用注意力頭引導 VLM 看圖說話
研究指出,只要改動少量注意力頭,就能在不重訓下把 VLM 的描述導向指定圖像區域。

研究指出,只要改動少量注意力頭,就能在不重訓下把 VLM 的描述導向指定圖像區域。
- 研究機構:arXiv 摘要未明確標註
- 核心數據:83.1% accuracy
- 突破點:找出 gaze heads 並重導注意力
這篇〈Gaze Heads: Steering VLMs by Redirecting Attention〉在做一件很實際的事:把多模態模型裡那種「到底在看哪裡」的黑盒子,拆成可以觀察、也可以動手改的機制。作者不是只問模型會不會看圖說話,而是追問它在生成描述時,內部到底有沒有一小群注意力頭,會跟著目前正在講的圖像區域移動。
如果這個機制真的存在,意義就很直接。你不一定要重新訓練模型,也不一定要靠更長的提示詞硬拗。只要在推理階段改動那一小段注意力,模型就可能從原本會描述的區域,轉去你指定的區域。這讓「引導 VLM 看哪裡」變成一個可操作的工程問題。
這篇論文要解的痛點
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
VLM 很會講,但它怎麼決定下一句要講畫面的哪一塊,常常不透明。輸出是文字序列,輸入卻是空間影像。這種序列與空間的落差,讓除錯很麻煩。模型講錯物件、跳到別的區域、或忽略使用者想看的地方時,你很難直接指出是哪一層、哪個頭出了問題。
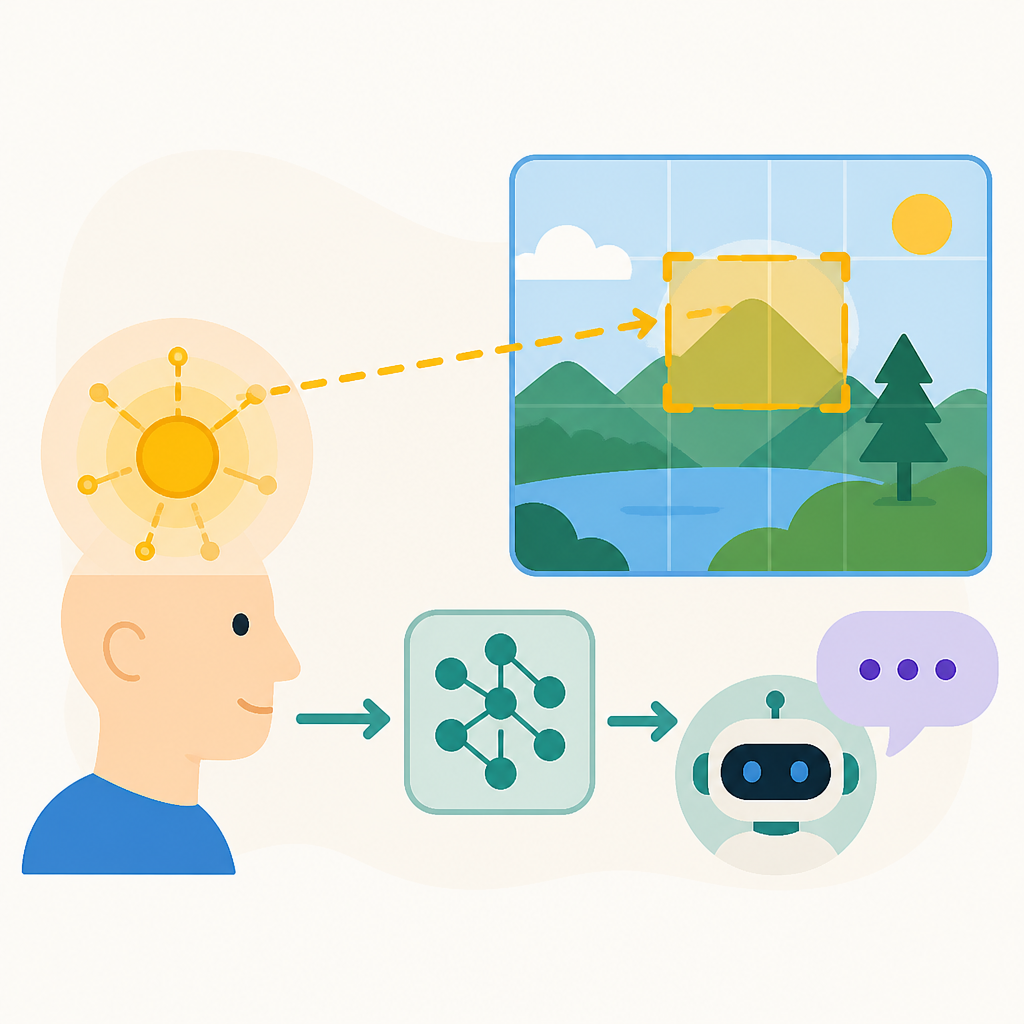
這篇論文想回答的,就是一個很機械式的問題:模型在描述圖片時,內部有沒有某個特定元件,會對應到「現在正在看哪裡」?如果有,那它就不是抽象的感覺,而是一個可以拿來控制輸出的槓桿。
作者選了 comic strips 當測試場景,這點很聰明。漫畫的敘事順序本來就有明確的空間排列,比起一般自然圖片,更容易判斷模型是不是跟著預期的 panel 走,還是中途跑偏。
方法怎麼做,白話講
核心方法其實很像在找「視線追蹤器」。作者在語言模型骨幹裡搜尋那些注意力模式,會跟當下正在描述的圖像區域一起移動的 attention heads,並把它們命名為 gaze heads。
找法也不複雜。摘要描述的是用一個簡單的 correlation score,搭配少量 forward passes 來辨識。也就是說,不需要大規模訓練,也不需要很重的 probe。重點是看哪些 head 的注意力分佈,會跟模型敘述的圖像區域同步變化。
