Synthetic computers for long-horizon agent training
A method for building synthetic user computers at scale, then simulating month-long productivity tasks to train and evaluate agents.

This paper builds synthetic user computers and uses them to train agents on long-horizon productivity tasks.
Long-horizon productivity work is messy in exactly the way agents struggle with today: the context lives in folders, documents, spreadsheets, presentations, and the filesystem itself. The paper Synthetic Computers at Scale for Long-Horizon Productivity Simulation argues that if you want agents to improve at this kind of work, you need training environments that look and behave more like real computers, not just isolated prompts or toy tasks.
That is the core idea here: create synthetic computers with realistic directory structures and content-rich artifacts, then run agents inside them for extended simulations that resemble real productivity work. The result is not a single benchmark trick, but a pipeline for producing large volumes of experience data for agent self-improvement and agentic reinforcement learning.
What problem this paper is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The paper focuses on a practical gap in current agent training: long-horizon productivity tasks are strongly conditioned on a user’s computer environment. In real work, the relevant information is often scattered across directories and files, and the task may require navigating across multiple artifacts before anything useful can be done.

That makes synthetic data generation hard. If the environment is too shallow, agents never learn the habits that matter in practice: filesystem grounding, keeping track of context over many turns, coordinating with collaborators, and producing multiple deliverables over time. The paper is trying to scale that kind of environment-building so the training data matches the structure of actual work.
In other words, the issue is not just “can an agent answer a question?” It is “can an agent operate for a month-long project inside a computer where the evidence is spread across folders, docs, spreadsheets, and slides?” This paper is aimed directly at that problem.
How the method works in plain English
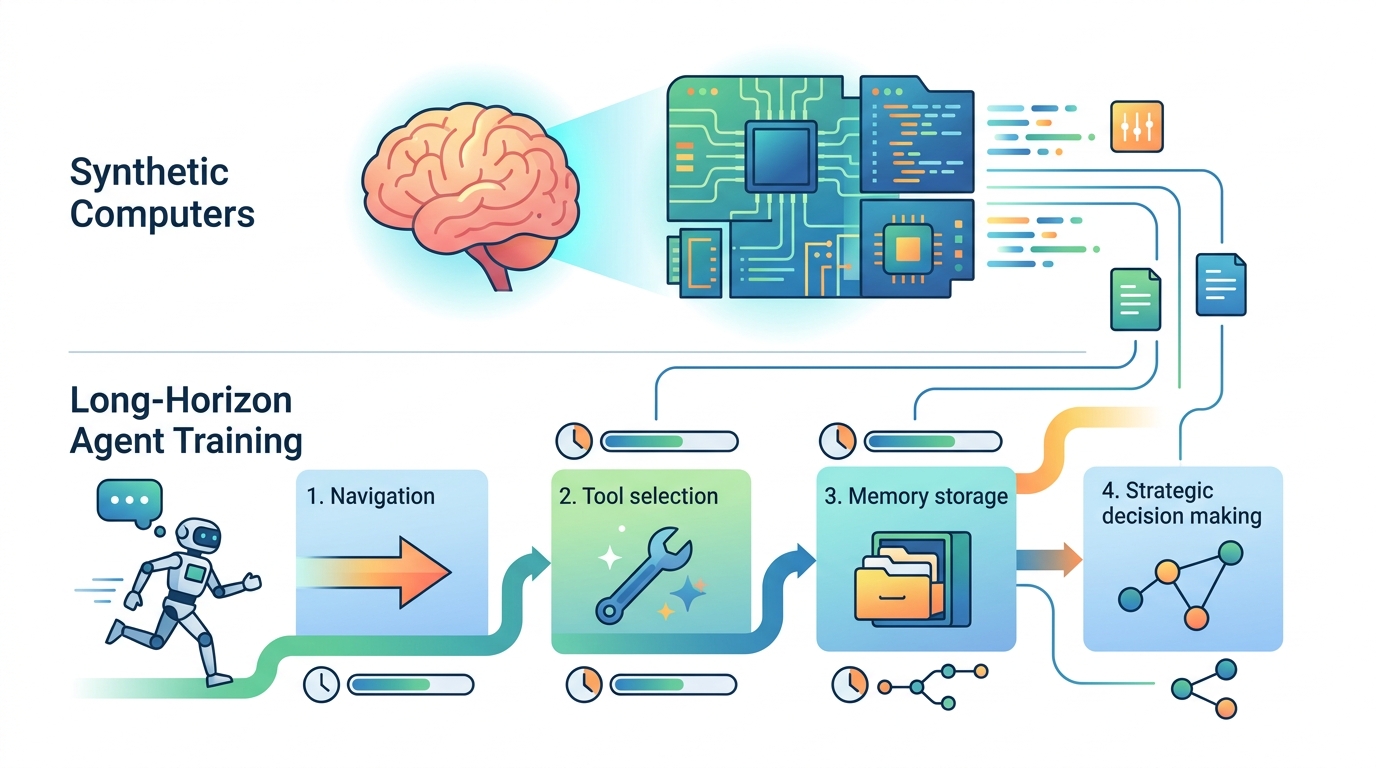
The method has two main parts. First, the authors create synthetic computers. These are user-specific environments with realistic folder hierarchies and content-rich artifacts such as documents, spreadsheets, and presentations. The point is to make the computer feel like a real work machine, at least in terms of structure and stored context.
