Claude Opus 4.8 Compared With Opus 4.7
Anthropic’s latest Opus update shifts more compute into agent tasks, with longer reasoning, better tool use, and higher token spend.

Anthropic’s Claude Opus 4.8 focuses on stronger agent work, deeper reasoning, and heavier token use.
Anthropic’s latest Opus update arrives in a market where model quality is no longer judged by raw benchmark bragging rights alone. The real fight is now about agent performance, tool use, and how much useful work a model can do before it burns through your budget.
The Chinese post behind this discussion argues that the industry has moved from chasing pure intelligence to tuning models for agentic workflows. That framing matters here, because Claude Opus 4.8 is being read less as a simple IQ bump and more as a product decision about where Anthropic wants its model family to win.
| Item | What changed | Why it matters |
|---|---|---|
| Claude Opus 4.8 | More agent-focused reasoning | Better for multi-step tasks and tool use |
| Claude Opus 4.7 | Earlier Opus release | Baseline for comparison |
| Anthropic strategy | Longer thinking, more token consumption | Higher spend can mean more capable agent runs |
| OpenAI strategy | More efficient thinking with higher API pricing | Different way to monetize agent demand |
What Anthropic is optimizing for
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The core idea in the source post is simple: once agentic AI became the main battleground, top labs stopped pushing only for maximum general intelligence and started iterating around task performance. In that world, a model that reasons longer and calls tools more often can feel better in real workflows than a model that answers faster with fewer steps.

That is the lens through which Opus 4.8 should be read. The upgrade is less about a flashy new personality and more about better behavior in long, messy tasks where the model has to plan, revise, inspect outputs, and keep going without losing the thread.
- More compute spent on reasoning can improve multi-step agent tasks.
- Heavier token usage often means longer internal deliberation.
- Tool calls matter more when the model is acting like an assistant, not a chatbot.
- Anthropic’s approach appears tuned for higher-value enterprise workflows.
This is also why the comparison with OpenAI is useful. OpenAI has often pushed for more efficient thinking and then priced access accordingly, while Anthropic appears willing to let the model think longer if that makes the output better for agentic work. Different economics, different product bets.
Why token spend is part of the strategy
The source makes a blunt point that is easy to miss if you only watch benchmark charts: more thinking means more tokens, and more tokens mean more revenue. In other words, the model’s extra reasoning is not just a technical choice. It is part of the business model.
That is where Anthropic has been especially interesting. Its models are often paired with tooling that amplifies agent behavior, so the product experience can feel like a system rather than a single model call. If the model thinks longer and uses more steps, the user gets more capable automation, and Anthropic gets more usage.
“Anthropic 和 OpenAI 两家是少数可以做到鱼和熊掌兼得的。”
The quote above from the source captures the author’s view that both companies are trying to keep model quality high while also building a monetizable agent business. That is the real contest here. The winners are not just the teams with the smartest model weights, but the ones that can turn those weights into repeatable work.
For readers tracking product direction, this means Opus 4.8 should be evaluated on agent tasks, not on generic chat vibes. If it can plan better, recover from mistakes, and keep working across longer tool chains, that will matter more than a small jump in casual conversation quality.
How Opus 4.8 compares with Opus 4.7
The source does not give a benchmark sheet, so the comparison has to stay grounded in the stated direction of travel. Still, there are clear implications. Opus 4.7 was part of the earlier phase where model quality and general usefulness were the main talking points. Opus 4.8 appears to push harder on agent behavior and the infrastructure around it.
