HRGrad tackles gradient conflict in multiscale physics
HRGrad aims to reduce gradient conflict in multiscale kinetic problems, helping APNNs train across microscopic-to-macroscopic regimes.

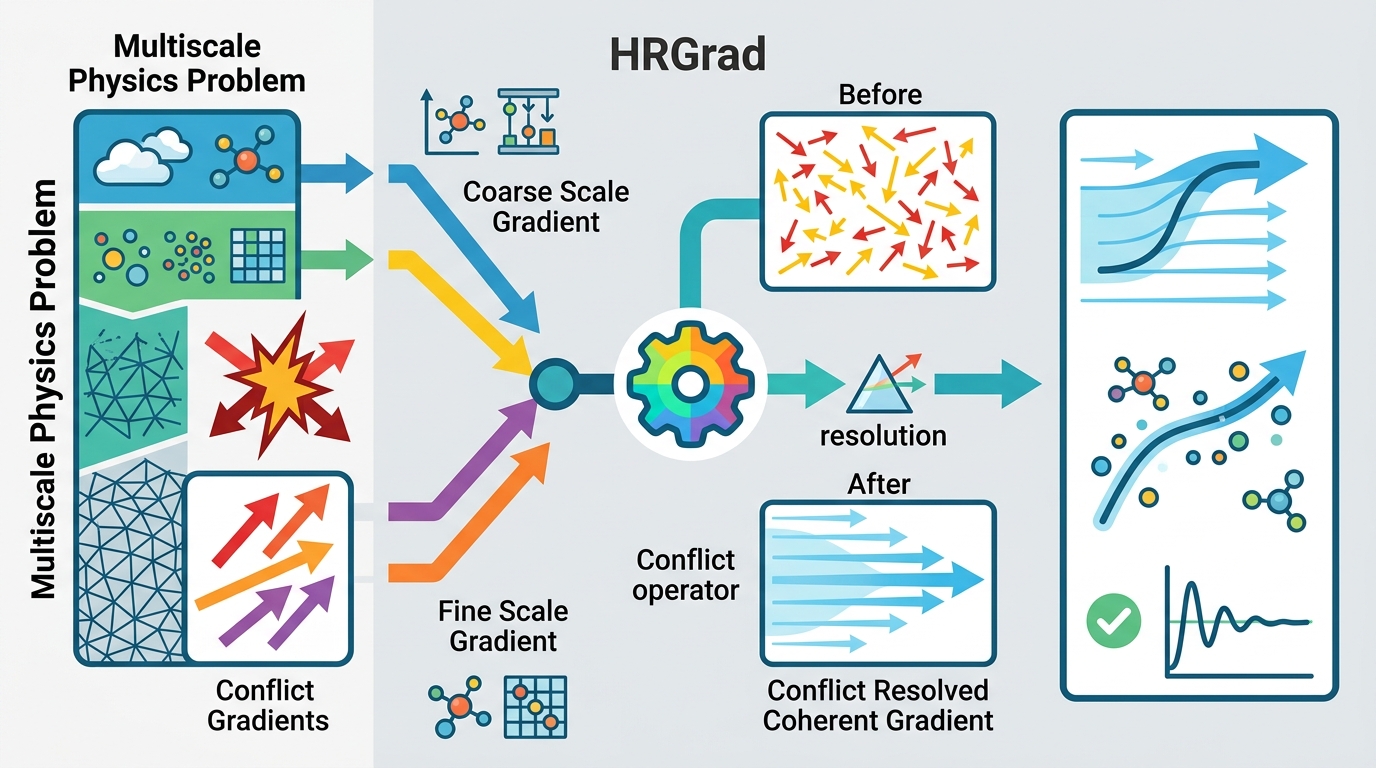
Multiscale kinetic problems are hard because the same model has to behave well across very different regimes, from microscopic physics to macroscopic physics. This paper proposes Conflict-Aware Harmonized Rotational Gradient for Multiscale Kinetic Regimes, or HRGrad, as a way to make that training process more stable for asymptotic-preserving neural networks.
The core idea is practical: if tasks from different asymptotic regions fight each other during optimization, the model can fail. HRGrad tries to serialize those tasks through a hidden representation of the small parameters, then uses a gradient alignment rule to keep updates from pointing against each task-specific loss.
What problem this paper is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The paper is focused on multiscale time-dependent kinetic problems with varying small parameters. These parameters create asymptotic transitions between microscopic and macroscopic physics, which means one model is being asked to solve several related but not identical tasks at once.

