Visual Pretraining Beats Text-Only in Language Models
- [RSCH]
PHINN-EEG brings topology to dream-state EEG
- [RSCH]
Google’s Android Bench update exposes Gemini’s gap
- [RSCH]
Benchmarks should not pick your LLM in 2026
- [RSCH]
Rust Breaks Into TIOBE’s Top 10