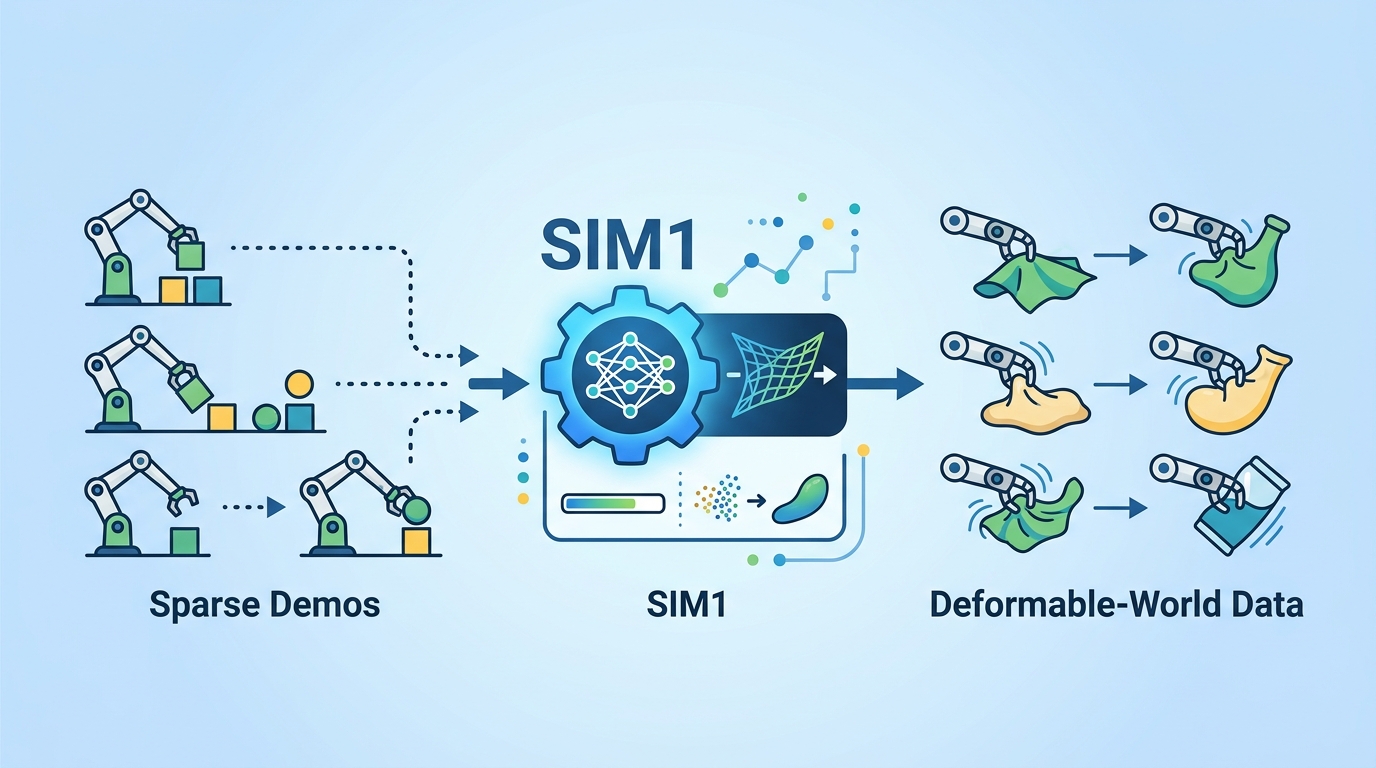
SIM1 turns sparse demos into deformable-world data
SIM1 grounds deformable-object simulation in real scenes, then scales sparse demos into synthetic training data for data-efficient robot policy learning.
Deformable-object manipulation is one of the hardest corners of robotics because shape, contact, and topology all change together. The paper SIM1: Physics-Aligned Simulator as Zero-Shot Data Scaler in Deformable Worlds argues that the problem is not simulation itself, but simulation that is not grounded in the physical world.
That matters for engineers because cloth, soft materials, and other deformable objects are exactly where real-world data is expensive and rigid-body assumptions break down. SIM1 tries to make simulation useful again by turning a small number of demonstrations into a much larger synthetic dataset that still behaves like the real scene.
What problem SIM1 is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
Traditional sim-to-real pipelines are built around rigid-body abstractions. That works reasonably well for objects whose geometry and dynamics stay stable, but deformable manipulation is different: the object changes shape, contact conditions shift constantly, and topology can evolve during interaction.
The abstract is blunt about the failure mode: existing pipelines produce mismatched geometry, fragile soft dynamics, and motion primitives that are poorly suited for cloth interaction. In other words, the simulator may be synthetic, but it is not aligned with the physics of the task the policy will face in the real world.
SIM1 is designed as a real-to-sim-to-real data engine. The goal is not just to simulate more, but to simulate in a way that preserves the physical structure of the original scene so the synthetic data can actually stand in for real supervision.
