Persistent Visual Memory fixes LVLM visual drift
PVM is a lightweight LVLM module that keeps visual information available during long generations, reducing visual signal decay.

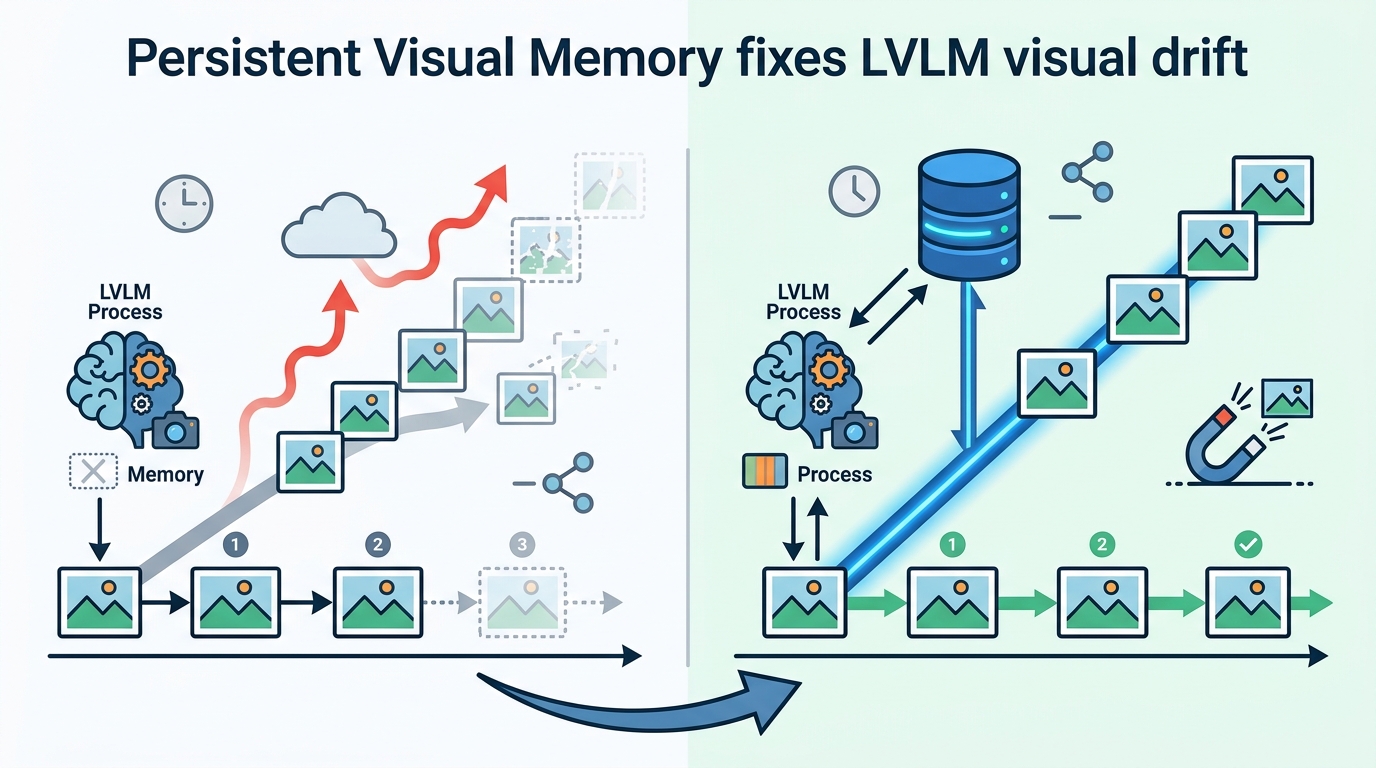
Persistent Visual Memory helps LVLMs keep seeing clearly during long generations.
Autoregressive large vision-language models are good at multimodal tasks, but this paper argues they run into a practical failure mode: as text grows, visual attention weakens. Persistent Visual Memory (PVM) is the authors’ answer, a lightweight module meant to preserve visual perception when generation gets deep.
For engineers, the interesting part is not just that LVLMs can answer questions about images, but that they can lose access to the image as the output sequence gets longer. That matters in any workflow where the model must reason over visuals while also producing a lot of text, such as step-by-step explanation, multi-turn dialogue, or complex reasoning.
What problem this paper is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The paper names the issue “Visual Signal Dilution.” In plain English, the more tokens the model generates, the more the text history expands the attention partition function, and the less the model attends to visual information. The result is an inverse relationship between generated sequence length and visual attention.

