本地微調 LLM:SFT、LoRA、DPO
LLM Configurator 第 13 篇指南更新本地微調流程,整理 SFT、LoRA、DPO 的用途、資料準備與何時該先用提示或 RAG。

LLM Configurator 第 13 篇指南整理了本地微調 LLM 的做法,重點放在 SFT、LoRA 與 DPO。
這份指南在 2026 年 6 月 15 日更新,主題很直接:什麼情況下值得訓練,什麼情況下先別急著動 GPU。它也把 LLM Configurator 的本地工作流拆成可操作步驟,並把 TRL 的 DPO、SFT 與 LoRA 放到同一張決策圖裡。
| 項目 | 數值 |
|---|---|
| Guide | 13 |
| Last updated | 2026-06-15 |
| Suggested holdout | 10% |
| Very small dataset threshold | < 50 examples |
| Typical epochs | 1–3 |
發生了什麼
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
這篇指南先把微調定位成「最後一哩」工具,而不是預設解法。它的順序很清楚:先試提示詞,再看 RAG 是否足夠,最後才考慮微調,因為很多問題其實不是模型不會,而是資料不在上下文裡。
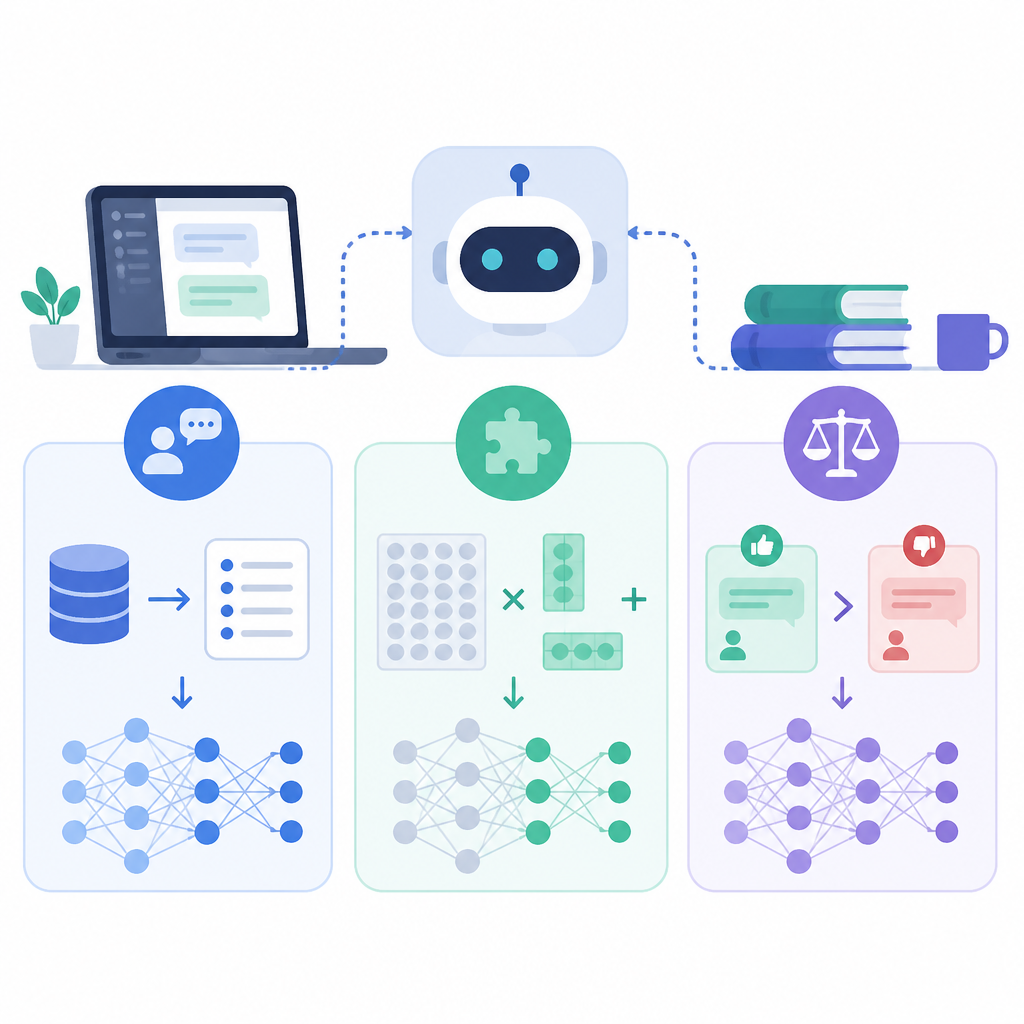
接著它把本地可做的三條路拆開講。SFT 適合拿指令與答案配對來做監督式學習,LoRA 則是用較輕的 adapter 方式減少訓練成本,DPO 則偏向用偏好資料去調整輸出傾向。
指南也補了一個實作面常被忽略的部分:資料檢查。它建議先驗證 JSONL 格式、保留 10% 作為驗證集,並盡量選擇已接近任務的 base model,因為小資料、錯格式與過度訓練,往往比模型本身更容易把專案做壞。
- SFT:適合 instruction-response 配對,最直覺。
- LoRA:適合想省算力、保留原模型權重的團隊。
- DPO:適合有偏好標註、想修正輸出風格的情境。
- LLaMA-Factory:給不想全程手寫 notebook 的團隊一條 GUI 路線。
為什麼重要
對開發者來說,這類指南最實際的價值是少走彎路。先把提示詞、RAG、微調的成本與效果分清楚,可以直接省掉不必要的 GPU 時間,也能避免把本來能用檢索解決的問題,硬拉去做訓練。
對產品團隊來說,本地微調的吸引力在於可控性。像客服回覆、資訊抽取、法務摘要或企業內部助理這些場景,常常需要固定語氣、固定格式,這時候 LoRA 或 SFT 比單純改 prompt 更穩。
這份指南也反映出一個現實:本地化訓練正在從研究題目變成工程選項。當資料量不大、場景明確、又不想把敏感資料送到雲端 API 時,團隊會更在意訓練門檻、資料品質與迭代速度,而不是只看模型分數。
真正的問題不是「要不要微調」,而是「這個任務到底缺行為,還是缺上下文」。如果答案是後者,先做提示詞和 RAG,通常比直接開訓練更快也更便宜。
對多數團隊來說,這篇指南的訊號很明確:微調不是主角,判斷順序才是主角。
補充背景
近年本地 LLM 工具鏈越來越成熟,SFT、LoRA、DPO 也因此從專業名詞變成工程團隊會碰到的日常選項。以前這些方法多半要靠研究背景才能上手,現在則有更多框架把資料格式、訓練流程與評估步驟包起來。
但工具變多,不代表每個任務都該訓練。很多團隊一開始就想調模型,實際上只是需要更好的提示模板、更多檢索內容,或更乾淨的輸入資料。
這也是這份指南的價值所在:它不是鼓勵大家一律微調,而是把「何時不該微調」講得很清楚。對小團隊來說,這種判斷往往比跑出一次漂亮的 loss 更重要。