How the method works in plain English
The pipeline starts from limited real demonstrations and digitizes the scene into a metric-consistent twin. That phrase matters: the simulator is not just visually similar, it is intended to preserve real-world scale and geometry so the downstream policy is trained on something that matches the original environment.
Next, SIM1 calibrates deformable dynamics through elastic modeling. The abstract does not dive into the exact solver details, but the intent is clear: instead of relying on generic soft-body behavior, the system tunes the deformation model to better reflect the physical properties of the observed object.
After that, SIM1 expands the behavior space using diffusion-based trajectory generation. Those generated trajectories are then passed through quality filtering, which suggests the system is not blindly accepting every synthetic rollout. It is trying to keep only trajectories that stay close to the fidelity of the demonstrations.
Put together, the method turns sparse observations into scaled synthetic supervision with near-demonstration fidelity. That is the core idea: use a physics-aligned simulator as a data multiplier, not as a replacement for real-world grounding.
What the paper actually shows
The abstract reports several concrete outcomes. First, policies trained on purely synthetic data reach parity with real-data baselines at a 1:15 equivalence ratio. In practical terms, the paper claims that one unit of real demonstration can be matched by fifteen units of synthetic data generated through SIM1.
Second, the system reports 90% zero-shot success in real-world deployment. That is the strongest signal in the abstract because it suggests the policy can transfer to the physical world without additional task-specific fine-tuning at deployment time.
Third, the paper claims 50% generalization gains in real-world deployment. The abstract does not specify the exact benchmark setup, task suite, or baseline definitions, so those details are not available here. What is available is the direction of the result: the physics-aligned synthetic pipeline improved transfer and generalization over the comparison method.
What the abstract does not provide is just as important. It does not list per-task benchmark numbers, environment names, ablation results, or failure cases. It also does not give implementation specifics for the elastic model, the diffusion generator, or the quality filter. So while the headline numbers are promising, the public summary alone is not enough to judge how broad or reproducible the gains are.
Why developers should care
If you build robot learning systems, the practical pain point is data. Deformable manipulation often needs many demonstrations, but collecting those demonstrations is slow, expensive, and hard to scale. SIM1 is interesting because it tries to convert a small real dataset into a much larger training set without losing the physics that matter for transfer.
That makes the paper relevant beyond cloth folding. Any pipeline that depends on expensive real interaction data can benefit from a simulator that is constrained by measured scene geometry and calibrated dynamics instead of generic synthetic behavior. The value proposition is simple: better synthetic data can reduce the amount of real data you need.
There is also a systems lesson here. The paper combines scene digitization, physics calibration, trajectory generation, and filtering into one data engine. That is a useful pattern for developers: if a simulator is going to help with real-world learning, it has to be treated as a data production pipeline with constraints, not just as a rendering environment.
Limitations and open questions
The abstract leaves several important questions unanswered. We do not know how much real demonstration data is required before SIM1 starts working well, how sensitive the method is to calibration errors, or how it behaves when the deformable object changes materially from the examples used to build the digital twin.
We also do not know how expensive the pipeline is to run. A physics-aligned simulator plus diffusion-based trajectory generation plus quality filtering may be effective, but the compute and engineering cost could be significant. For practitioners, that cost matters as much as the reported success rate.
Another open question is generality. The abstract frames the method around deformable worlds and cloth-like interaction, but it does not say how far the approach extends to other soft materials or more complex manipulation regimes. Until there are more details, it is safest to view SIM1 as a promising data-scaling approach for a specific hard class of robotics problems, not a universal replacement for real data.
Still, the main takeaway is strong: if the simulator is grounded in the physical world, synthetic data can become much more than a convenience layer. In SIM1’s framing, it becomes a scalable supervision engine for deformable manipulation, which is exactly the kind of infrastructure robotics teams have been missing.
- Problem: deformable manipulation is data-hungry and hard to simulate with rigid-body assumptions.
- Approach: build a metric-consistent digital twin, calibrate deformable physics, then expand trajectories with diffusion and filtering.
- Reported result: synthetic-only policies match real-data baselines at a 1:15 ratio, with 90% zero-shot success and 50% generalization gains.
- Caveat: the abstract does not provide benchmark breakdowns, ablations, or runtime cost.
For engineers, SIM1 is worth watching because it points to a practical way out of the real-data bottleneck: make the simulator physically honest enough that it can actually scale supervision, not just generate plausible-looking scenes.
// Related Articles
- [RSCH]
How VLMs Learned Complex Scene Descriptions
- [RSCH]
Visual Pretraining Beats Text-Only in Language Models
- [RSCH]
PHINN-EEG brings topology to dream-state EEG
- [RSCH]
Google’s Android Bench update exposes Gemini’s gap
- [RSCH]
Benchmarks should not pick your LLM in 2026
- [RSCH]
Rust Breaks Into TIOBE’s Top 10