ATLAS Makes Visual Reasoning Use One Token
ATLAS uses one discrete token for both agentic and latent visual reasoning, aiming to cut overhead without changing standard training.
ATLAS uses one discrete token to unify agentic and latent visual reasoning.
ATLAS: Agentic or Latent Visual Reasoning? One Word is Enough for Both is trying to solve a very practical problem: visual reasoning models can get expensive and awkward when they have to generate intermediate images, call external tools, or juggle hidden latent states. The paper argues that you should not need a separate mechanism for every style of reasoning if a single token can stand in for both an action and a latent visual operation.
For engineers, the appeal is straightforward. If the method works as described, it could reduce the amount of verbose intermediate content a model needs to produce, keep the model compatible with standard next-token prediction, and avoid some of the latency and training complexity that comes with more elaborate visual reasoning pipelines.
What problem this paper is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
Visual reasoning is increasingly about intermediate state, not just final answers. A model may need to reason through a sequence of visual transformations, inspect hidden representations, or invoke external tools before it can produce a response. The paper frames two common routes: agentic reasoning through code or tool calls, and latent reasoning through learnable hidden embeddings.
Each route has tradeoffs. Agentic methods can suffer from context-switching latency because they rely on external execution. Latent methods avoid that overhead, but the paper says they often lack task generalization and are hard to train with autoregressive parallelization. Directly generating images inside a unified model is also described as computationally expensive and architecturally non-trivial.
That combination is what ATLAS is trying to simplify. Instead of asking the model to choose between a tool call, a hidden embedding, or an image generation step, ATLAS treats a single discrete word as the shared unit of reasoning.
How ATLAS works in plain English
The core idea is a functional token: a standard token in the tokenizer vocabulary that also carries an internalized visual operation. In the paper’s framing, one token can serve as both an agentic operation and a latent visual reasoning unit.
That matters because the token is still generated through normal next-token prediction. In other words, the model does not need a special new decoding path or a separate architecture just to use these reasoning steps. The paper says this preserves compatibility with vanilla scalable supervised fine-tuning and reinforcement learning, without architectural or methodological modifications.
There is also an important training angle here. The authors say functional tokens require no visual supervision, which is a notable claim if you are thinking about how painful multimodal labeling can be. The token remains discrete, but it is associated with a visual operation internally, which is how ATLAS tries to bridge the gap between explicit action and latent state.
In practical terms, the design is meant to avoid verbose intermediate visual content generation while still letting the model do structured visual reasoning. That is the balancing act: keep the reasoning compact and trainable, but not so opaque that it becomes useless or impossible to interpret.
What the paper actually shows
The abstract says the authors ran extensive experiments and analyses, and that ATLAS achieves superior performance on challenging benchmarks while maintaining clear interpretability. That is the headline result, but the abstract does not provide the benchmark names or any numeric scores, so those details are not available from the source material here.