That matters because this is not just a standard supervised learning setup. In multi-task learning, gradients from different tasks can conflict. When that happens, one task’s update can hurt another task’s progress, and training can become unstable or fail outright. The authors describe this as one of the failure modes of APNNs in these problems.
For developers working on scientific ML, the important takeaway is simple: if your model has to cover multiple regimes, you need an optimization strategy that respects those regime differences. Otherwise, “one model for all ranges” can turn into “one model that breaks in the hard ranges.”
How HRGrad works in plain English
HRGrad combines two ideas. First, it explicitly encodes a hidden representation of the small parameters. The goal is to ensure that solving tasks from different asymptotic regions are serialized for simultaneous training, rather than all being mixed together in a way that makes optimization noisy.
Second, it tries to manage gradient conflict directly. The paper says it segments the prediction results to build task losses, then introduces a new gradient alignment metric. That metric is designed to make sure the final update has a positive dot product with each loss-specific gradient.
In plain terms, HRGrad is trying to keep the optimizer from stepping in a direction that helps one task while actively hurting another. It also dynamically adjusts gradient magnitudes based on how much conflict is present, so the method is not just checking for agreement, but also changing the strength of each update when gradients disagree.
This is the kind of mechanism that matters in physics-informed or asymptotic-preserving setups, where regime coverage is the whole point. If a model only works in one region, it is not really solving the multiscale problem.
What the paper actually shows
The abstract says the authors provide a mathematical proof of convergence for HRGrad. That is important, because optimization methods for scientific ML often need some theoretical footing before people trust them in hard settings.
The paper evaluates HRGrad across challenging asymptotic-preserving neural network scenarios. The experiments include the Bhatnagar-Gross-Krook, or BGK, equation and the linear transport equation, tested across all ranges of Knudsen number.
What the abstract does not give is benchmark numbers. There are no accuracy tables, runtime figures, error percentages, or ablation results in the source material provided here, so those details should not be assumed. What we can say is that the authors claim HRGrad effectively overcomes the failure modes of APNNs on these problems.
That makes the contribution more about robustness across regimes than about a single headline metric. For this kind of work, that is often the real challenge anyway: not getting a strong score in one setting, but avoiding collapse when the regime changes.
Why engineers should care
If you build models for PDEs, kinetic equations, or other multiscale scientific systems, this paper points at a recurring pain point: gradient conflict across tasks that are supposed to coexist in one model. HRGrad is an attempt to make that training process more disciplined.
The approach is especially relevant when the model has to cover a wide parameter range. In those cases, a naive joint-loss setup may look fine during early training and then fall apart when one regime dominates the gradients. A method that explicitly measures and manages alignment gives you a more controlled optimization loop.
There is also a broader lesson here for multi-task scientific ML. The paper treats parameter-regime structure as something to encode, not something to hope the network discovers on its own. That is a useful design pattern when the physics already tells you the problem is segmented.
Limits, open questions, and implementation context
The abstract is promising, but it leaves some practical questions unanswered. We do not get implementation details, training cost, architectural specifics, or comparative benchmark numbers in the provided text. We also do not know how sensitive HRGrad is to the choice of segmentation strategy, or how it behaves when the hidden parameter representation is imperfect.
Another open question is how broadly the method transfers beyond the tested APNN scenarios. The paper reports experiments on BGK and linear transport equations across Knudsen number ranges, but the abstract does not claim results on other PDE families or non-kinetic domains.
Still, the design is clear enough to be useful as a concept. HRGrad suggests a workflow for multiscale learning that many engineers can recognize:
- separate regime information instead of flattening it away;
- build task losses that reflect the structure of the prediction output;
- monitor gradient conflict directly;
- adjust updates so no task is systematically pushed backward.
That combination is especially relevant for anyone trying to make a single model behave consistently across asymptotic regimes. The paper’s main value is not a new benchmark number in the abstract, but a concrete optimization strategy for a class of problems where training instability is often the real blocker.
In short, HRGrad is an optimization-aware answer to a physics-aware learning problem. If APNNs are going to be useful across microscopic and macroscopic regimes, methods like this are the kind of plumbing that makes that possible.
// Related Articles
- [RSCH]
TurboQuant and the SEO Shift for Small Sites
- [RSCH]
TurboQuant vs FP8: vLLM’s first broad test
- [RSCH]
LLMbda calculus gives agents safety rules
- [RSCH]
A simpler beamspace denoiser for mmWave MIMO
- [RSCH]
Why AI benchmark wins in cyber should scare defenders
- [RSCH]
Why Linux security needs a patch-wave mindset