SAGA makes AI agent GPU scheduling workflow-aware
SAGA argues GPU schedulers should treat an agent’s chained LLM calls as one workflow, not isolated requests.

SAGA treats an AI agent’s chained LLM calls as one schedulable workflow.
AI agents do not usually make one neat model call and stop. They often execute tens or even hundreds of chained LLM calls for a single task, and that creates a scheduling problem that current GPU cluster systems are not built to handle well. SAGA: Workflow-Atomic Scheduling for AI Agent Inference on GPU Clusters takes aim at that mismatch by arguing that agent inference should be scheduled as a workflow, not as a pile of unrelated requests.
That matters because the difference is not just academic. If a scheduler sees each LLM call in isolation, it can miss the dependencies, pacing, and end-to-end behavior of the agent that generated those calls. For developers running agentic systems at scale, that can translate into inefficient GPU use and a system that optimizes the wrong unit of work.
What problem SAGA is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The paper starts from a simple observation: AI agents are not single-shot inference jobs. They are workflows made up of many LLM calls chained together, often in the tens to hundreds per task. But most GPU schedulers still treat each call as an independent request.
That design choice is the core issue SAGA is trying to address. When the scheduler loses sight of the larger workflow, it can no longer reason about the agent’s task as a whole. The raw note does not spell out specific failure modes or metrics, but the motivation is clear: agent inference has workflow-level structure, while the scheduler is operating at call-level granularity.
For engineers, this is the kind of mismatch that tends to show up as wasted capacity, awkward prioritization, and unpredictable behavior under load. If one user’s agent is really a dependency chain of many model calls, treating those calls like independent traffic can be the wrong abstraction.
How the method works in plain English
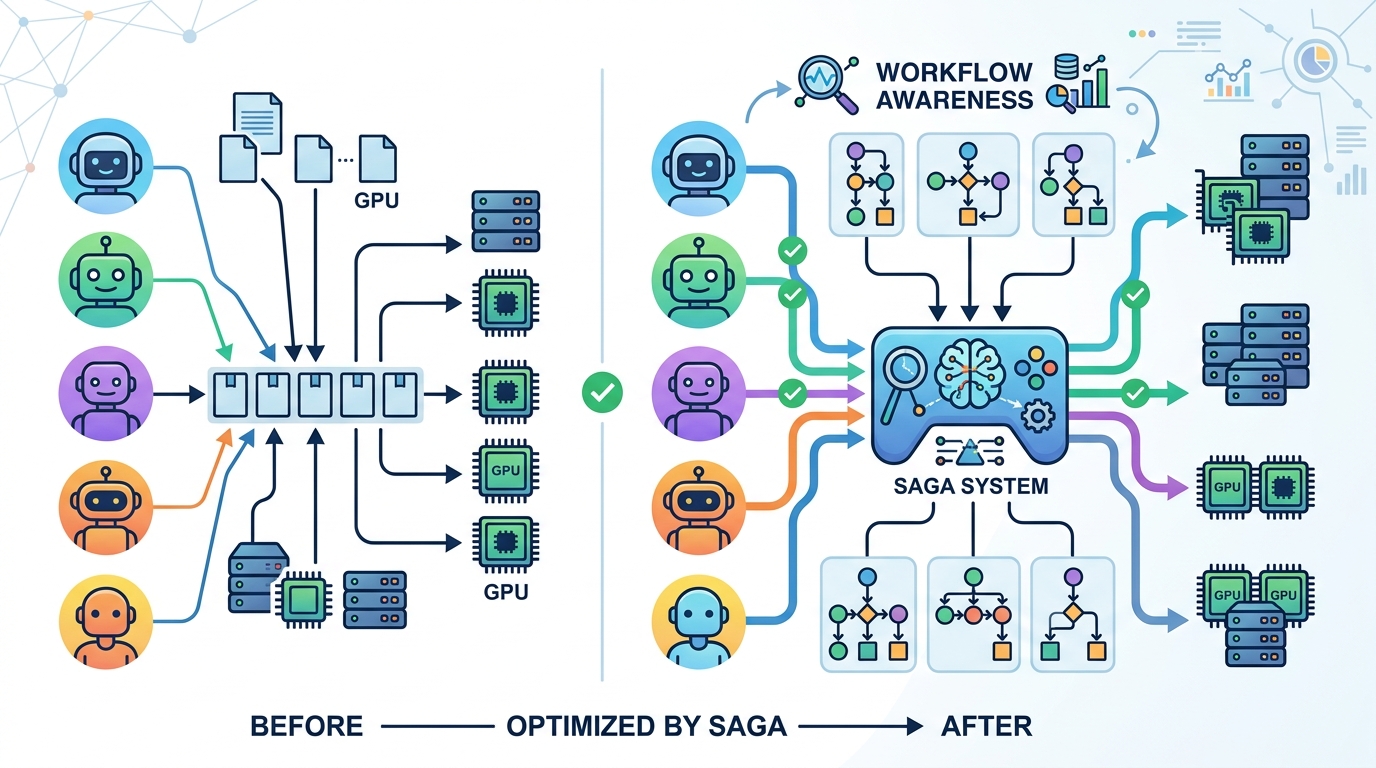
SAGA’s name gives away the main idea: workflow-atomic scheduling. In plain English, that means the scheduler should treat the whole agent workflow as the unit of scheduling, rather than splitting it into disconnected LLM calls.