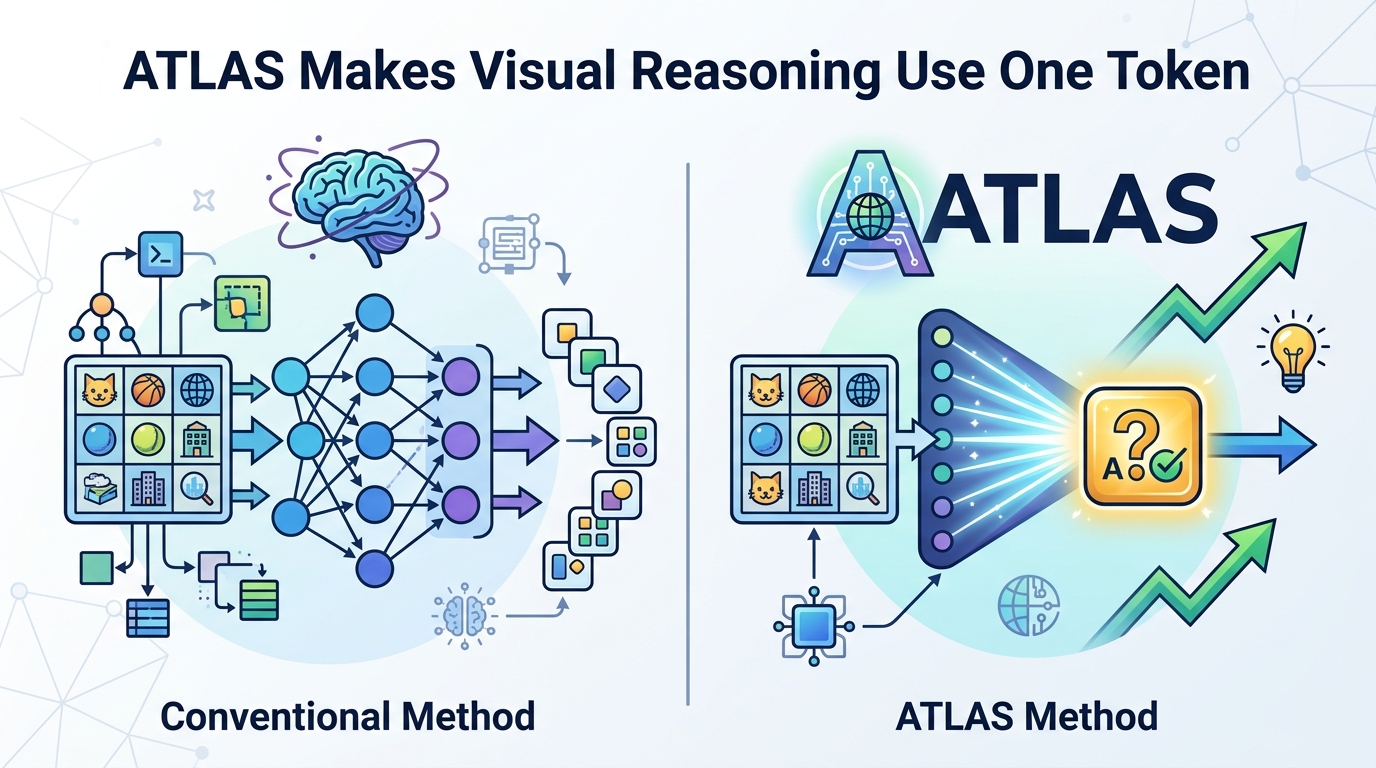
What the paper does make concrete is the training challenge around reinforcement learning. Functional tokens are described as sparse during RL, which can make them hard to optimize. To address that, the authors introduce Latent-Anchored GRPO, or LA-GRPO.
LA-GRPO stabilizes training by anchoring functional tokens with a statically weighted auxiliary objective. The goal is to provide stronger gradient updates so these special tokens do not get lost in the noise of RL. That is a useful design pattern to pay attention to if you work on sparse-action or sparse-token training problems more generally.
The paper also emphasizes interpretability. Because the functional token is still a token, the reasoning process remains more legible than a fully hidden latent pipeline. That does not mean it is fully transparent in the human sense, but it does suggest a cleaner surface for inspection than some alternative latent-only systems.
Why developers should care
If you build multimodal systems, the biggest takeaway is that ATLAS is trying to make advanced visual reasoning fit inside the normal language-model workflow. That means less architectural special-casing and, at least in principle, a path that works with standard SFT and RL setups.
There are a few practical reasons this is interesting:
- It may reduce the cost of intermediate reasoning by avoiding verbose visual outputs.
- It keeps reasoning inside the token stream, which is easier to integrate with existing LLM tooling.
- It tries to sidestep the latency of external tool execution.
- It offers a possible way to train compact reasoning steps without visual supervision.
That said, the paper is not claiming to have solved every multimodal training issue. The abstract itself points to the sparsity of functional tokens during RL as a problem severe enough to require a new auxiliary objective. That is a reminder that the approach may be elegant at the representation level while still being tricky to optimize in practice.
Another open question is generalization. The abstract explicitly says latent methods can lack task generalization, and ATLAS is positioned as a way to combine strengths while mitigating limitations. But without the full paper’s detailed benchmark breakdown, it is hard to know which tasks benefit most, where the method breaks down, or how sensitive it is to training setup.
What to watch next
ATLAS is interesting because it reframes a systems problem as a vocabulary problem. Instead of inventing a separate mechanism for every reasoning mode, the paper proposes one discrete token that can play multiple roles. That is a neat idea for anyone thinking about how far you can push token-based interfaces in multimodal models.
The real test will be whether this stays useful outside the paper’s experiments. Engineers will want to know how robust the functional tokens are across datasets, whether the interpretability holds up in messy real-world cases, and how much the LA-GRPO training trick matters when the data or task mix changes.
For now, the contribution is clear: ATLAS proposes a compact way to unify agentic and latent visual reasoning, and it does so without requiring a new model architecture. That makes it worth watching for anyone building or training multimodal reasoning systems.
// Related Articles
- [RSCH]
How VLMs Learned Complex Scene Descriptions
- [RSCH]
Visual Pretraining Beats Text-Only in Language Models
- [RSCH]
PHINN-EEG brings topology to dream-state EEG
- [RSCH]
Google’s Android Bench update exposes Gemini’s gap
- [RSCH]
Benchmarks should not pick your LLM in 2026
- [RSCH]
Rust Breaks Into TIOBE’s Top 10