LocateAnything speeds up vision-language grounding
LocateAnything uses parallel box decoding to make visual grounding faster while improving high-IoU localization quality.

LocateAnything uses parallel box decoding to make visual grounding faster while improving high-IoU localization quality.
- Research org: Unspecified in arXiv abstract
- Core data: More than 138 million training samples
- Breakthrough: Decodes boxes and points as atomic units in one step
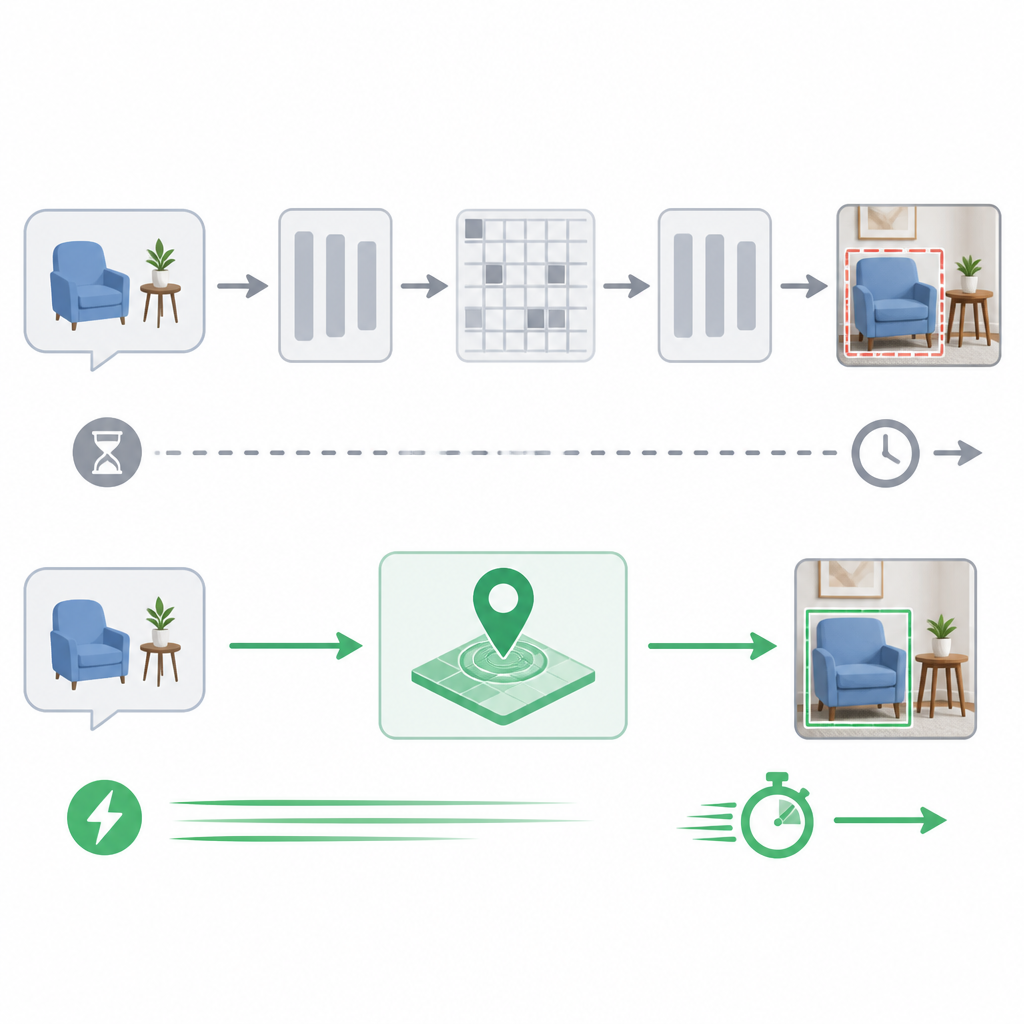
LocateAnything: Fast and High-Quality Vision-Language Grounding with Parallel Box Decoding tackles a familiar bottleneck in vision-language systems: they often turn grounding and detection into a sequence of coordinate tokens, then decode those tokens one after another. That approach is simple, but it can be a poor fit for box geometry and it slows inference because the model has to generate each piece in order.