That is a structural problem, not just a tuning issue. If the model’s internal machinery increasingly prioritizes accumulated text over the image, then long-form generation can become less grounded in what the model originally saw. The paper frames this as a challenge for deep generation in LVLMs, where sustained perception is needed throughout the full output, not just at the first few tokens.
This is the kind of failure mode developers care about because it can show up quietly. A model may look strong on short answers, then drift when asked to reason longer, compare more details, or maintain visual context across a long response.
How Persistent Visual Memory works
PVM is described as a lightweight learnable module integrated as a parallel branch alongside the Feed-Forward Network, or FFN, in LVLMs. The key design idea is to create a distance-agnostic retrieval pathway that can directly provide visual embeddings when needed.
In practical terms, that means PVM is not trying to rely solely on the standard attention path, which the paper says becomes less reliable as generation length grows. Instead, it offers a separate route for pulling in visual information on demand, so the model can keep accessing image features even when the text context gets long.
The paper’s framing is architectural rather than purely training-based. It aims to structurally mitigate signal suppression inherent to deep generation. That makes it interesting for model builders because it suggests the fix is not only about prompting or data, but about how the network routes information internally.
Because the module is described as lightweight, the authors position it as a practical add-on rather than a heavy redesign. The abstract does not provide implementation details beyond the parallel-branch design, so the exact internal mechanics would need the full paper for a deeper engineering read.
What the paper actually shows
The experiments are run on Qwen3-VL models at 4B and 8B scale. The abstract says PVM brings notable improvements with negligible parameter overhead and delivers consistent average accuracy gains across both scales.
Importantly, the abstract does not give benchmark names, exact scores, or absolute deltas. So while the direction of the result is clear, the source material does not let us quantify the lift beyond “notable” and “consistent average accuracy gains.”
The strongest claim in the notes is that PVM helps especially on complex reasoning tasks that require persistent visual perception. That aligns with the core hypothesis: the longer and more demanding the generation, the more useful a mechanism becomes that keeps visual information alive.
The paper also reports in-depth analysis showing two additional effects: PVM can resist length-induced signal decay and accelerate internal prediction convergence. Those are useful signals for researchers and implementers, because they suggest the module may help both stability and optimization dynamics, not just end-task accuracy.
- Model family tested: Qwen3-VL
- Scales mentioned: 4B and 8B
- Reported effect: negligible parameter overhead
- Reported outcome: consistent average accuracy gains
- Extra analysis: resistance to length-induced signal decay and faster internal prediction convergence
Why developers should care
If you build with LVLMs, this paper points to a real deployment concern: long outputs can degrade visual grounding. That matters for assistants that explain images, agents that narrate visual steps, or systems that need to keep referring back to the same scene while producing extended reasoning.
PVM’s appeal is that it tries to solve that problem at the architecture level without a large parameter cost, at least according to the abstract. If the gains hold up, that could make it a useful pattern for improving robustness in long-generation multimodal systems.
There are still open questions. The abstract does not specify the exact benchmarks, the size of the accuracy gains, or how broadly the method transfers beyond Qwen3-VL. It also does not tell us whether the module adds latency, how it behaves under different prompting styles, or how it interacts with other LVLM architectures.
So the right takeaway is measured: PVM looks like a targeted fix for a specific but important failure mode in LVLMs, and the paper claims encouraging results. But the source material only supports a high-level read, not a full production recommendation.
For practitioners, that makes it worth watching if you care about long-context multimodal reliability. The main idea is simple and useful: when the text gets long, don’t let the image disappear from the model’s decision path.
Bottom line
PVM is a small architectural bet on a big problem: keeping visual perception persistent during deep generation. The paper argues that LVLMs lose visual focus as output length increases, and that a parallel memory path can help restore it.
Even without benchmark numbers in the abstract, the contribution is easy to understand. It is a reminder that multimodal models can fail not because they never saw the image, but because they gradually stop using it.
// Related Articles
- [RSCH]
How VLMs Learned Complex Scene Descriptions
- [RSCH]
Visual Pretraining Beats Text-Only in Language Models
- [RSCH]
PHINN-EEG brings topology to dream-state EEG
- [RSCH]
Google’s Android Bench update exposes Gemini’s gap
- [RSCH]
Benchmarks should not pick your LLM in 2026
- [RSCH]
Rust Breaks Into TIOBE’s Top 10