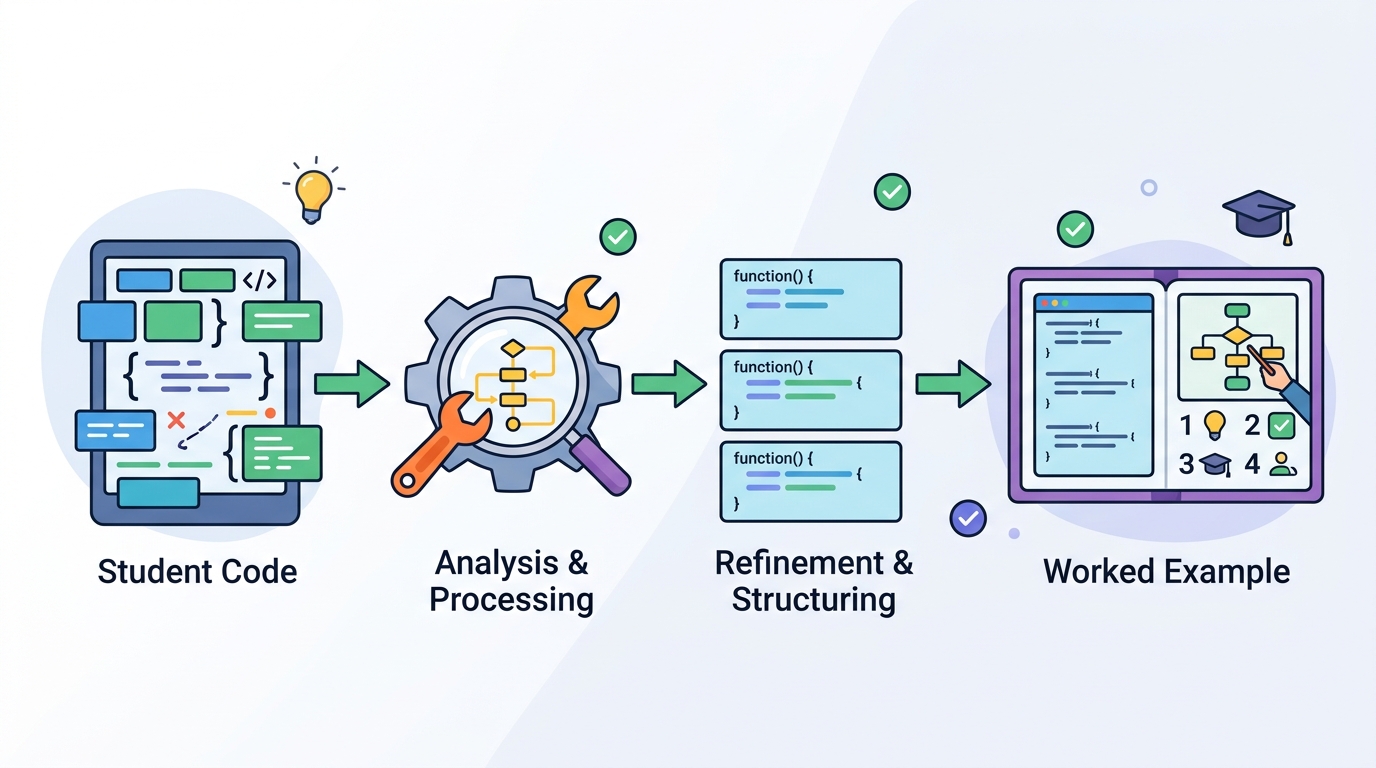
Turning student code into worked examples
A KC-guided pipeline turns student code patterns into worked examples that better match learner errors, with expert review backing the approach.

Adaptive programming practice usually depends on a fixed library of examples and exercises. That works, but it also means the material students see may not line up with the exact logical mistakes or partial solutions they are producing right now. This paper, Personalized Worked Example Generation from Student Code Submissions using Pattern-based Knowledge Components, explores a more targeted route: extract recurring patterns from student code, treat them as knowledge components, and use those signals to steer a generative model toward more relevant worked examples.
For developers building educational tools, the practical appeal is straightforward. If you can infer what kind of misunderstanding a student is showing in their code, you may be able to generate guidance that is more specific than a generic solution walkthrough. The paper is not claiming a finished product or a universal fix, but it does provide a concrete pipeline and an expert evaluation that suggests the idea is promising.
What problem this paper is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The core problem is the mismatch between static content libraries and the messy reality of student code. In programming education, instructors often rely on prewritten worked examples and practice problems. Those resources take time to author, and even a large library may not cover the exact errors students make when they are stuck on a problem.

That creates two tradeoffs. Either instructors spend more effort expanding the content library, or they accept only coarse personalization. In both cases, students may get learning material that is only loosely related to the concepts they are actually struggling with. The paper argues that this is especially limiting when the goal is to address a student’s logical errors and partial solutions directly.