The practical takeaway is straightforward. If your application needs a model to point to objects, regions, or points in an image, sequential coordinate generation can become the part that limits both speed and quality. This paper argues that the decoding format itself is part of the problem, not just the model size or the training data.
What problem this paper is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
In the abstract, the authors describe a mismatch between how boxes are represented and how they are decoded. A 2D box is a coupled geometric object, but many VLMs serialize it into multiple 1D tokens and learn those tokens largely independently. That creates two issues at once: the geometry can become less coherent inside the box, and the inference path stays strictly sequential.
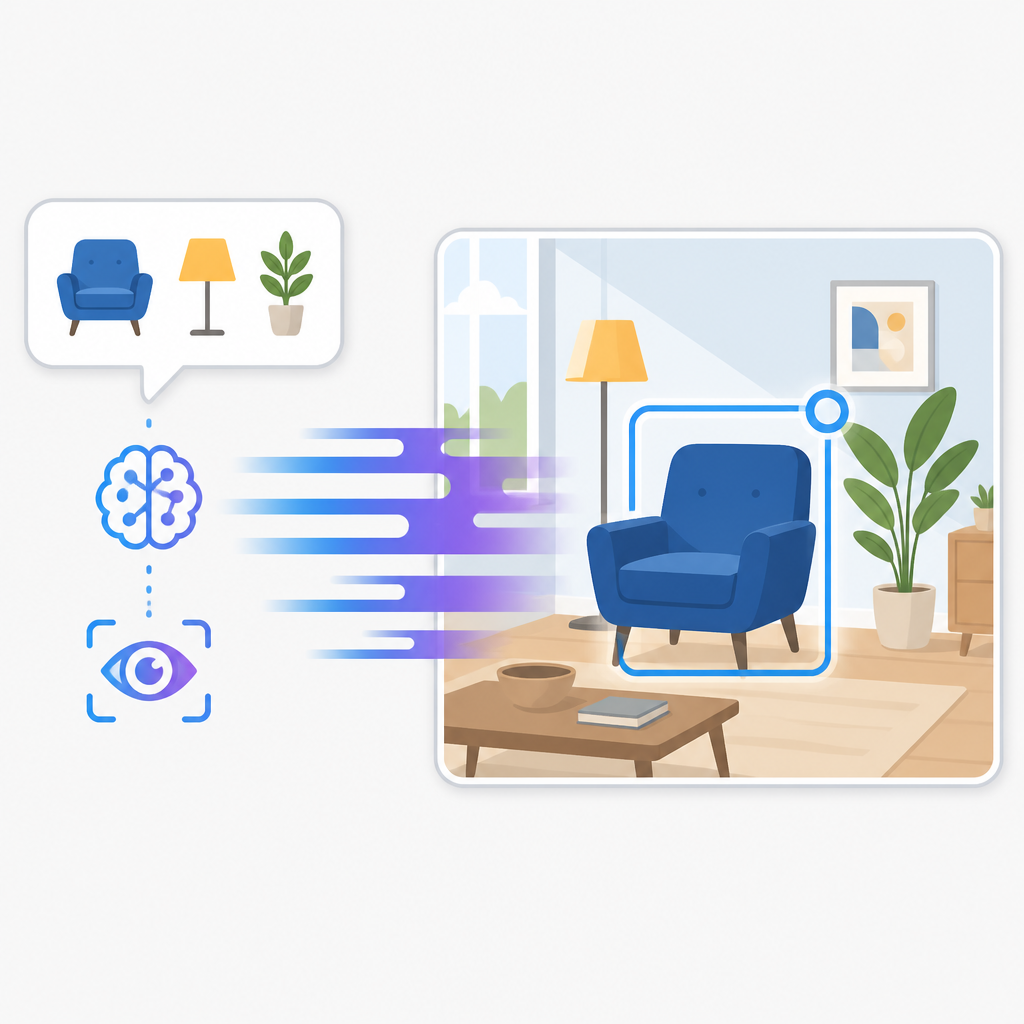
For developers, that matters because grounding is not just about getting a label right. In many systems, the output has to be spatially precise enough to drive downstream actions: cropping, UI automation, robotics, annotation tools, or any interface where “roughly here” is not good enough. A method that improves both speed and localization quality is therefore more than an academic tweak.