找到之後,下一步才是驗證它是不是只是旁觀者。作者做的介入,是把這些 gaze heads 的注意力改導到指定區域。若這個機制真的在控制生成,那模型就應該開始描述被你選中的那一塊,而不是照原本的路徑走。
這裡還有一個重要對照:只動少量、目標明確的 heads 有效;把介入擴大到所有 heads 就不行。這個差異很關鍵,因為它表示效果不是單純把注意力整體弄亂,而是有一個相對特定的 circuit-level handle 可以抓。
論文實際證明了什麼
最強的結果,是作者用 top-100 的 gaze heads 做單次 attention-mask 介入。這些 heads 少於全部 heads 的 9%,卻能把模型的答案導向任一指定的 comic panel,準確率達到 83.1%。
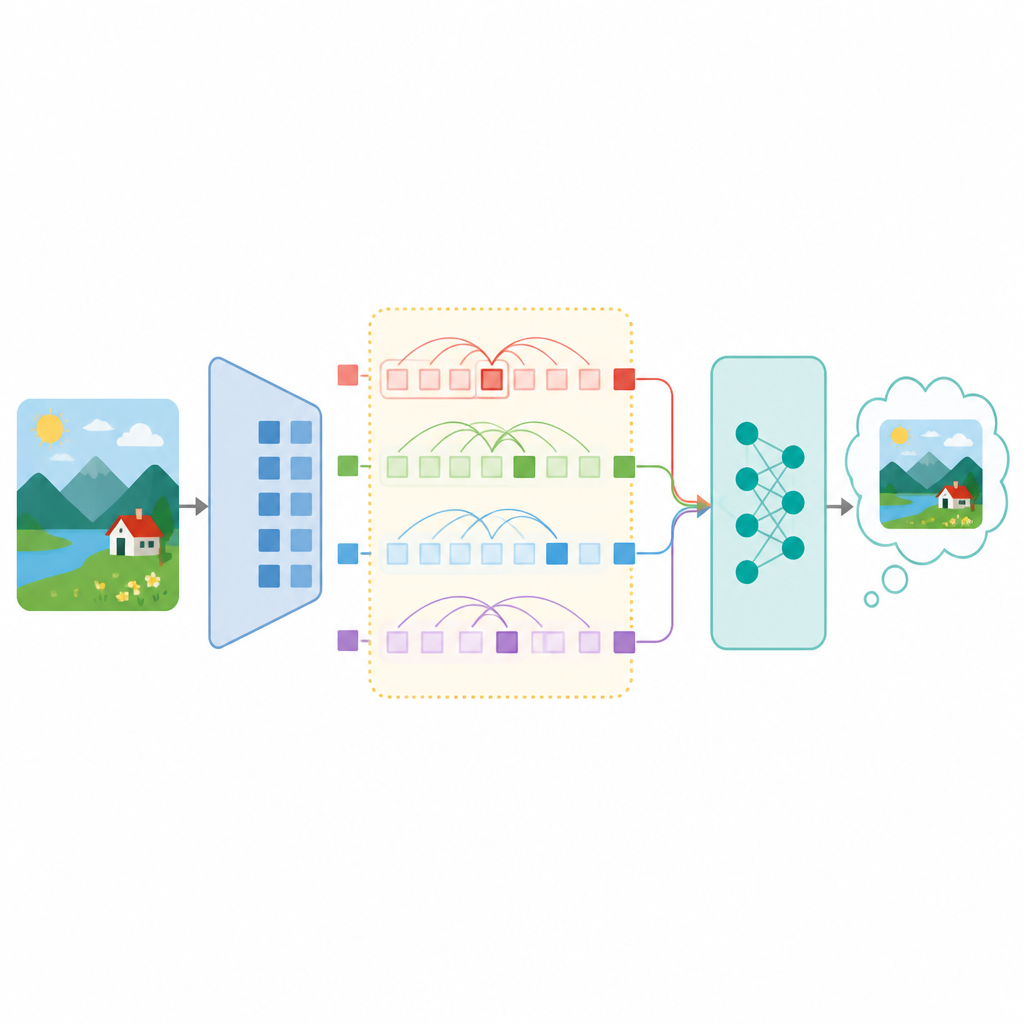
這代表什麼?代表模型的描述可以在推理時被重新導向,而且不需要碰訓練流程。你只要改動網路裡一小部分注意力,輸出就會跟著變。這不是泛泛而談的「模型能被影響」,而是具體到可以選 panel、可以量化成功率的 steering 結果。
作者也做了反例。隨機挑 heads 來改,不能把答案穩定導向目標區域;把所有 heads 一起動,反而會把生成弄壞。這個對照很重要,因為它說明有效的不是「任何 attention edit 都行」,而是「少量、對的位置才行」。
另外,這個控制不是只能做一次性的切換。摘要提到,如果在生成中途把 gaze target 換掉,模型會先把目前 panel 的描述收尾,接著在幾個 token 內轉向新的目標。也就是說,這個機制不只適合靜態 steering,也能支援動態切換。
除了漫畫,作者也把同樣的介入用在 COCO 自然圖片上,結果也能把回答導向指定區域。這把論點從「漫畫這種特殊場景可行」往前推了一步,至少顯示它不只是一個單點 demo。
摘要還提到,這個現象跨了 2B 到 32B 的模型規模,也出現在其他 VLM 架構上。不過這裡有一個明確限制:某些 frozen-encoder 家族沒有對應的 head set。換句話說,它不是被作者宣稱成「所有 VLM 都有」的通則。
這對開發者有什麼影響
如果你在做 VLM 應用,這篇論文提供的是一種新的控制面。過去多半是靠 prompt、資料、或 fine-tuning 去調模型行為;這裡則是直接在推理階段,改一小段內部注意力,就能把描述方向拉回來。