The authors frame this as a knowledge-component problem: if you can identify the underlying skill or pattern represented in a student submission, you can use that signal to generate content that is more aligned with the learner’s needs. That is the gap this work is trying to close.
How the method works in plain English
The method starts with a problem statement and a set of student submissions. From there, the pipeline extracts recurring structural patterns from the code using AST-based analysis. AST here means abstract syntax tree analysis, which is a standard way to inspect code structure rather than just surface text.
Those recurring patterns are treated as pattern-based knowledge components, or KCs. In plain English, the system is trying to infer what kind of coding idea or misconception shows up repeatedly in student work. Instead of feeding the generative model only the assignment prompt, the system conditions generation on these extracted KCs.
The end goal is to produce worked examples that are personalized to the learner’s underlying code patterns. The paper applies this approach specifically to worked example generation, not to all forms of educational content. That focus matters, because worked examples are a common teaching tool and a natural place to test whether KC-based steering can improve relevance.
There is an important implementation detail here: the paper is not describing a model that magically reads intent from raw code alone. It uses structured analysis to surface patterns first, then uses those patterns as input to generation. That makes the pipeline easier to understand and more grounded than a purely free-form text generation setup.
What the paper actually shows
The paper compares baseline outputs against KC-conditioned outputs using expert evaluation. That is the main evidence reported in the abstract. The result, as described, is that KC-conditioned generation appears to improve topical focus and relevance to learners’ underlying logical errors.
That is a useful signal, but it is also worth being precise about what is and is not provided in the source material. The abstract does not include benchmark numbers, task-scale metrics, or a detailed breakdown of the evaluation results. So there are no accuracy scores, no win rates, and no numerical effect sizes to cite here.
Even without those numbers, the direction of the result is clear: the KC-conditioned version was judged to be more aligned with the student’s actual mistake patterns than the baseline. For an educational system, that matters because relevance is often the difference between a helpful explanation and a generic one that does not move the student forward.
The paper’s claim is also modest in a good way. It says the results provide evidence that KC-based steering of generative models can support personalized learning at scale. That is not the same as proving broad classroom impact, but it does suggest the approach has enough signal to justify further work.
Why developers should care
If you build learning platforms, coding tutors, or assessment tools, this paper points to a practical design pattern: combine program analysis with generation. The AST-based extraction step gives you a way to ground the model in actual student behavior instead of relying only on the assignment text or a generic rubric.
That matters because educational personalization is hard to scale manually. A library of handcrafted examples can only grow so fast, and it will always lag behind the variety of mistakes students make. A KC-guided pipeline offers a way to reuse student submissions themselves as a source of personalization signals.
There is also a broader engineering lesson here. Generative models are often more useful when they are constrained by structured context. In this paper, the structure comes from code patterns and knowledge components, which makes the generation task less open-ended and more educationally targeted.
- Use AST-based analysis to identify recurring code patterns.
- Translate those patterns into knowledge components.
- Condition generation on the KC signal, not just the prompt.
- Evaluate outputs for topical focus and relevance, not only fluency.
Limitations and open questions
The biggest limitation in the source material is that the evaluation details are thin. We know the authors used expert evaluation and found KC-conditioned outputs to be better aligned, but we do not get benchmark numbers or a full description of the study setup in the abstract. That makes it hard to judge how robust the result is across tasks, problems, or student populations.
Another open question is how well the pattern extraction generalizes. AST-based analysis is useful for structural signals, but student code can be messy, incomplete, and highly varied. The paper suggests recurring structural patterns can be extracted, but the abstract does not tell us how noisy submissions were handled or how stable the KC extraction is across different kinds of programming tasks.
There is also the usual question with generative educational tools: relevance is not the same as pedagogy. A worked example can be closely matched to a student’s error and still fail to teach well if it is unclear, overfit to one mistake, or omits the conceptual explanation the learner needs. The paper’s abstract does not go into those tradeoffs, so they remain open.
Still, the direction is promising. Instead of generating practice content from a static template library, the system uses student code itself as a personalization signal. For teams building adaptive learning systems, that is a concrete and practical idea: let the structure of student work shape the explanation they receive.
In short, this paper is less about flashy model capability and more about better conditioning. That is often where the real product value lives. If future work can show the approach holds up with larger evaluations and clearer metrics, KC-guided generation could become a useful layer in programming education tools that need to personalize at scale without hand-authoring everything.
// Related Articles
- [RSCH]
Why AI safety teams are wrong to blame only alignment
- [RSCH]
Why fine-tuning LLMs for domain tasks is the right default
- [RSCH]
RefDecoder adds reference conditioning to video decoders
- [RSCH]
ATLAS Makes Visual Reasoning Use One Token
- [RSCH]
EntityBench Tackles Long-Range Video Consistency
- [RSCH]
TurboQuant and the SEO Shift for Small Sites