Second, they run long-horizon simulations conditioned on each synthetic computer. One agent generates productivity objectives tailored to that synthetic user. These objectives are meant to require multiple professional deliverables and roughly a month of human work. Then another agent acts as that user and keeps working across the computer until those objectives are completed.
During the simulation, the agent does the kinds of things a real knowledge worker would do: navigate the filesystem for grounding, coordinate with simulated collaborators, and produce professional artifacts. That makes the simulation more than a static dataset. It becomes a stream of experience, with many turns and many decisions, which is exactly the kind of signal you would want for training an agent to handle extended work.
The paper positions this as a scalable methodology. Instead of hand-authoring a small number of environments, the authors aim to generate many synthetic user worlds and then let agents learn from the resulting trajectories.
What the paper actually shows
The abstract gives a few concrete numbers, and they matter. In preliminary experiments, the authors create 1,000 synthetic computers and run long-horizon simulations on them. Each run requires over 8 hours of agent runtime and spans more than 2,000 turns on average.
That is enough to show the setup is not a toy. These are long, expensive simulations with substantial interaction depth. The paper also says the simulations produce rich experiential learning signals, and that their effectiveness is validated by significant improvements in agent performance on both in-domain and out-of-domain productivity evaluations.
However, the abstract does not provide the actual benchmark names, task descriptions, or the numeric size of those improvements. So the safe reading is: the authors claim measurable gains, but the abstract alone does not let us inspect the exact evaluation protocol or compare the results against other systems in detail.
Another important detail is scale. The authors note that personas are abundant at billion scale, and argue that this approach could in principle scale to millions or even billions of synthetic user worlds if enough compute is available. That is a claim about potential capacity, not a demonstrated result, but it shows the intended direction: large-scale synthetic work environments as a training substrate.
Why developers should care
If you are building agents for office workflows, this paper points to a useful design principle: the environment is part of the training signal. A model that only sees short prompts may never learn how to use filesystem structure, multi-file context, or long-running project state. Synthetic computers try to make those capabilities trainable.
For practitioners, the appeal is straightforward. If this approach works reliably, it could help build agents that are better at sustained work across real software environments: organizing documents, tracking tasks, coordinating with collaborators, and producing deliverables over long time spans. That is a different problem from chat-style assistance, and it needs different data.
There is also a broader systems angle. Generating long-horizon traces at scale could become a foundation for self-improvement loops, where agent behavior is refined using the very kinds of workflows the agent will later need to handle. The paper explicitly frames synthetic computer creation and at-scale simulations as promising for agent self-improvement and agentic reinforcement learning in productivity scenarios.
Limitations and open questions
The biggest limitation is that the abstract gives only a high-level view. We do not get the exact construction process for the synthetic computers, the full evaluation setup, or the specific productivity benchmarks used to validate the improvements. That makes it hard to judge generality from the abstract alone.
There is also a practical cost issue. More than 8 hours of runtime per simulation is substantial, and more than 2,000 turns on average suggests heavy compute and orchestration overhead. The method may be scalable in principle, but the compute bill is part of the story.
And while the paper argues that synthetic worlds can cover diverse professions, roles, contexts, environments, and productivity needs, that remains an aspiration in the abstract rather than a demonstrated sweep across many domains. The open question is how well synthetic computers preserve the complexity and unpredictability of real work without becoming overly scripted.
- Strength: creates long-horizon, environment-rich agent training data.
- Strength: uses filesystem structure and artifacts that mirror real productivity work.
- Result: preliminary runs on 1,000 synthetic computers with over 8 hours and 2,000+ turns per run.
- Gap: the abstract does not disclose benchmark names or exact improvement numbers.
- Open question: how far this can scale in practice, and how realistic the synthetic worlds remain at larger sizes.
For engineers working on productivity agents, the main takeaway is that better agents may require better worlds, not just better models. This paper is a concrete attempt to build those worlds at scale.
// Related Articles
- [RSCH]
How VLMs Learned Complex Scene Descriptions
- [RSCH]
Visual Pretraining Beats Text-Only in Language Models
- [RSCH]
PHINN-EEG brings topology to dream-state EEG
- [RSCH]
Google’s Android Bench update exposes Gemini’s gap
- [RSCH]
Benchmarks should not pick your LLM in 2026
- [RSCH]
Rust Breaks Into TIOBE’s Top 10