The phrase “atomic” is doing a lot of work here. It suggests the scheduler should preserve the integrity of the workflow while making placement and execution decisions on GPU clusters. The raw abstract note does not provide the full algorithmic details, so we should be careful not to overstate the implementation. What is clear is the conceptual shift: instead of optimizing individual requests, SAGA tries to schedule the agent’s end-to-end inference flow.
That framing is useful because agent workloads often have internal structure that matters. A chain of calls may have dependencies, ordering constraints, or latency sensitivity across the whole task. If the scheduler understands the workflow as a unit, it can potentially make decisions that better match the real workload shape.
What the paper actually shows
From the material provided here, the paper’s abstract does not include benchmark numbers, latency figures, throughput gains, or any other concrete evaluation metrics. So there is no basis to claim measured improvements.
What we can say is narrower but still important: the paper identifies a specific systems gap and proposes a scheduling model built around workflow atomicity. That alone is useful because it reframes agent inference as a systems problem, not just an LLM orchestration problem.
In other words, the paper’s contribution appears to be architectural and conceptual: it argues that the right scheduling unit for AI agent inference is the workflow, not the individual model call. Whether that idea translates into better GPU utilization, lower tail latency, or improved fairness is not something the provided abstract text lets us verify.
That limitation matters. Without benchmark details, readers should treat SAGA as a scheduling proposal with a clear problem statement, not as a proven performance win. If you need hard numbers before changing infrastructure, this source does not give them yet.
Why developers should care
If you are building agentic systems, this paper points at a real architectural tension. The application layer thinks in tasks, plans, and tool-using workflows. The infrastructure layer often thinks in requests, batches, and isolated inference calls. SAGA argues those layers are currently misaligned.
That misalignment becomes more painful as agents get more complex. A system that makes tens or hundreds of chained calls per task can stress schedulers that were designed for simpler inference patterns. Even if your current setup works, the paper suggests that scaling agent workloads may require a different scheduling model.
For cluster operators, the practical takeaway is to start asking whether your scheduler understands the structure of agent traffic or just the raw volume of model calls. For platform engineers, the question becomes whether your orchestration layer preserves workflow context well enough for the GPU scheduler to make sensible decisions.
Limitations and open questions
The biggest limitation in the source material is that it does not expose the detailed method, evaluation setup, or results. We do not know from the abstract note how SAGA defines workflow atomicity in implementation terms, what scheduling policies it uses, or what workloads it was tested on.
There are also open systems questions that the paper title raises but the provided abstract does not answer. For example:
- How does the scheduler identify or track an agent workflow across many calls?
- Does workflow-atomic scheduling help throughput, latency, fairness, or all three?
- What happens when many workflows compete for the same GPU cluster resources?
- How much coordination overhead does a workflow-aware scheduler introduce?
Those are the questions practitioners should look for in the full paper. The abstract note gives a strong signal about the direction of the work, but not enough evidence to claim production readiness.
Still, the core idea is worth paying attention to. As AI agents become more common, infrastructure teams will need scheduling models that reflect how these systems actually behave. SAGA is a reminder that the unit of optimization matters, and for agent inference, the right unit may be the whole workflow.
// Related Articles
- [RSCH]
How VLMs Learned Complex Scene Descriptions
- [RSCH]
Visual Pretraining Beats Text-Only in Language Models
- [RSCH]
PHINN-EEG brings topology to dream-state EEG
- [RSCH]
Google’s Android Bench update exposes Gemini’s gap
- [RSCH]
Benchmarks should not pick your LLM in 2026
- [RSCH]
Rust Breaks Into TIOBE’s Top 10