Tag
KV cache
KV cache is the working memory that lets LLMs reuse past tokens during inference, and it often becomes the main limit on context length, latency, and serving cost. This tag covers quantization, compression, HBM capacity and bandwidth trade-offs, and papers like TurboQuant.
16 articles

UltraQuant: 4-bit KV caching for long agents
UltraQuant shows 4-bit KV caching can speed long, multi-turn agent serving while keeping more context resident.
Variable-Width Transformers cut wasted capacity
A new transformer design widens early and late layers while shrinking the middle to save compute and memory.

TurboQuant on AMD GPUs cuts KV-cache latency
TurboQuant on AMD GPUs improves long-context LLM serving with up to 3.6x speedup and far lower KV-cache pressure.

TurboQuant makes long-context AI much cheaper
4 ways TurboQuant’s 100x KV cache cut could lower long-context AI costs, ease GPU needs, and change model serving.
Reroute Keeps Useful Vision Tokens Alive
Reroute lets vision-language models defer, not discard, visual tokens so later layers can still use them.
TurboQuant cuts KV cache memory 6x in Google tests
Google Research says TurboQuant compresses KV caches by over 4x, with up to 6x less memory and no loss on long-context tests.
Tether’s TurboQuant cuts AI memory use 5x
Tether released TurboQuant in QVAC SDK 0.12.0, claiming up to 5x lower AI memory use for local sessions on laptops and phones.

Why Tether Is Right to Push Local AI Memory Into Everyday Devices
Tether’s TurboQuant matters because it makes long-context AI practical on local devices, not just in data centers.

VideoMLA cuts video KV cache memory 92.7%
VideoMLA compresses video diffusion KV caches with a shared low-rank latent and cuts per-token memory 92.7%.

Why Verkor’s TurboQuant silicon IP matters more than the headline says
Verkor’s TurboQuant accelerator is a real step for LLM inference, but the bigger story is how quickly algorithm ideas are becoming silicon IP.

Why llama.cpp should treat TurboQuant as the new default path
TurboQuant is the right direction for llama.cpp because asymmetric KV compression cuts memory without breaking compatibility.

Why KV-cache compression will decide edge AI inference
TurboQuant-style KV-cache compression is the real bottleneck-breaker for edge AI inference.
Why TurboQuant changes the KV cache debate
TurboQuant makes KV cache compression a theoretical win, not just an engineering trick.

TurboQuant Won’t Fix the Memory Crunch
Google’s TurboQuant can cut KV-cache memory use 6x, but longer contexts may keep DRAM and NAND demand climbing.
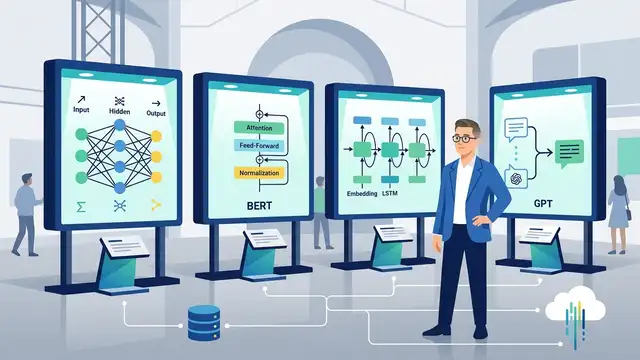
Sebastian Raschka’s LLM Architecture Gallery
Raschka’s gallery compares GPT-2, Llama 3, OLMo 2, DeepSeek, and Qwen stacks with exact layer, cache, and attention data.
Universal YOCO aims to scale depth without cache bloat
YOCO-U mixes recursive computation with efficient attention to scale LLM depth while keeping inference overhead and KV cache growth in check.