這對幾種場景特別有意思。像是除錯時,當模型老是講錯區域,你可以測試是不是某些 heads 的注意力路徑出了偏差。又或者在區域式 captioning、互動式多模態工具裡,使用者想要模型只看某個局部,這種方法就提供了一個比單純提示詞更直接的手段。
從系統角度看,這個介入被描述成簡單的 attention-mask edit,這代表它比較像是推理管線裡的一個可插拔操作,而不是重訓一整套模型。論文沒有宣稱它已經是 production-ready,但它確實展示了:多模態行為不一定只能靠訓練修,內部的小型控制點也可能夠用。
限制在哪裡
先講最直接的:這篇摘要沒有公開完整 benchmark 細節。它有給出 83.1% 這個結果,也有說明在 comic panels、COCO images、不同模型規模上觀察到的現象,但沒有把完整任務表、延遲、或更廣泛的 robustness 數據都攤出來。
第二個限制,是方法要先找得到 gaze heads 才能動手。摘要說可以用少量 forward passes 與簡單 correlation score 找出來,但這仍然依賴模型內部真的存在可辨識的模式。若某個模型家族沒有形成類似的 head set,這個 steering 手法就不一定能直接搬過去。
第三個問題是穩定性。摘要示範了中途切換 target,也提到可延伸到 COCO 圖像,但沒有主張它能在所有提示詞、所有圖像風格、或更長對話裡都穩定成立。對實務來說,這些都是後續還要補的驗證。
這篇真正重要的地方
這篇論文最有價值的,不只是「能控制模型」,而是它把一個很模糊的多模態行為,縮成一個可量測、可干預的內部機制。模型不是單純在「看圖說話」,而是可能透過少數幾個 heads,維持敘述與圖像區域的對齊。
對研究者來說,這提供了一個更具體的 mechanistic 目標。不是只說模型注意到某處,而是進一步指出:這些 heads 似乎在追蹤正在被描述的區域。對工程端來說,這也是一個新的 debug 與 steering 工具箱。
總結一句話:這篇工作證明,某些 VLM 的圖像敘述可以被少量注意力頭精準導向,而且不必重訓模型。這讓「模型到底在看哪裡」從抽象問題,變成可以直接動手處理的控制問題。
快速重點
- 少量 gaze heads 就能成為 VLM 的可控入口。
- 推理階段改 attention,比重訓更直接。
- 方法有效,但不是所有模型家族都保證有同樣結構。