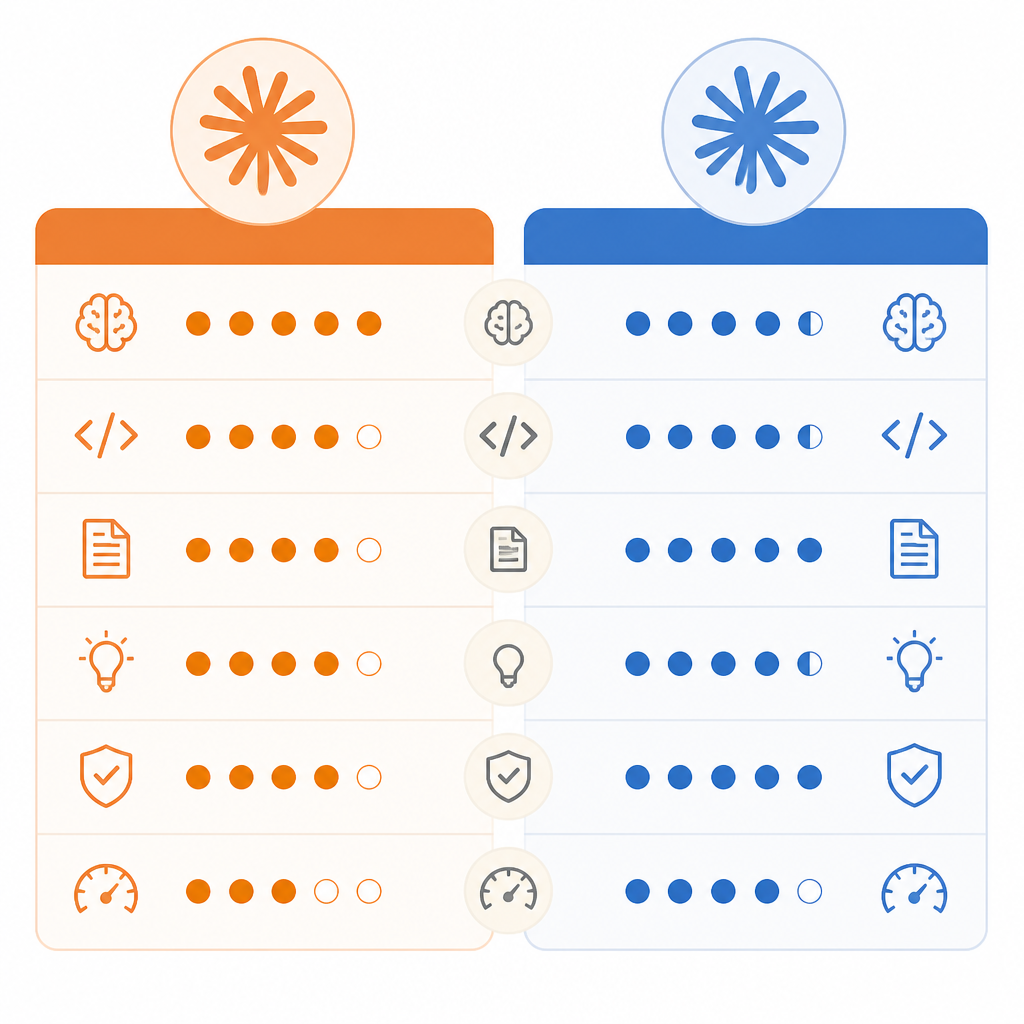
That shift shows up in practical terms:
- Opus 4.7: stronger general-purpose model, but less clearly framed around agent workflows.
- Opus 4.8: more emphasis on task completion, longer reasoning, and tool-heavy use cases.
- Opus 4.7: likely better for users who want concise output.
- Opus 4.8: better fit for workflows where correctness after multiple steps matters more than speed.
There is also a cost angle. If a model spends more tokens to reach a better answer, the bill goes up. That can be acceptable for coding agents, research assistants, and internal enterprise automation, where one good run saves real human time. It is much less attractive if you just want cheap, fast answers at scale.
Anthropic’s documentation and product positioning have increasingly pointed toward that kind of usage. The company is building for teams that want models to do work, not merely chat about work.
What this means for developers
If you build with Claude, the lesson is straightforward: test Opus 4.8 on the tasks that actually cost you time. That means code changes, multi-step research, agent loops, retrieval-heavy workflows, and cases where the model has to inspect its own output before finalizing an answer.
For developers, the most useful questions are practical ones:
- Does the model recover better after a wrong turn?
- Does it use tools more sensibly across longer tasks?
- Does the extra reasoning reduce human cleanup later?
- Does the higher token bill still make sense for the job?
If the answer is yes, then Opus 4.8 is not just an incremental version bump. It is a better fit for agent pipelines where reliability matters more than raw speed. If the answer is no, then Opus 4.7 may still be the cheaper and cleaner choice.
For a related read on how model vendors are shaping product strategy around agents, see our Claude Code coverage. The pattern is similar across the stack: models are getting judged by how much work they can finish, not how poetic they sound.
So what should you expect next?
Claude Opus 4.8 looks like another step toward models that spend more time thinking so they can finish harder jobs with less human intervention. The key question is whether that extra reasoning produces enough real-world accuracy to justify the extra cost.
My take: if Anthropic keeps improving agent reliability while preserving strong general use, Opus will keep winning developer mindshare even if it is more expensive to run. The next thing to watch is simple: do teams adopt 4.8 because it saves labor, or do they stick with 4.7 because the token bill still feels too steep?
// Related Articles
- [MODEL]
Gemini 1.5 Pro-002, Flash-002 and 2.0 Flash update Google AI
- [MODEL]
MiniMax M3 Proves Open-Weight Can Still Win on Coding
- [MODEL]
Gemini 3.5 Flash Pricing, Context, Benchmarks
- [MODEL]
Gemma 4 12B: Specs, Benchmarks & How to Run It Locally
- [MODEL]
Best Kimi Models in 2026: K2.5 vs K2 Thinking
- [MODEL]
Kimi K2.6 adds open-source coding and agent swarm