為什麼分散式運算已是預設,而非例外
分散式運算已經是現代系統的預設架構,因為它更能擴充、維持可用性,也更符合真實世界的負載與故障條件。
分散式運算已經是現代系統的預設架構,因為它更能擴充、維持可用性,也更符合真實世界的負載與故障條件。
分散式運算不是進階選項,而是任何想長大、想活下來的系統的基本盤。AWS 對分散式系統的定義很直接:多台電腦一起解決同一個問題,而它的價值也早就落在真實場景裡,像行動 App、金融交易平台、以及大規模科學模擬。重點不是分散式系統很強,而是單機思維一碰到流量暴增、資料變大、或可用性要求,就會立刻失效。
第一個論點:擴充能力決定架構
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
選擇分散式運算的第一個理由很簡單,就是容量。AWS 把可擴充性定義得很清楚:當工作量增加時,可以加節點應對。這才是面對不會乖乖排隊的流量時,真正可行的答案。零售 App 不會配合你安排黑五流量高峰,影音處理管線也不會因為單一伺服器快撐不住就自動慢下來。分散式架構把容量變成可以加的東西,而不是只能事先猜對的東西。

這件事的重要性在於,過度配置是浪費,不足配置是故障。AWS 也把效率列為分散式系統的優點,原因很現實:分散式系統能更有效使用硬體,避免昂貴的閒置資源。實務上,這就是為什麼雲原生團隊偏好叢集、服務群組、彈性資料庫,而不是一台超大主機硬扛所有需求。架構應該跟著需求走,不是逼需求去遷就機器。
第二個論點:可用性不是加分,是底線
分散式系統真正贏的地方,是它能在部分元件失效時繼續運作。AWS 把可用性與容錯列為核心優勢:如果一台電腦掛了,整個系統不必跟著倒。這不是理論上的好處,而是服務能撐過節點故障,還是把一次常見事故變成客戶可見災難的差別。對使用者來說,服務是否「還在」比它是不是優雅更重要。
同樣的邏輯,也解釋了為什麼一致性與透明性這麼關鍵。AWS 指出,分散式系統會在多台機器之間複製資料、管理一致性,同時仍向使用者呈現成一台電腦。這就是這個模型最實用的地方:使用者不需要知道是哪台伺服器回應請求,工程團隊也能在不改變產品心智模型的前提下調整各個元件。故障被系統吸收在幕後,這才叫可用性。
反方可能怎麼說
反對分散式運算最強的理由,是它確實更複雜。機器越多,網路跳點越多,故障模式越多,運維成本也越高。這是真的。AWS 也區分了鬆耦合與緊耦合,因為如果通訊模式設計得不好,分散式系統會變得緩慢、脆弱、難以推理。比起一個設計得很差的叢集,單體系統確實比較容易除錯。
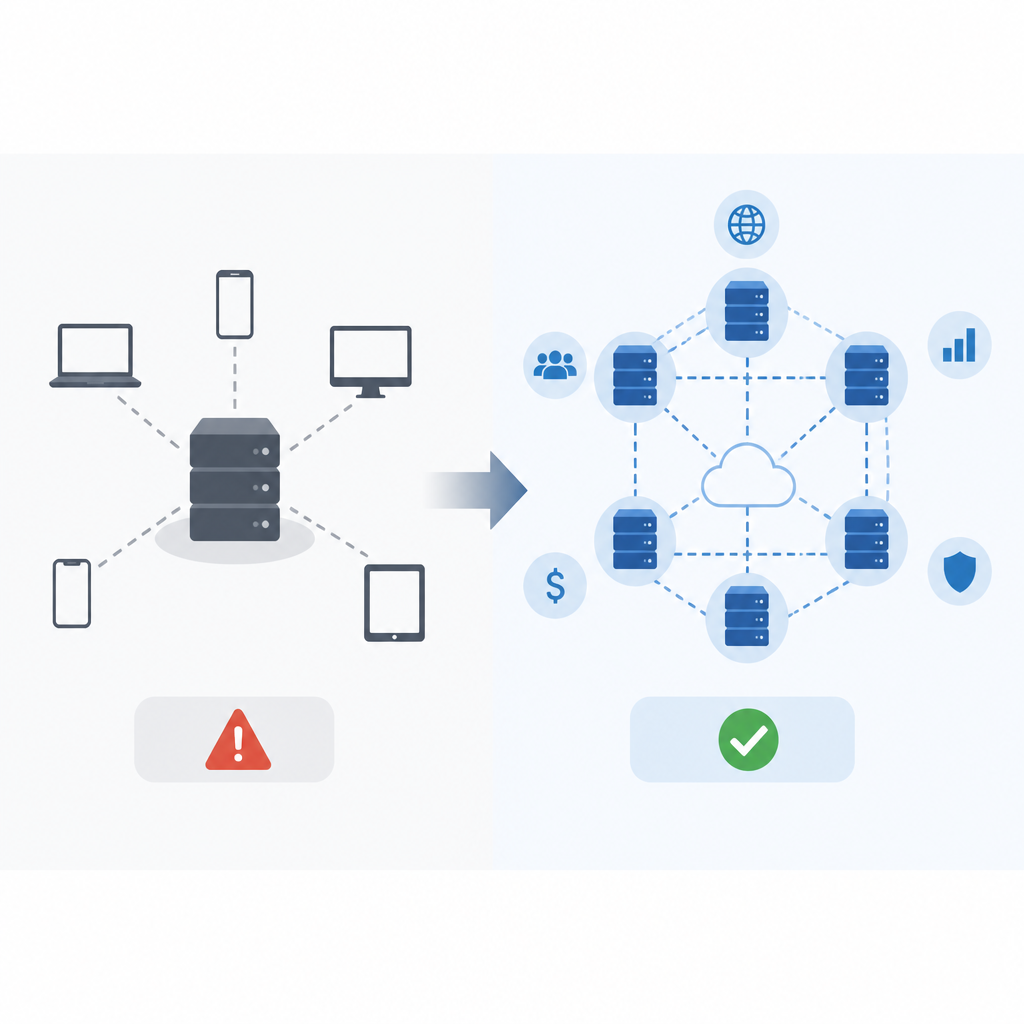
另一個現實的反對點,是效能折衷。平行運算、網格運算、客戶端伺服器、n-tier、P2P,各自解的是不同問題,不是每個工作負載都值得分散化。如果一個任務本來就能在單機完成,硬把它拆到網路上,往往只會更慢,不會更好。沒有必要為了「看起來先進」而分散工作。
但這些批評只是在劃出邊界,沒有推翻分散式運算的主張。它之所以成為主流,不是因為它比較簡單,而是因為它比較誠實地面對現實:工作量會長大,硬體會故障,使用者會要求不中斷。當這三件事同時存在時,額外的複雜度不是缺陷,而是打造能在 production 裡活下去的代價。
你能做什麼
如果你是工程師,請提早為分散式設計:把服務切開、定義清楚的通訊邊界、把失敗當成常態而不是例外。如果你是 PM 或創辦人,別再問產品「會不會有一天需要分散式系統」,而要問「不做分散式的成本,什麼時候會超過現在就做的成本」。正確做法不是把一切都分散,而是把單機簡單性保留給小而穩定的工作負載,並在擴充性、可用性、吞吐量本來就是產品承諾的地方,直接採用分散式架構。