Steerable ViT Features for Text-Guided Vision
A new vision representation lets text steer ViT features toward specific objects without giving up generic visual utility.
Most pretrained Vision Transformers are good at finding the obvious stuff in an image. That’s useful, but it also means they tend to lock onto the most salient cues and ignore the smaller or less prominent things you may actually care about. Steerable Visual Representations tackles that gap by making visual features themselves responsive to natural-language guidance.
The practical appeal is simple: you get image representations that can be directed toward a target concept with text, while still staying useful for the usual vision jobs developers expect from generic features, like retrieval, classification, and segmentation.
What problem this paper is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The paper starts from a tension in today’s visual models. Pretrained ViTs such as DINOv2 and MAE produce broadly useful image embeddings, but those embeddings are not easy to steer. If a model sees a scene with multiple objects, it will often emphasize the most salient one rather than the one you want to focus on. That is a problem if your application needs a representation of a less obvious object, a specific instance, or a concept that is not visually dominant.

One obvious alternative is to use multimodal LLMs or vision-language models and prompt them with text. But the authors point out a tradeoff: those representations become more language-centric and can lose effectiveness on generic visual tasks. In other words, you can gain steerability, but you may pay for it by weakening the visual backbone you wanted in the first place.
This paper is trying to break that tradeoff. The goal is not just to combine text and vision, but to make the visual representation itself steerable without turning it into something that only works well in a language-heavy setting.
How the method works in plain English
The core idea is to inject text into the visual encoder early, rather than fusing it only after the image has already been encoded. The paper contrasts this with the common late-fusion pattern used by many vision-language models, including CLIP, where text and image features are combined after separate encoders have done their work.
Here, the authors add lightweight cross-attention inside the layers of the visual encoder. That means the text prompt can influence how the image representation is built, not just how it is interpreted afterward. The result is a new class of visual representations whose global and local features can be steered with natural language.
In practical terms, this should be easier to think about as “promptable image features.” You are not asking a separate language model to explain the image after the fact. You are using text to guide which parts of the visual signal the encoder pays attention to while still keeping the backbone fundamentally visual.
The paper also introduces benchmarks for measuring what it calls representational steerability. That matters because steerability is easy to claim and hard to quantify. If a model can be prompted to focus on a target object, but the representation becomes worse for everything else, that is not a real win. The benchmark framing is meant to check both sides of the tradeoff.
What the paper actually shows
The abstract makes three concrete claims. First, the steerable features can focus on any desired objects in an image. Second, they do this while preserving the underlying representation quality. Third, the method matches or outperforms dedicated approaches on anomaly detection and personalized object discrimination.
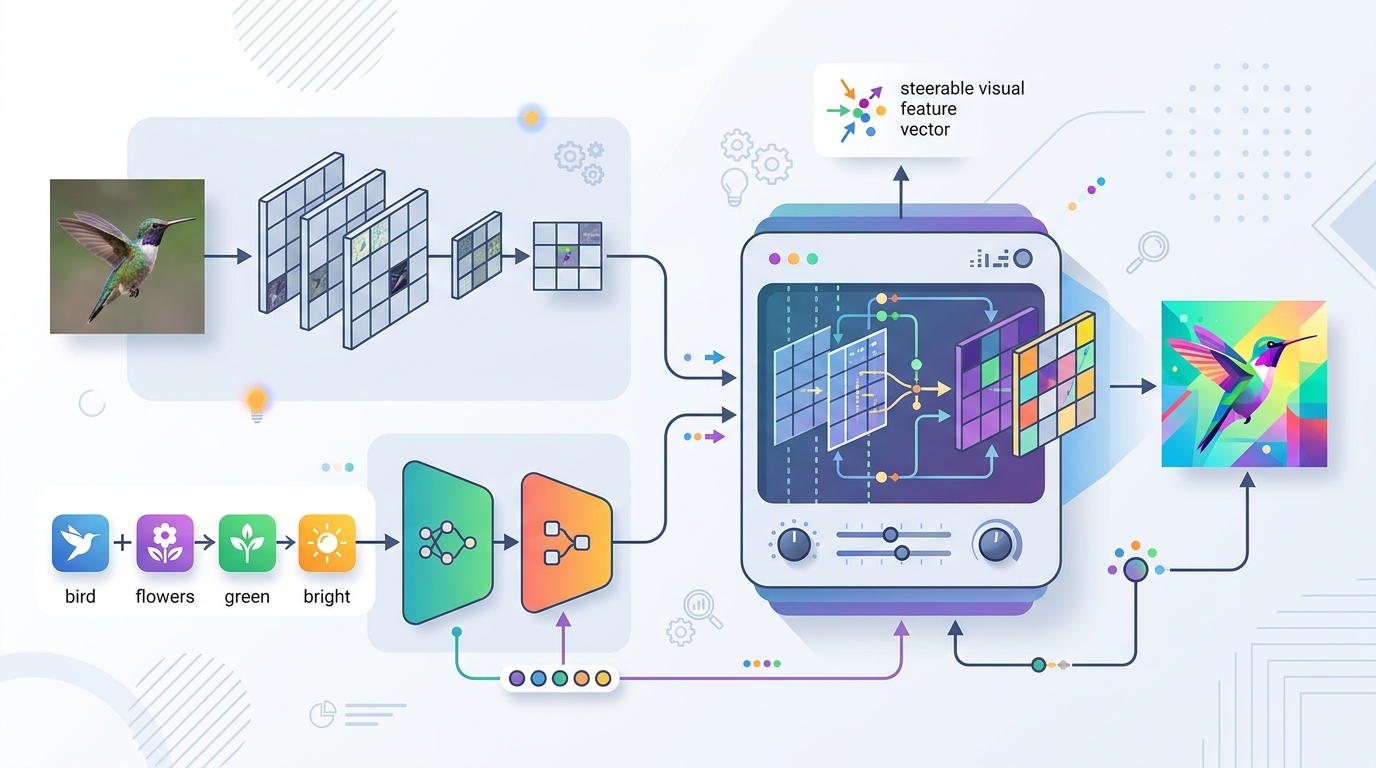