How the method works in plain English
LocateAnything introduces a unified generative grounding and detection framework built around Parallel Box Decoding, or PBD. Instead of emitting a box as a chain of coordinate tokens, the system decodes geometric elements such as bounding boxes and points as atomic units in a single step.
That design choice is doing two things at once. First, it preserves intra-box geometric coherence, because the model is treating the box as a complete object rather than as a string of loosely related tokens. Second, it unlocks parallelism, because the model is no longer forced to generate every coordinate sequentially.
The abstract frames this as a decoding-level change rather than a new task definition. In other words, LocateAnything is trying to make the same grounding and detection workload more efficient and more faithful to geometry by changing how the output is produced.
What the paper actually shows
The authors say PBD improves both decoding throughput and localization accuracy. They also say the approach advances the speed-accuracy frontier, with significantly higher decoding throughput and better high-IoU localization quality across diverse benchmarks.
There is an important limitation in the source material: the abstract does not include benchmark names, exact scores, throughput numbers, or comparison tables. So while the direction of improvement is clear, the magnitude is not visible from the abstract alone.
The data side is also part of the story. The team developed a scalable data engine and curated LocateAnything-Data, a large-scale dataset with more than 138 million training samples. The abstract says this dataset adds diversity for high-precision localization, which suggests that the authors see training scale and data variety as complementary to the decoding change.
That combination is worth noting. The paper is not claiming that parallel decoding alone solves grounding. Instead, it presents PBD plus large-scale data as a pair of levers that together improve efficiency and precision.
- Sequential coordinate generation is replaced with atomic decoding of boxes and points.
- LocateAnything-Data contains more than 138 million training samples.
- The abstract claims better throughput and high-IoU localization, but no exact numbers are given.
Why developers should care
If you are building a vision-language system, the output format can matter as much as the model architecture. A sequential coordinate-token scheme may be easy to implement, but it can also become a latency bottleneck and introduce avoidable geometric inconsistency. PBD is a reminder that some of the biggest wins may come from rethinking the decoding path.
This is especially relevant for production systems where grounding has to happen repeatedly and quickly. Faster decoding can reduce end-to-end latency, and better high-IoU localization can make outputs more reliable for downstream automation. Even without the exact benchmark numbers, the paper points at a useful engineering principle: treat structured spatial outputs as structured objects, not just token streams.
There are still open questions. The abstract does not tell us how PBD behaves on small objects, crowded scenes, or edge cases where coordinate precision is especially fragile. It also does not say how much of the gain comes from the decoding method versus the 138M-sample dataset. Those details would matter if you were deciding whether to adapt the approach to your own stack.
Still, the paper’s core message is clear. Vision-language grounding does not have to be slow just because it is precise, and it does not have to sacrifice geometric coherence just to stay generative. LocateAnything is making the case that the decoding strategy itself is a first-class optimization target.
Bottom line
LocateAnything proposes a practical alternative to token-by-token box generation: decode spatial outputs in parallel, keep box geometry coherent, and back it with a much larger training set. The abstract claims that this improves both speed and localization quality, but the exact benchmark gains are not provided in the source.
For engineers, that makes the paper interesting even before you get to the full tables. It points to a concrete way to reduce latency in grounding-heavy systems without giving up precision, which is exactly the kind of tradeoff that matters in real deployments.
// Related Articles
- [RSCH]
CRDTs keep replicas in sync without locks
- [RSCH]
Post-Deterministic Systems for Autonomous Infra
- [RSCH]
Causal methods for measuring task learnability
- [RSCH]
RL Training That Hands Off Control Gradually
- [RSCH]
OmniGameArena benchmarks VLM game agents better
- [RSCH]
TurboQuant cuts KV cache memory 6x in Google tests