Those are meaningful results, especially because the paper says the method also shows zero-shot generalization to out-of-distribution tasks. For engineers, that is the part worth watching: a representation that can be steered by text and still transfer beyond the exact training setup is much more useful than a narrowly tuned prompt trick.
There is one important limitation in the source material: the abstract does not include concrete benchmark numbers, dataset names, or exact evaluation settings. So while the paper claims competitive or better performance, the available summary does not tell us by how much, on which splits, or under what compute budget.
That means the right way to read the result is as a directional signal, not a full performance audit. The authors are showing that early-fused text guidance can preserve the general-purpose value of visual features better than you might expect, while also enabling targeted focus and some specialized downstream uses.
Why developers should care
If you build systems that depend on image embeddings, this paper points to a new design space. Instead of choosing between generic visual features and text-guided features, you may be able to have both in one representation.
That could matter in applications like:
- retrieval systems that need to search for a specific object or attribute in cluttered scenes
- segmentation workflows where the target is described in text
- anomaly detection setups where the anomaly concept may need to be specified or adapted
- personalized object discrimination, where the object of interest depends on user context
The implementation detail that stands out is the use of lightweight cross-attention inside the visual encoder. From an engineering perspective, “lightweight” suggests the authors are trying to keep the extra guidance mechanism as small as possible instead of bolting on a heavy multimodal stack. The abstract does not provide latency, memory, or training-cost data, so you cannot assume it is cheap in practice—but the architecture direction is clearly aimed at keeping the visual backbone intact.
Another practical takeaway is that the method is meant for zero-shot generalization. If that holds up outside the paper’s reported tasks, it could make steerable features attractive for systems that need to adapt quickly without task-specific retraining.
What is still unclear
There are still open questions the abstract does not answer. We do not know how robust the steerability is across very different domains, how sensitive it is to prompt wording, or how much the cross-attention layers affect inference cost. We also do not know whether the method needs special prompt engineering to work well, or whether plain natural language is enough.
It is also unclear how the representation behaves when the text prompt is ambiguous or when multiple candidate objects match the description. Since the paper emphasizes focusing on “any desired objects,” the edge cases around disambiguation and prompt specificity will matter a lot in real deployments.
Still, the main idea is compelling: make visual features steerable without sacrificing their value as general-purpose embeddings. For developers working with image understanding pipelines, that is a promising direction because it reduces the need to choose between fixed visual features and language-driven control.
In short, this paper proposes a more flexible kind of image representation: one that can be guided by text at the feature level, not just at the output level. If the full paper backs up the abstract, it could be a useful pattern for anyone building multimodal systems that need both adaptability and strong visual utility.
// Related Articles
- [RSCH]
How VLMs Learned Complex Scene Descriptions
- [RSCH]
Visual Pretraining Beats Text-Only in Language Models
- [RSCH]
PHINN-EEG brings topology to dream-state EEG
- [RSCH]
Google’s Android Bench update exposes Gemini’s gap
- [RSCH]
Benchmarks should not pick your LLM in 2026
- [RSCH]
Rust Breaks Into TIOBE’s Top 10